# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
古希腊陶器是考古学和艺术史的重要实物证据。
研究者需要从单件陶器中提取多层信息:材质与工艺、形制类别、装饰主题、出土地与时间、甚至可能的作坊或画师。
不过传统计算机视觉和通用多模态模型在这类高度专业化任务上常陷入两类困境:
一是缺乏领域知识(模型在通用语料里几乎没接触过「雅典黑釉杯」或「红绘风格」这样的概念);
二是仅靠监督微调(SFT)容易学到「表层捷径」,在遇到组合性、推理性或少样本问题时就失效。
基于此,AI Geeks、澳大利亚人工智能研究所等机构的研究人员提出:既要有专门的数据与任务划分,也要有针对性的训练策略来补弱提升。

论文链接: https://doi.org/10.48550/arXiv.2509.17191
项目地址:https://github.com/AIGeeksGroup/VaseVQA
论文的技术主线可以用一句话概括:先把模型训练到有基础能力(SFT),再通过诊断找出各类问题的薄弱环节,用类型条件化的强化学习(RL)和精细化奖励去有针对性地补弱。
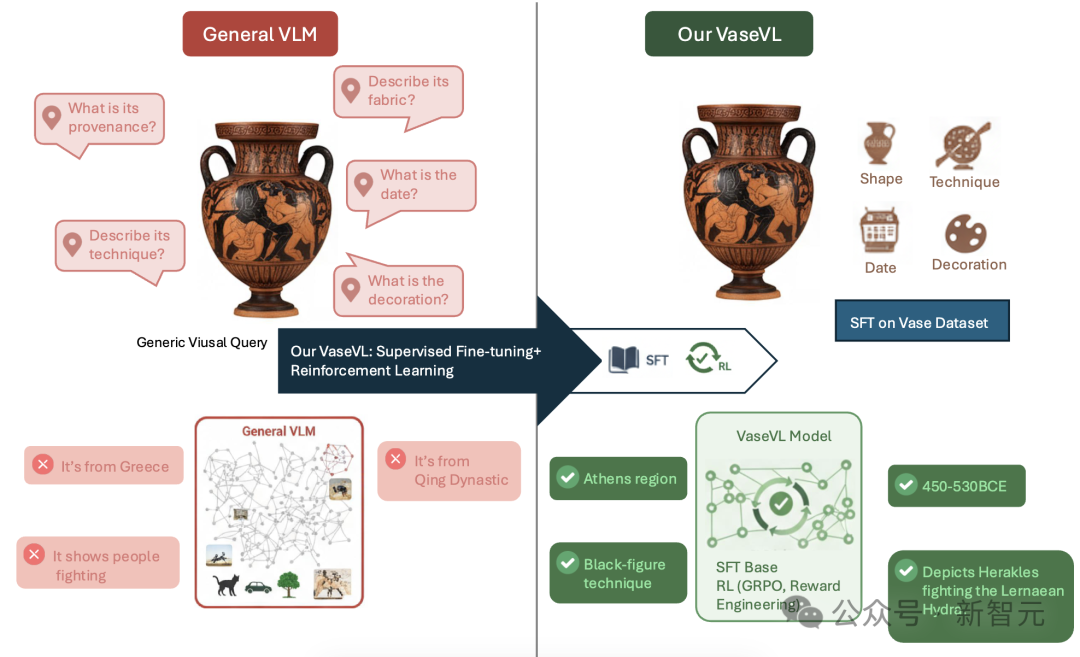
图1:现有视觉语言模型在古希腊陶瓶理解上的局限性与所提出的VaseVL框架
关键步骤如下:
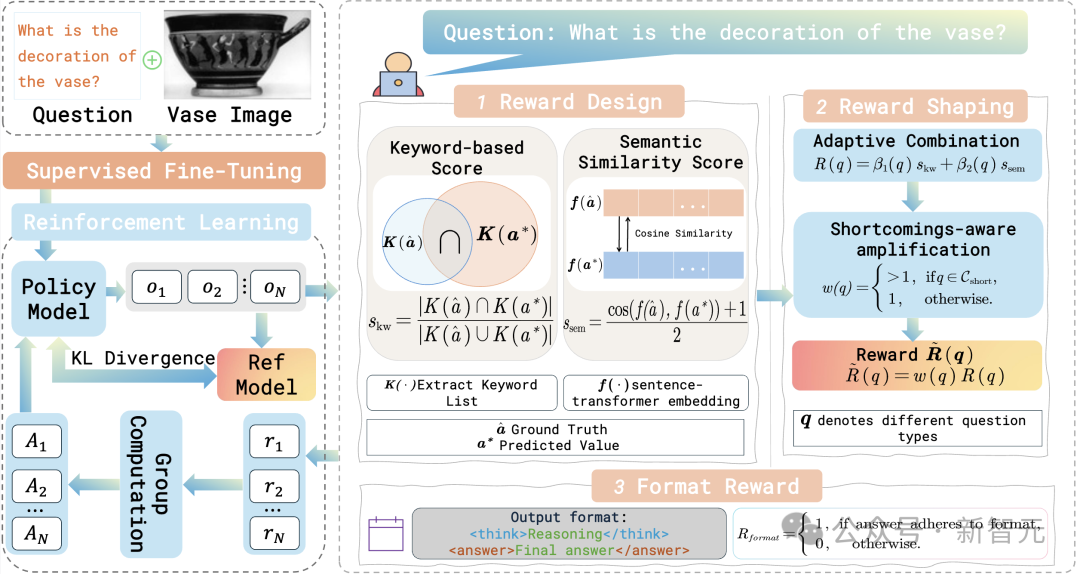
图2:VaseVL的整体框架。该方法将有监督微调(SFT)与基于组相对策略优化(GRPO)的强化学习相结合。给定陶瓶图像x、问题q 和参考答案a^*,模型通过在词汇奖励与语义奖励之间取得平衡,并限制策略偏离参考策略 ,从而提升其推理能力。
数据与基准(VaseVQA)
让评测更具信服力
为了能系统评估上述方法,研究人员同时构建了一个面向古希腊陶器的多模态问答基准(VaseVQA)。
该基准覆盖大量陶器图片与多类型问答对,且在标注上引入专家审校,力求兼顾规模与专业性。更重要的是,基准把任务按问题类型拆分,使得模型的薄弱处能被明确定位并针对性优化。
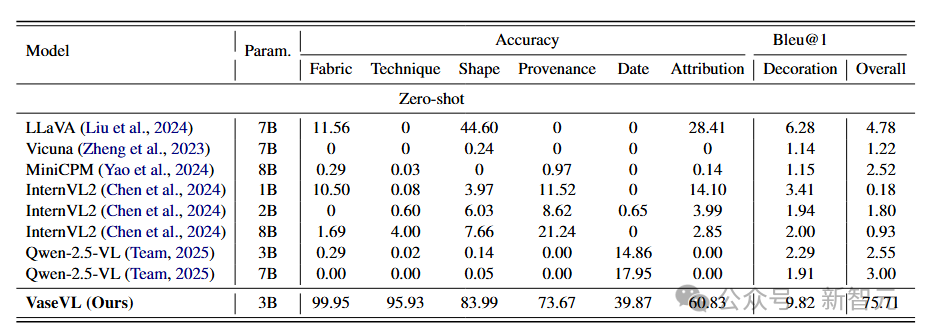
表1:VaseVQA基准测试上的性能比较。RL代表推理注入。
关键发现与实证价值
论文的实验显示:
仅做SFT能显著提升模型的基础识别能力,但在归属推理和复杂描述上仍有限;
在诊断基础上做类型条件化RL优化后,模型在那些先前薄弱的类型上有可观提升——这说明「补弱导向」的训练策略在专业垂直任务上很有效;
细粒度的评价(按问题类型)对于判断模型真实能力与设计针对性改进尤为重要。
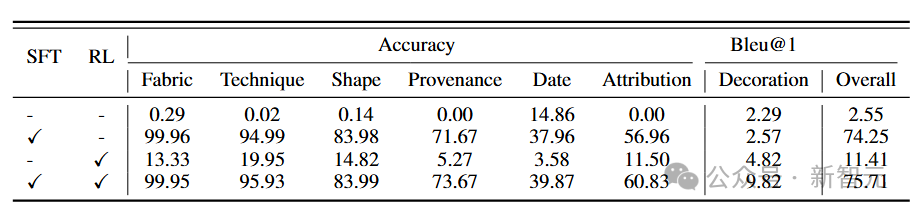
表2:消融实验结果说明。RI表示Reasoning Injection(推理注入)。Qwen2.5-VL-SFT表示前述模型经过 有监督微调(SFT) 的版本,而最后一行展示的是提出的VaseVL 模型的性能表现。
意义、局限与可推广方向
这项工作最有价值的,不只是把一个模型调好,而是提出了一套「如何让通用多模态模型在高度专业领域变得可靠」的方法论:任务分层 → 定位薄弱 → 有针对性地微调与评估。
它对文化遗产、医学影像、材料科学等其他垂直领域都有启发意义。
但需谨慎的一点是:强化学习阶段高度依赖奖励设计,若奖励不当或数据偏倚,模型可能学习到新的偏差。
此外,许多考古归属问题本身具有主观性与学术争议,模型输出仍需专家把关作为辅助工具而非最终裁决。
VaseVQA展示了把「领域诊断」嵌入多模态训练流程的可行路径。
文化遗产与AI的结合,不应仅止于表层识别,而应追求「可解释、可校验、有专家协同」的工具化落地。
未来,当这类方法被更广泛采纳,不同学科的专家与工程师协作,就能把AI打造成真正有助于保护与理解人类文化记忆的可靠伙伴。
参考资料:
https://doi.org/10.48550/arXiv.2509.17191
文章来自于微信公众号 “新智元”,作者 “新智元”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
