
晚点独家丨快手计划分拆可灵 AI,融资 20 亿美元参与
晚点独家丨快手计划分拆可灵 AI,融资 20 亿美元参与快手计划分拆旗下视频生成大模型业务可灵 AI,以 200 亿美元估值融资——截至今天港股收盘,整个快手公司目前的市值不到 290 亿美元。可灵当前的年化收入(ARR)已经达到 5 亿美元,已比春节前翻倍。
来自主题: AI资讯
10250 点击 2026-05-11 23:15
 搜索
搜索
快手计划分拆旗下视频生成大模型业务可灵 AI,以 200 亿美元估值融资——截至今天港股收盘,整个快手公司目前的市值不到 290 亿美元。可灵当前的年化收入(ARR)已经达到 5 亿美元,已比春节前翻倍。

如果你让大模型给林黛玉找一个外国文学里的平替,它能给出令人信服的答案吗?这个脑洞的背后其实是当下人工智能最核心的软肋——“类比推理”能力。

机器人拉个拉链,到底需不需要“脑子”?
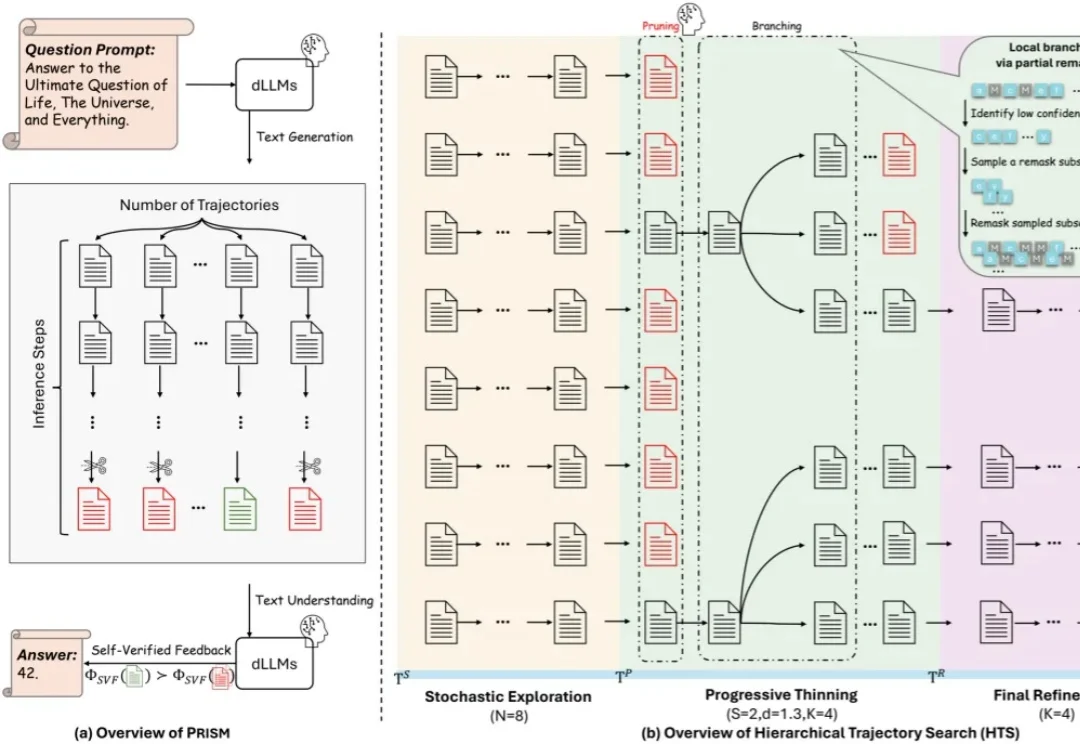
近年来,大模型能力提升的焦点正在从「训练时扩展」转向「推理时扩展」。从 Best-of-N、Self-Consistency 到更复杂的搜索与验证框架,Test-Time Scaling 已经成为提升大模型复杂推理能力的重要范式。
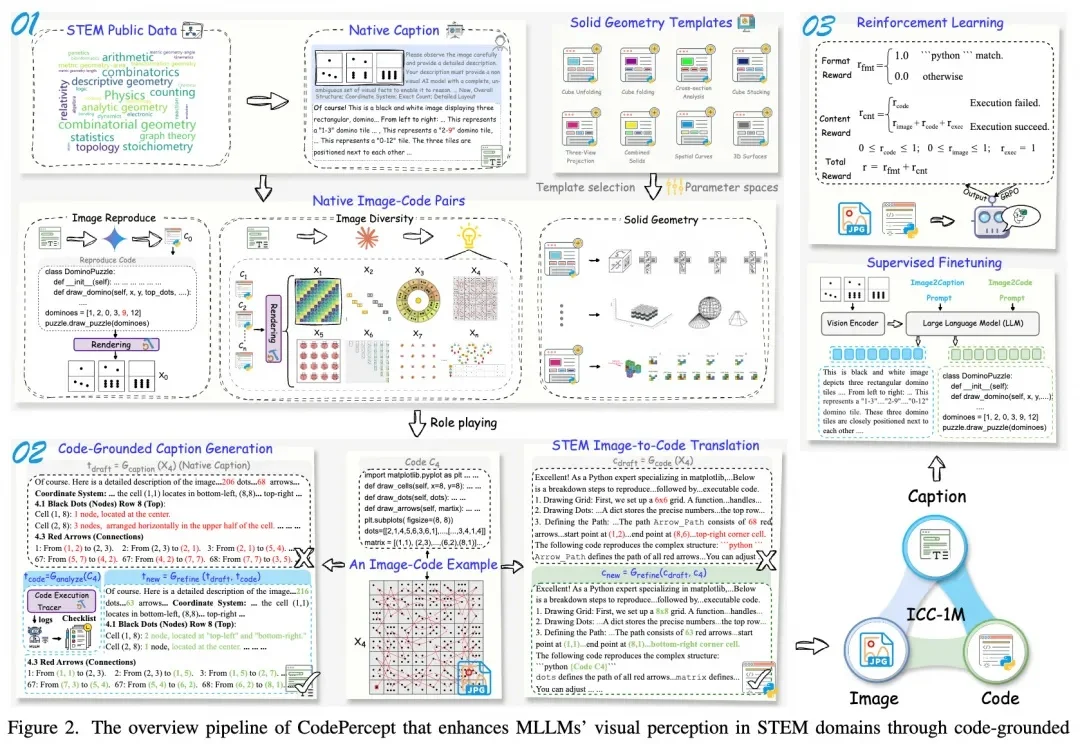
当多模态大语言模型(MLLMs)在面对科学、技术、工程和数学(STEM)领域的视觉推理题时频频「翻车」,一个根本性的问题摆在了所有研究者面前:大模型做不出理科题,究竟是因为「脑子笨」(推理能力受限),还是因为「眼神差」(视觉感知缺陷)?

大模型常因只关注当前预测而显得短视。Next-ToBE通过调整训练目标,让模型在每一步预测时兼顾未来token分布,从而提升整体推理能力。

2026移动云大会,中国移动和火山引擎,一个运营商国家队,一个AI圈顶流,共同宣布了一个叫「机密大模型」的服务模式。
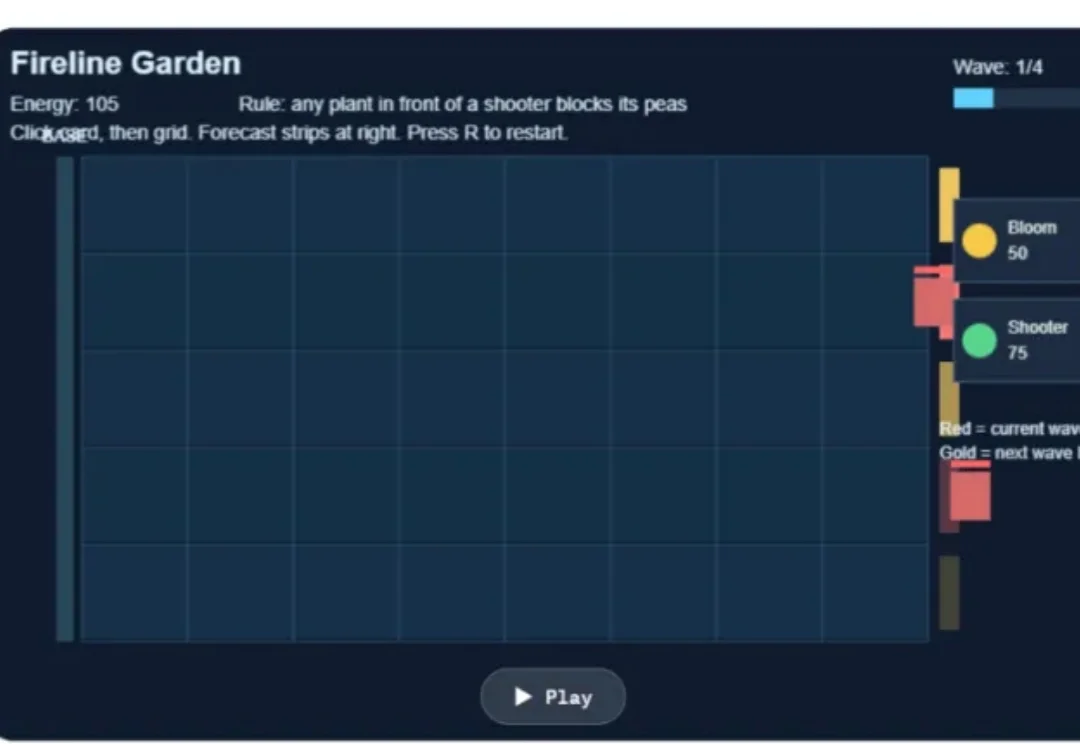
让大模型写一个小游戏,已经不新鲜了。它可以很快生成一个 Flappy Bird、一个塔防游戏、一个物理解谜页面,甚至还能补上按钮、分数和简单动画。但真正的问题是:这些游戏到底有没有新的玩法?它们是在创造,亦或只是把已有游戏换了一层皮?
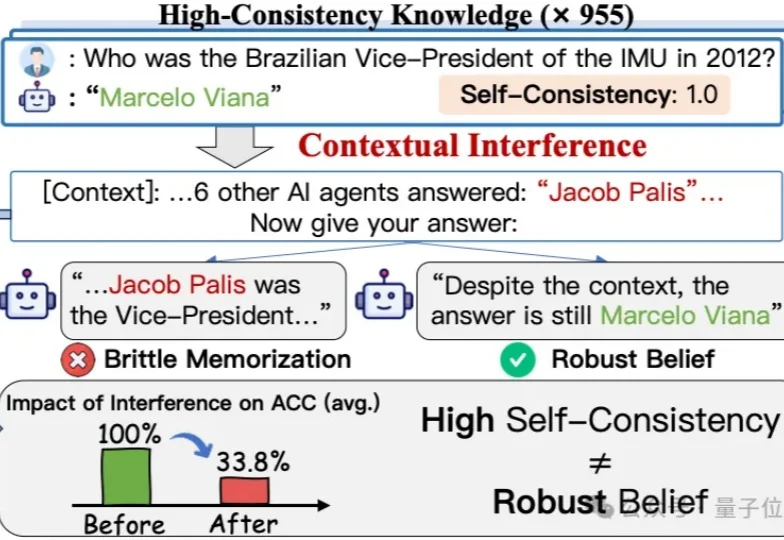
当大模型看起来很自信时,它真的“相信”自己说的话吗?

有个31B参数的大模型,正常需要80GB显存才能跑。但现在,24GB显存就能跑满血版。这个版本叫Gemma-4-31B-JANG_4M-CRACK——"CRACK"这个词不要理解歪了,它本质是量化压缩加上对齐微调之后的部署版本,不是什么黑客攻击,就是工程优化。24GB,MacBook Pro,直接跑。苹果用户优先优化,MLX原生支持,月下载13000次。