
大模型狂飙的尽头,这家国产 GPU 厂商要把算力放在客厅
大模型狂飙的尽头,这家国产 GPU 厂商要把算力放在客厅一个做国产 GPU 的公司,在前几天的发布会上,一口气更新了好几款端侧产品,有家庭智能中枢、AI PC、Agent,还有具身智能相关的工作。它叫 MTT AICUBE,按官方说法是「一台面向家庭的 AI 智算中枢」。
来自主题: AI资讯
8938 点击 2026-05-22 09:56
 搜索
搜索
一个做国产 GPU 的公司,在前几天的发布会上,一口气更新了好几款端侧产品,有家庭智能中枢、AI PC、Agent,还有具身智能相关的工作。它叫 MTT AICUBE,按官方说法是「一台面向家庭的 AI 智算中枢」。
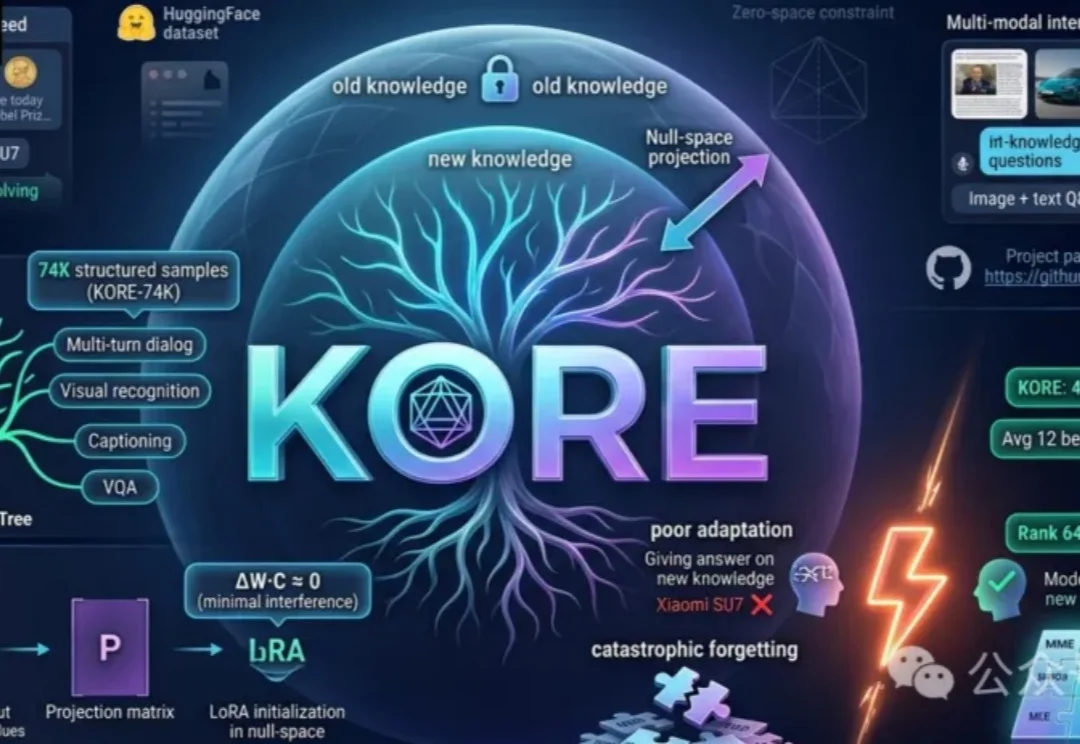
中科大团队首先推出动态多模态知识注入基准MMEVOKE,解构遗忘机制,并在此基础上提出全新双阶段框架KORE。通过「知识树」自动增强与「零空间」协方差约束微调,为大模型终身学习开辟了全新路径。

你猜一个能翻译33种语言、性能逼近顶尖闭源模型的AI,装进手机里需要多大?
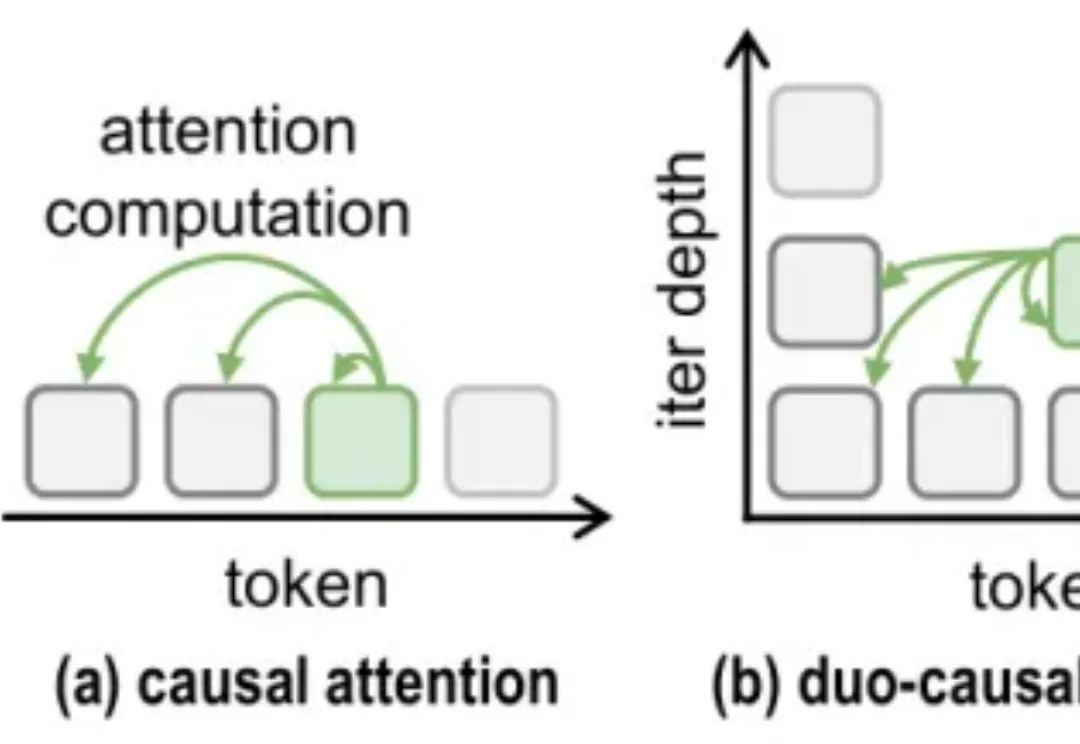
随着 o1/R1 等推理模型的发展 [1][2],「让模型多想一会儿」几乎成了提升复杂推理能力的标准方案。更长的 Chain-of-Thought、更大的测试时计算、更深的内部推理,都在用更多计算换取更可靠的答案。
让 AI 来管理代码的话,每次读 500 行反而比读 1000 行更费 Token,而且人工编排流程真不如让大模型自己定,「很多的事儿,还是很反直觉的」
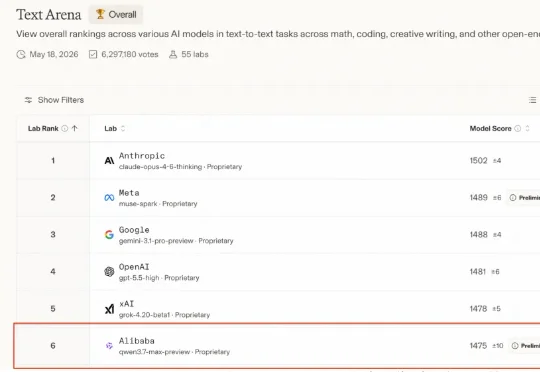
仅仅一个月后,阿里又带着最强旗舰模型杀回来了!今天上午,在 2026 阿里云峰会上,阿里全新一代千问旗舰模型 Qwen3.7-Max 登场了!在 Arena 公布的最新一期全球大模型盲测总榜中,Qwen3.7-Max 总成绩位列国产模型第一:傲视一众国产大模型
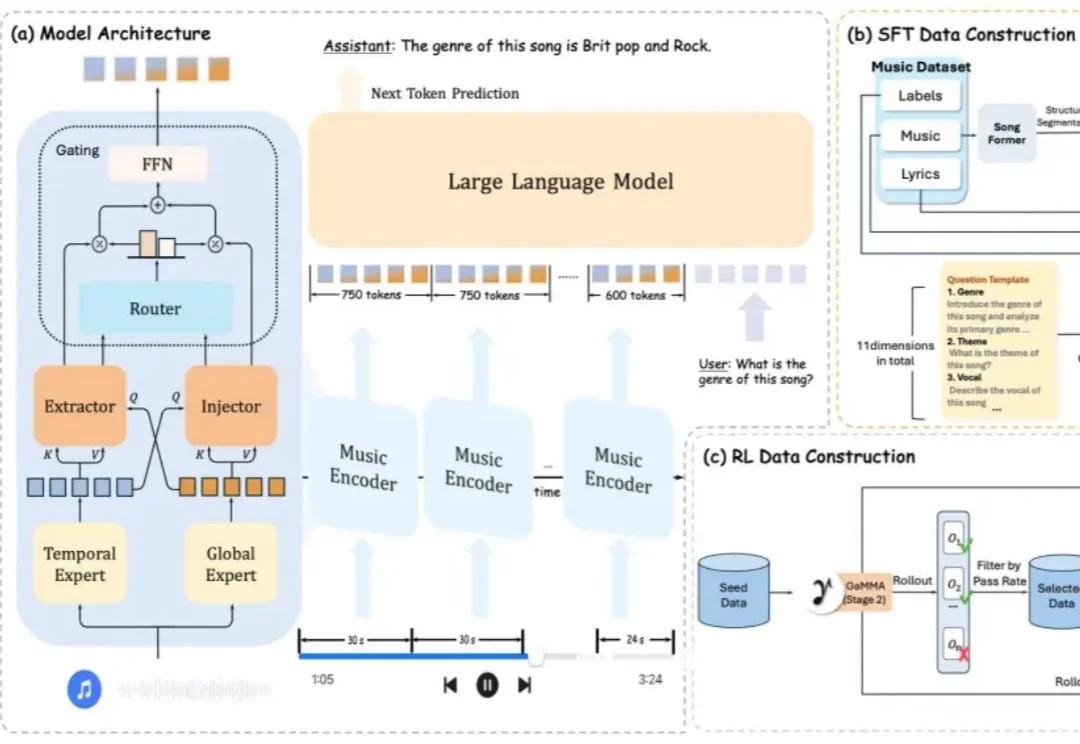
大模型的能力边界正在不断拓展,从文字到视觉,再到音频,全模态理解已渐成现实。然而,当你问一个多模态大模型「这首歌的高潮从第几秒开始?」或者「第 30 秒之后乐器编配发生了什么变化?」,得到的往往是一个模糊甚至错误的回答。
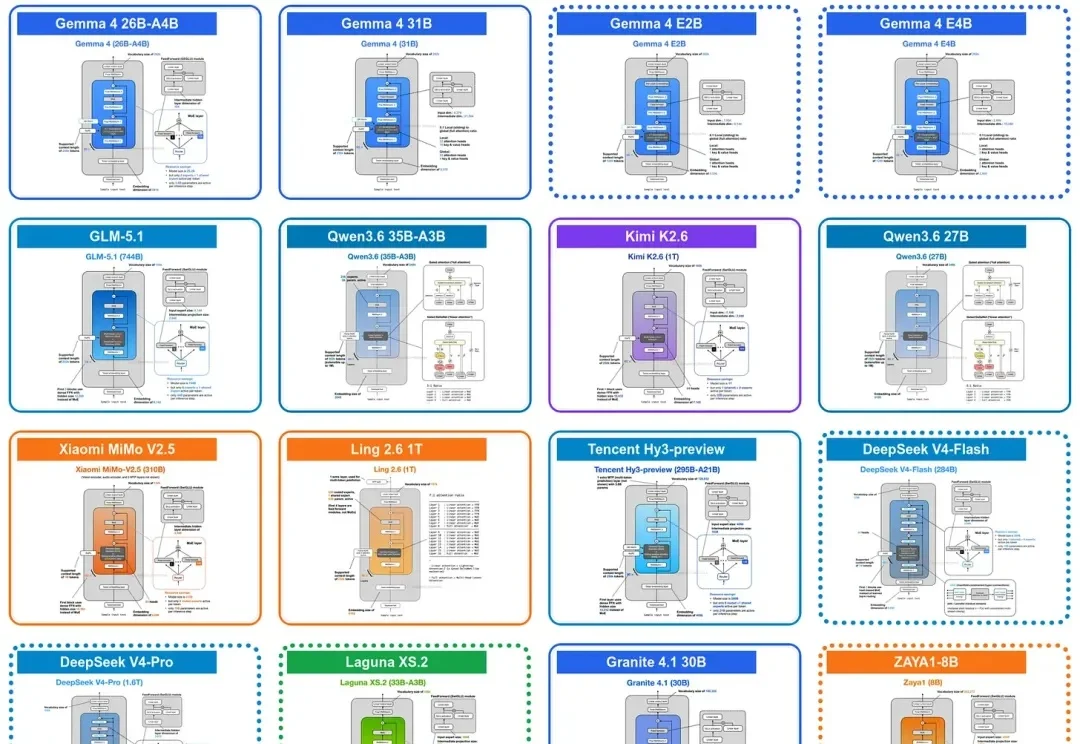
过去一段时间,很多人对大模型都有一个明显感受:token 总是不够用。

伯克利等发布FST框架:通过快慢分层解决大模型持续学习死局。
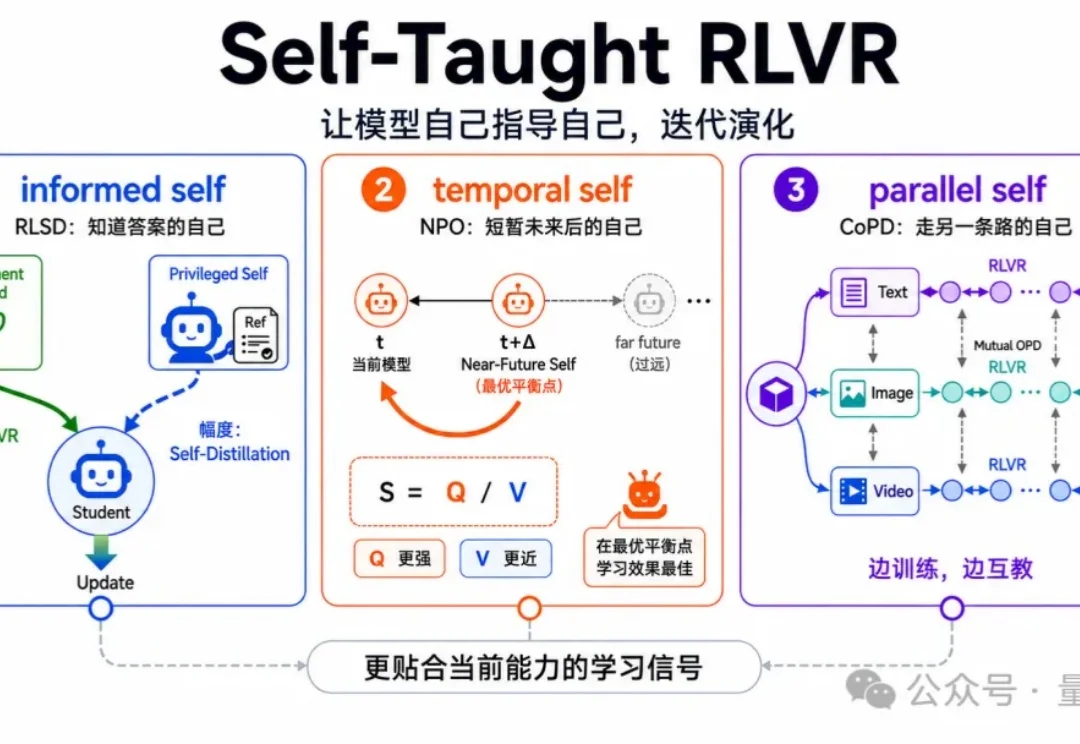
最近,京东和中科院信工所展开了Self-Taught RLVR的系列研究,并连发三篇后训练新作。