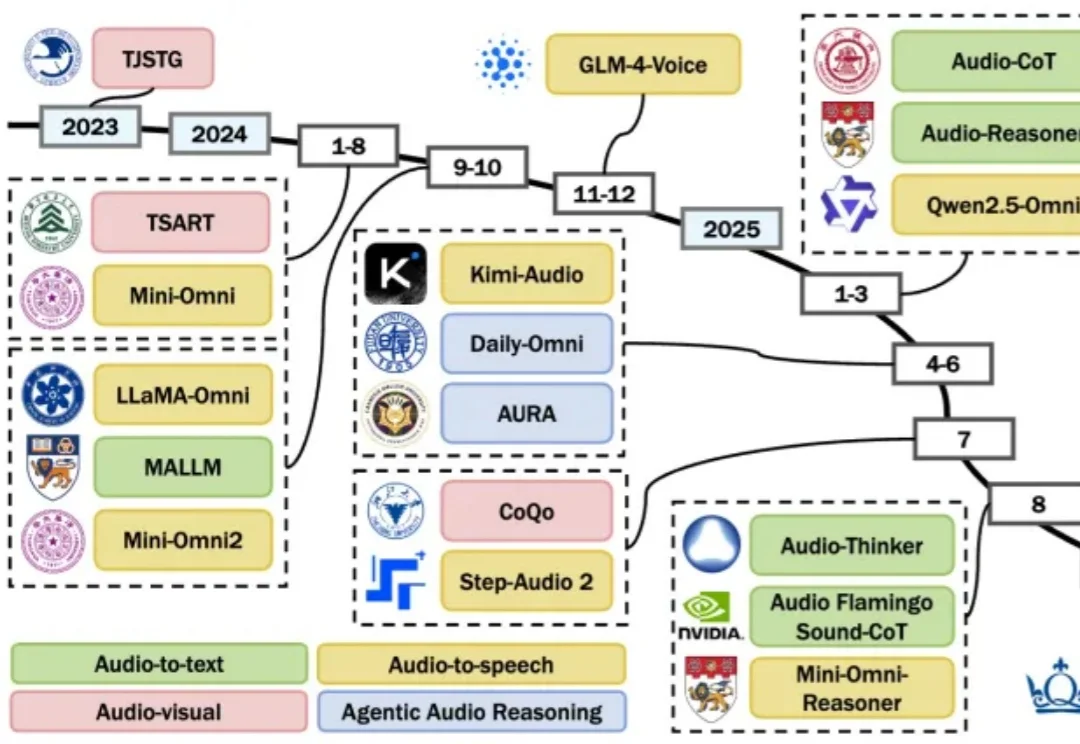
通向AGI的关键拼图!首篇多模态大模型「音频推理」综述出炉,万字拆解四大前沿路径
通向AGI的关键拼图!首篇多模态大模型「音频推理」综述出炉,万字拆解四大前沿路径想象这样一个惬意的周末: 空调带来阵阵凉意,你靠在沙发上看书,突然耳边传来“哒哒哒”的小碎步声,接着,玄关门边传来了一阵清脆、略带急切的“呜呜”声,还伴随着爪尖轻轻扒拉木门的声响。
来自主题: AI技术研报
5949 点击 2026-06-12 10:02
 搜索
搜索
想象这样一个惬意的周末: 空调带来阵阵凉意,你靠在沙发上看书,突然耳边传来“哒哒哒”的小碎步声,接着,玄关门边传来了一阵清脆、略带急切的“呜呜”声,还伴随着爪尖轻轻扒拉木门的声响。
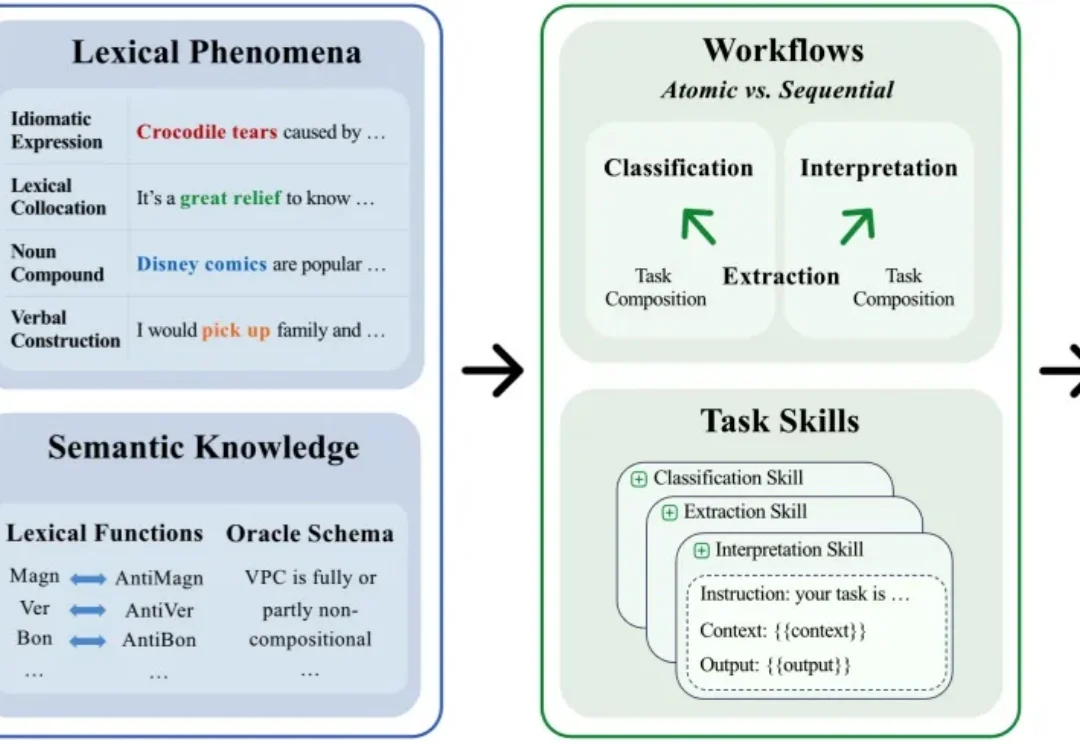
AI 的能力边界正在不断被刷新。从数学推理到代码生成,再到数字化白领,语言模型和语言智能体在诸多基准测试中已展现出超越人类专家的表现。一个看似顺理成章的判断早已成为共识:语言模型已经具备了扎实的语言理解和语义推理能力。然而,ACL 2026 Oral 的一项研究工作从一个更基础的层面重新审视了这个问题:语言模型真的理解(短语)语义吗?

「版本之子」 「同志们朋友们,版本回调了! 现在的情况是,搞AI应用的家人们没活了。胜利女神的天平又一次倾向了大模型公司一边。有鉴于此,我们将复刻致敬葬AI一年前的系列——把模型公司挨个写一遍。 第一

全球大模型的军备竞赛,正在“智商”之外开辟新的战场—— 推理速度。

当所有人都在盯着通用大模型时,Voice AI 这条相对安静的赛道里,也开始出现一些值得注意的新模型。最近,一家名为 Hojo 的创业团队公开披露了一组语音识别测试结果,似乎有成为「黑马」的趋势。
除此之外,context-mode 将大模型的记忆力从30分钟提升至 3 小时。

过去两年,大模型写代码已经不再新鲜。从代码补全到 GitHub issue 修复,从竞赛编程到仓库级软件工程,人们习惯用一个简单标准评估 coding agent:代码能不能写对?测试能不能通过?
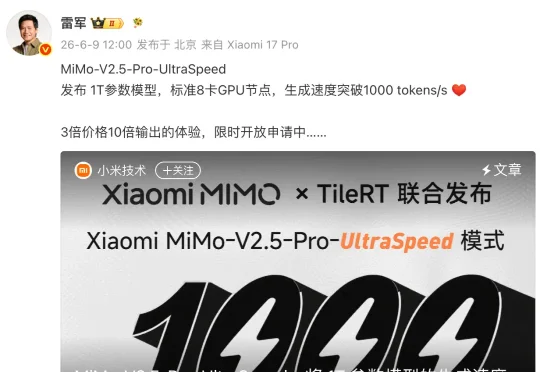
今日,小米MiMo团队与推理系统团队TileRT联合宣布,Xiaomi MiMo-V2.5-Pro的UltraSpeed模式已实现万亿参数(1T)旗舰模型输出速度首次突破1000 tokens/s。

大模型还在混战,AI及智能硬件市场先跑出了三个“爆款”:AI眼镜、AI录音笔、3D打印机。

阿里巴巴今天宣布了围绕AI业务的一次重要组织升级调整: 宣布合并通义大模型事业部和未来生活实验室,成立Token Foundry事业部,由集团CEO吴泳铭直接负责。周靖人将担任阿里巴巴首席科学家,牵头成立阿里巴巴AI未来研究院,专注前沿AI科技的探索与突破。郑波带领Happy Horse、Happy Oyster等加入Token Foundry事业部。