
大晓机器完成天使+轮融资,自主研发世界模型Kairos登顶4大具身智能榜单
大晓机器完成天使+轮融资,自主研发世界模型Kairos登顶4大具身智能榜单刚刚,大晓机器人半年融资数亿美元,开悟世界模型同时刷新四大权威榜单第一,4B参数硬刚28B大模型!具身智能的「ChatGPT时刻」真的要来了?
来自主题: AI资讯
7409 点击 2026-06-15 15:08
 搜索
搜索
刚刚,大晓机器人半年融资数亿美元,开悟世界模型同时刷新四大权威榜单第一,4B参数硬刚28B大模型!具身智能的「ChatGPT时刻」真的要来了?

新智元报道 【新智元导读】FuseSearch:学习型自适应并行执行 —— 一个40亿参数的模型,凭什么在代码定位上干过了商用闭源大模型?答案只有四个字:搜得更聪明。 在AI编程狂飙突进的今天,一个尴

世界杯已经开打了,相信在做有很多朋友抄起了手里的大模型,遛一遛是鸭是鹅
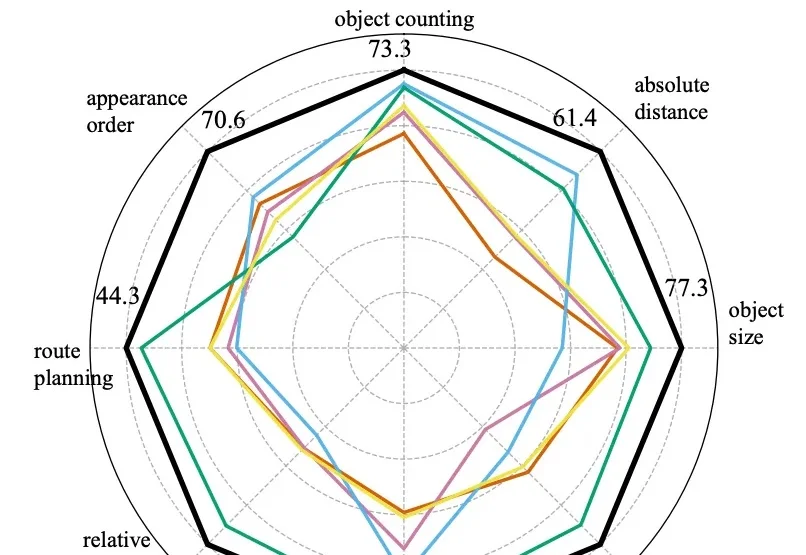
大模型已经能流畅对话、看图识物,但一个更底层的问题始终没被真正解决——它们是否「理解」了我们所处的三维世界?

多模态大模型越来越会读图中文字,但最新研究显示,「读得出来」并不等于「防得住」。西湖大学 AGI Lab 的研究团队发现,当有害文本被渲染成低清、模糊或带噪图片后,模型在一个特定清晰度区间内反而更容易被越狱。
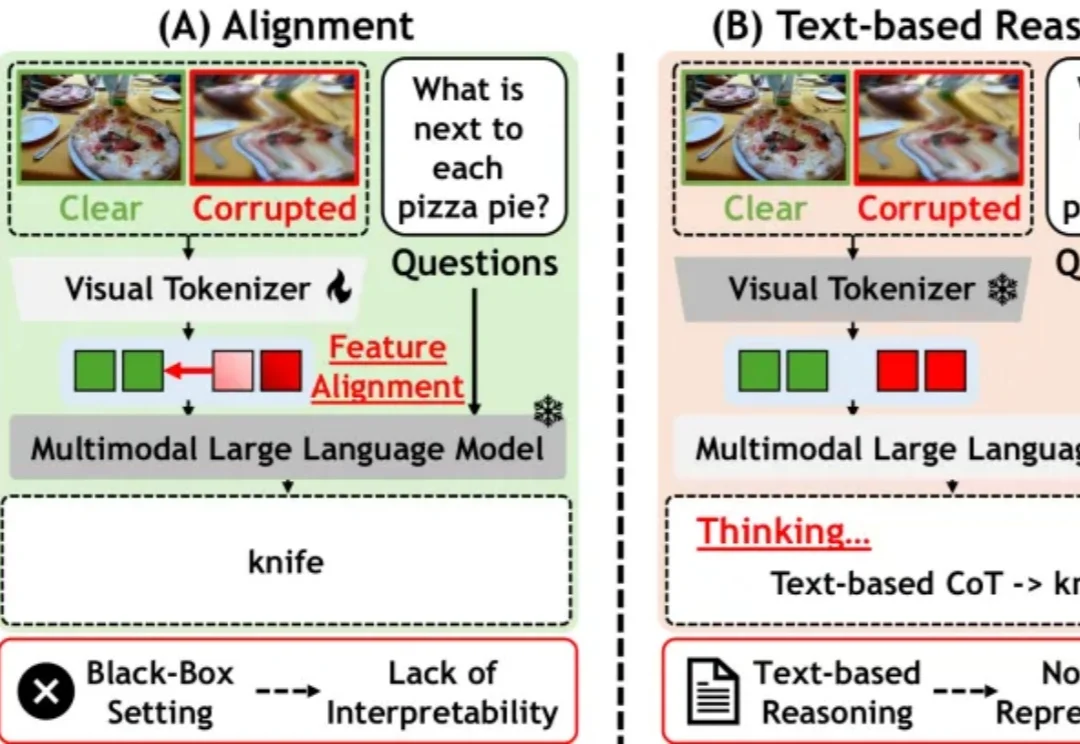
雨雪、雾霾、镜头噪点、压缩失真、夜间弱光……
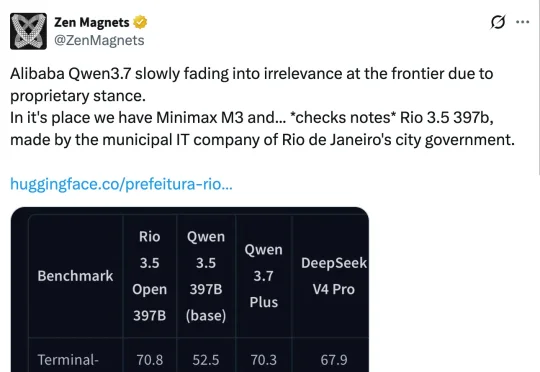
今天,除了全球(非美)被禁的 Claude Fable 5,AI 社区还被一个开源模型刷屏了。有推特博主发现,一个由巴西里约热内卢市政府旗下 IT 公司开源的模型 Rio 3.5 397B,在多项基准测试中超越了 Qwen 3.7 Plus 等开源模型,而这个模型的基础模型还是 Qwen3.5-397B-A17B。

刚刚,医疗大模型赛道的魔咒,终于被打破了!讯飞医疗正式发布——星火医疗大模型V3.5。生成病历医生采纳率91%、书写时间缩短52%、累计辅助诊断超12亿次。这一连串的数字,直接把医疗AI「最难用的门槛」踩在脚下。

决策机已推演23万起事件,准确率超90%。

上下文攻击、供应链渗透、AI社区崩溃……当大模型智能体真正进入开放世界,挑战远比想象中复杂。