清华朱军团队Nature Machine Intelligence:多模态扩散模型实现心血管信号实时全面监测
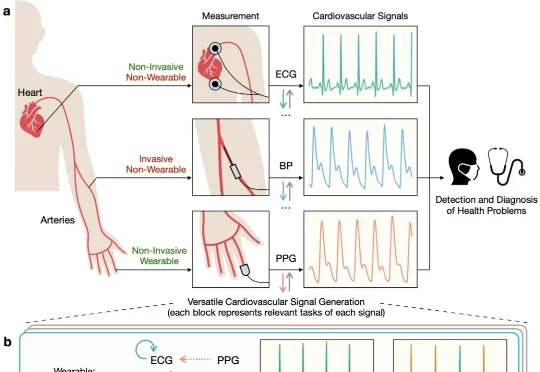
清华朱军团队Nature Machine Intelligence:多模态扩散模型实现心血管信号实时全面监测近日,清华朱军等团队提出了一种统一的多模态生成框架 UniCardio,在单扩散模型中同时实现了心血管信号的去噪、插补与跨模态生成,为真实场景下的人工智能辅助医疗提供了一种新的解决思路。
来自主题: AI技术研报
9659 点击 2025-12-30 15:14
 搜索
搜索
近日,清华朱军等团队提出了一种统一的多模态生成框架 UniCardio,在单扩散模型中同时实现了心血管信号的去噪、插补与跨模态生成,为真实场景下的人工智能辅助医疗提供了一种新的解决思路。
近段时间,已经出现了不少基于扩散模型的语言模型,而现在,基于扩散模型的视觉-语言模型(VLM)也来了,即能够联合处理视觉和文本信息的模型。今天我们介绍的这个名叫 LaViDa,继承了扩散语言模型高速且可控的优点,并在实验中取得了相当不错的表现。

普林斯顿大学与字节 Seed、北大、清华等研究团队合作提出了 MMaDA(Multimodal Large Diffusion Language Models),作为首个系统性探索扩散架构的多模态基础模型,MMaDA 通过三项核心技术突破,成功实现了文本推理、多模态理解与图像生成的统一建模。

【新智元导读】近日,来自谷歌的研究人员发布了多模态扩散模型VLOGGER,只需一张照片,和一段音频,就能直接生成人物说话的视频!