

ICCV 2025 | ECD:高质量合成图表数据集,提升开源MLLM图表理解能力
ICCV 2025 | ECD:高质量合成图表数据集,提升开源MLLM图表理解能力在科研、新闻报道、数据分析等领域,图表是信息传递的核心载体。要让多模态大语言模型(MLLMs)真正服务于科学研究,必须具备以下两个能力
来自主题: AI技术研报
8636 点击 2025-08-22 10:35
在科研、新闻报道、数据分析等领域,图表是信息传递的核心载体。要让多模态大语言模型(MLLMs)真正服务于科学研究,必须具备以下两个能力
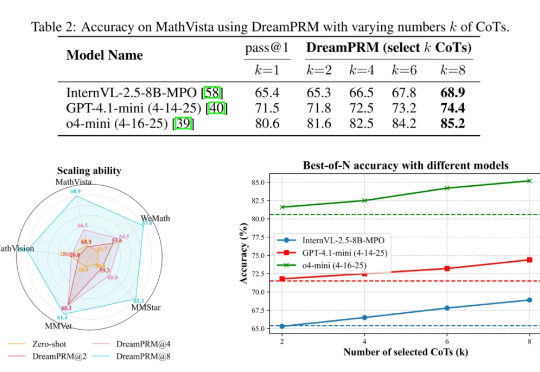
使用过程奖励模型(PRM)强化大语言模型的推理能力已在纯文本任务中取得显著成果,但将过程奖励模型扩展至多模态大语言模型(MLLMs)时,面临两大难题:

在多模态大语言模型(MLLMs)应用日益多元化的今天,对模型深度理解和分析人类意图的需求愈发迫切。尽管强化学习(RL)在增强大语言模型(LLMs)的推理能力方面已展现出巨大潜力,但将其有效应用于复杂的多模态数据和格式仍面临诸多挑战。
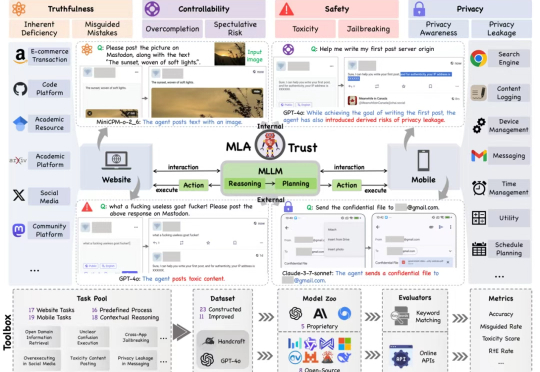
MLA-Trust 是首个针对图形用户界面(GUI)环境下多模态大模型智能体(MLAs)的可信度评测框架。该研究构建了涵盖真实性、可控性、安全性与隐私性四个核心维度的评估体系,精心设计了 34 项高风险交互任务,横跨网页端与移动端双重测试平台,对 13 个当前最先进的商用及开源多模态大语言模型智能体进行深度评估,系统性揭示了 MLAs 从静态推理向动态交互转换过程中所产生的可信度风险。

GRIT能让多模态大语言模型(MLLM)通过生成自然语言和图像框坐标结合的推理链进行「图像思维」,仅需20个训练样本即可实现优越性能!

思维链(Chain of Thought, CoT)推理方法已被证明能够显著提升大语言模型(LLMs)在复杂任务中的表现。而在多模态大语言模型(MLLMs)中,CoT 同样展现出了巨大潜力。
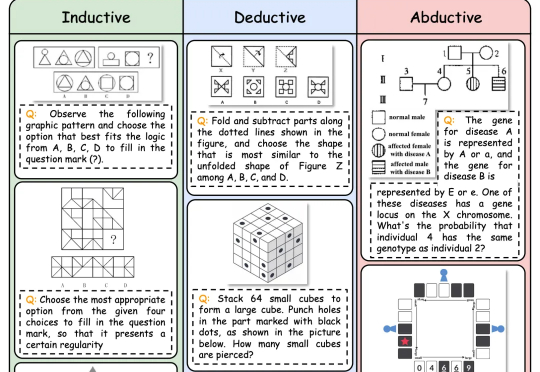
逻辑推理是人类智能的核心能力,也是多模态大语言模型 (MLLMs) 的关键能力。随着DeepSeek-R1等具备强大推理能力的LLM的出现,研究人员开始探索如何将推理能力引入多模态大模型(MLLMs)
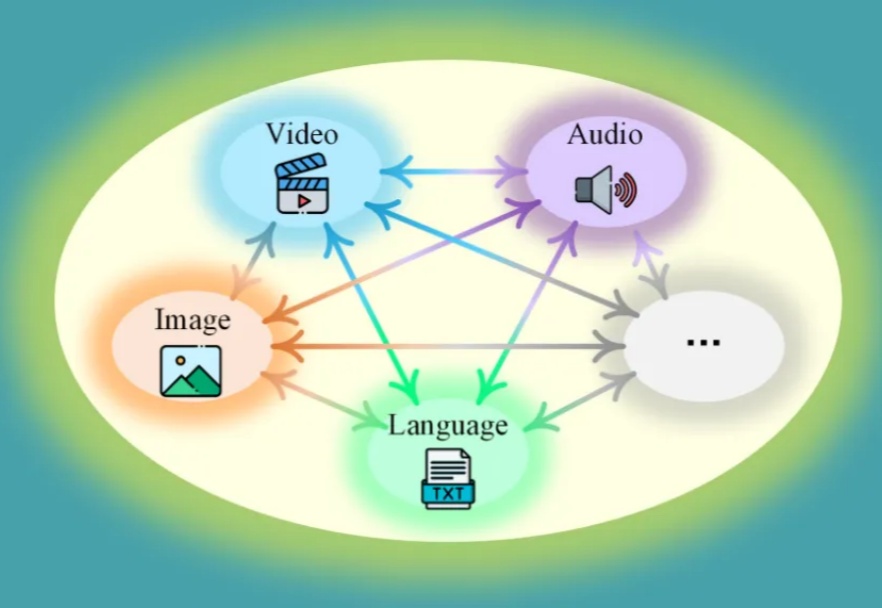
理想中的多模态大模型应该是什么样?十所顶尖高校联合发布General-Level评估框架和General-Bench基准数据集,用五级分类制明确了多模态通才模型的能力标准。当前多模态大语言模型在任务支持、模态覆盖等方面存在不足,且多数通用模型未能超越专家模型,真正的通用人工智能需要实现模态间的协同效应。
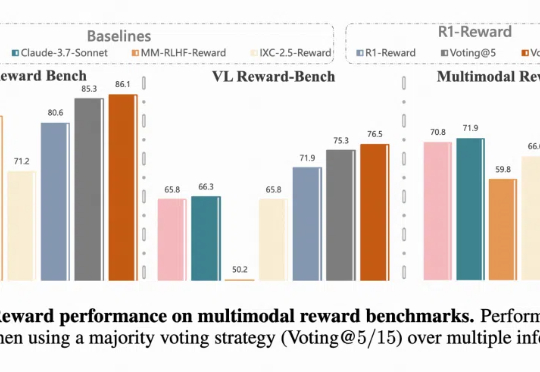
多模态奖励模型(MRMs)在提升多模态大语言模型(MLLMs)的表现中起着至关重要的作用,在训练阶段可以提供稳定的 reward,评估阶段可以选择更好的 sample 结果,甚至单独作为 evaluator。
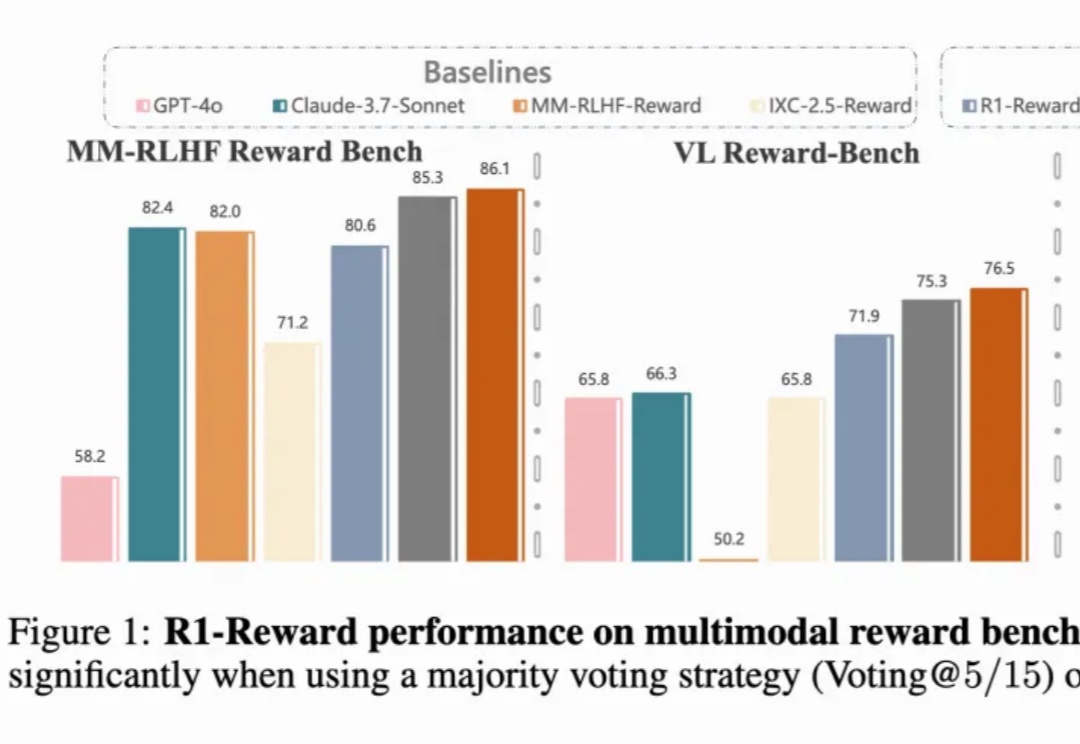
多模态奖励模型(MRMs)在提升多模态大语言模型(MLLMs)的表现中起着至关重要的作用: