
多模态大模型首次实现像素级推理!3B参数超越72B传统模型,NeurIPS 2025收录
多模态大模型首次实现像素级推理!3B参数超越72B传统模型,NeurIPS 2025收录多模态大模型首次实现像素级推理,指代、分割、推理三大任务一网打尽!
来自主题: AI技术研报
9904 点击 2025-10-17 10:01
 搜索
搜索
多模态大模型首次实现像素级推理,指代、分割、推理三大任务一网打尽!
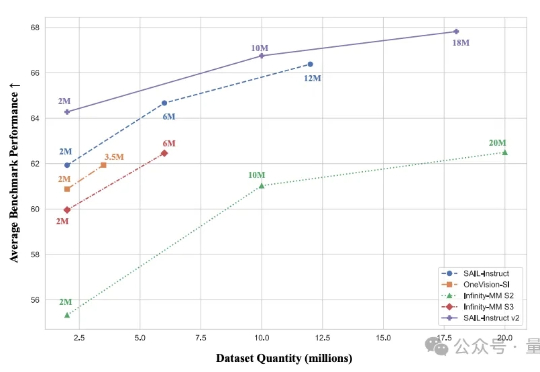
2B模型在多个基准位列4B参数以下开源第一。 抖音SAIL团队与LV-NUS Lab联合推出的多模态大模型SAIL-VL2。

奇多多AI学伴机是由无界方舟发布的国内首款基于「端到端实时多模态互动模型」的AI互动机器人,于本月2025外滩大会首次亮相。京东预售仅上线一周,销量便突破了10000台,在看似红海的儿童早教市场掀起波澜。在功能体验方面,它带来了三大突破:能“看”世界的眼睛、堪比真人的低延迟反馈速度、能“成长”的个性化陪伴感。
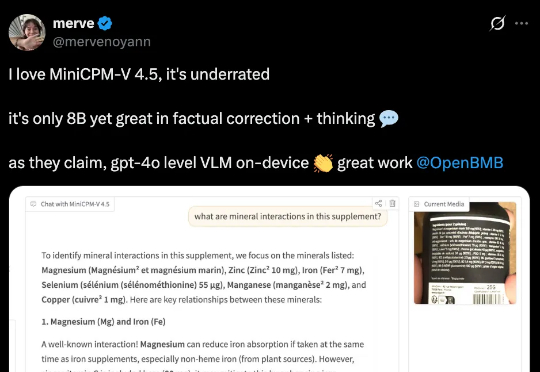
行业首个具备“高刷”视频理解能力的多模态模型MiniCPM-V 4.5的技术报告正式发布!报告提出统一的3D-Resampler架构实现高密度视频压缩、面向文档的统一OCR和知识学习范式、可控混合快速/深度思考的多模态强化学习三大技术。
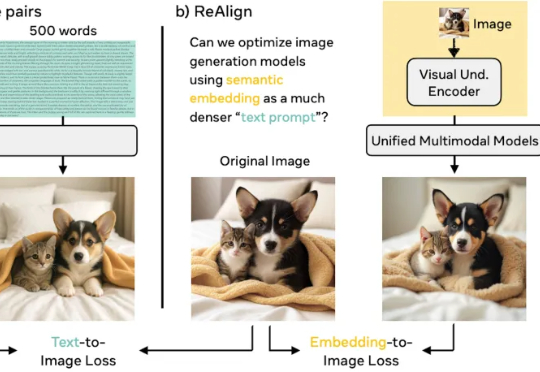
谢集,浙江大学竺可桢学院大四学生,于加州大学伯克利分校(BAIR)进行访问,研究方向为统一多模态理解生成大模型。第二作者为加州大学伯克利分校的 Trevor Darrell,第三作者为华盛顿大学的 Luke Zettlemoyer,通讯作者是 XuDong Wang, Meta GenAl Research Scientist、

今天,我们正式开源 8B 参数的面壁小钢炮 MiniCPM-V 4.5 多模态旗舰模型,成为行业首个具备“高刷”视频理解能力的多模态模型,看得准、看得快,看得长!高刷视频理解、长视频理解、OCR、文档解析能力同级 SOTA,且性能超过 Qwen2.5-VL 72B,堪称最强端侧多模态模型。

智谱基于GLM-4.5打造的开源多模态视觉推理模型GLM-4.5V,在42个公开榜单中41项夺得SOTA!其功能涵盖图像、视频、文档理解、Grounding、地图定位、空间关系推理、UI转Code等。
上上周一的晚上,智谱开源了当今最好的模型之一,GLM-4.5。 然后,这个周一,又是突如其来的,开源了他们现在最好的多模态模型: GLM-4.5v。

近日,上海人工智能独角兽阶跃星辰宣布,正在进行新一轮融资,金额预计超过5 亿美元,或成为 2025 年国内大模型行业最大单笔融资。本轮融资由上海国有资本投资有限公司(简称 “上海国投”)等战略投资方领投,资金将重点用于多模态模型研发、推理效率优化及智能终端场景落地。

让大模型在学习推理的同时学会感知。伊利诺伊大学香槟分校(UIUC)与阿里巴巴通义实验室联合推出了全新的专注于多模态推理的强化学习算法PAPO(Perception-Aware Policy Optimization)。