模型砍掉一大半,准确率反升15%!华科&阿里安全新研究实现ViT近乎无损的类特定压缩|ICLR'26
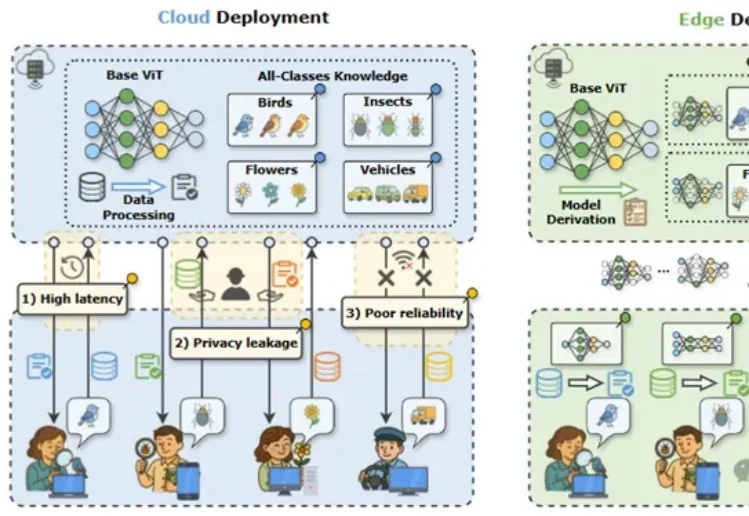
模型砍掉一大半,准确率反升15%!华科&阿里安全新研究实现ViT近乎无损的类特定压缩|ICLR'26近年来,视觉大模型在自动驾驶、智慧医疗等场景中得到广泛应用,但在真实业务环境中,“大而全”的通用模型往往并不是最优选择。
来自主题: AI技术研报
6285 点击 2026-03-06 09:32
 搜索
搜索
近年来,视觉大模型在自动驾驶、智慧医疗等场景中得到广泛应用,但在真实业务环境中,“大而全”的通用模型往往并不是最优选择。

北京时间3月4日下午约13:00,通义实验室紧急召开了All Hands会议,阿里集团CEO吴泳铭向千问员工坦诚表示。12个小时前(北京时间3月4日凌晨0点11分),阿里千问大模型技术负责人林俊旸在X上突然宣布离职——林俊旸是阿里AI开源模型的核心推手,也是阿里最年轻的P10之一——行业一片哗然之时,Qwen的部分成员也无法接受团队灵魂人物的突然出走。
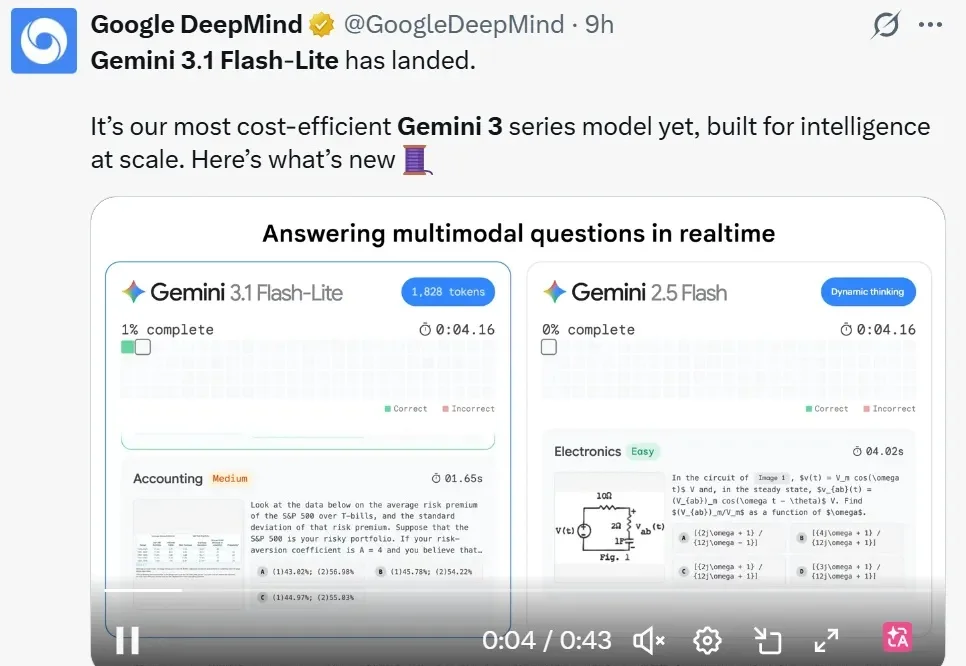
深夜,两大科技巨头谷歌和 OpenAI 硬刚起来,相继推出了新版本大模型,分别是 Gemini 3.1 Flash-Lite、GPT‑5.3 Instant。

全新的具身模型空间能力评估范式 Theory of Space 突破了传统静态图文问答的局限,系统性地考察基础模型能否像人一样,在部分可观测的动态环境中,通过自主探索来构建、修正和利用空间信念。该论文已被 ICLR 2026 接收。
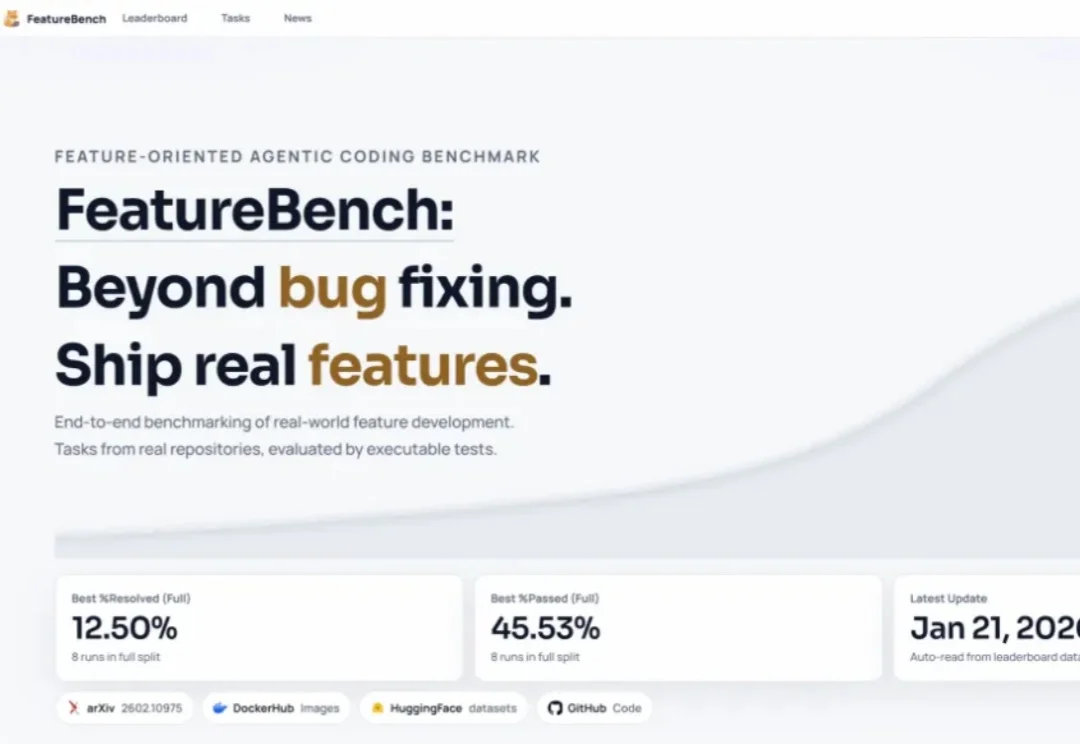
在 Princeton 发布 SWE-Bench 之后,用真实世界代码仓库+可执行测试评测大模型软件工程能力,几乎已成为学术界与工业界的共识。围绕 SWE issue 的评测范式迅速发展,也催生了一系列 SWE 系列 benchmark,在刻画模型 bug 修复能力方面发挥了重要作用。

伴随多模态大模型的发展,GUI Agent正成为人机交互的新范式。

首Token提速2.5倍,推理成绩干翻前代大模型。

me stepping down. bye my beloved qwen.(我将卸任。再见了,我深爱的 qwen。) 3 月 4 日凌晨,阿里通义千问(Qwen)技术负责人林俊旸在 X 突然发文,向自己一手带大的开源模型项目告别。

没有图片,也能预训练多模态大模型?在多模态大模型(MLLM)的研发中,行业内长期遵循着一个昂贵的共识:没有图文对(Image-Text Pairs),就没有多模态能力。
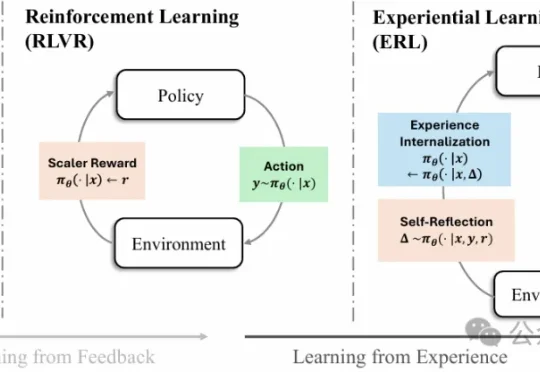
强化学习已经成为大模型后训练阶段的核心方法之一,但一个长期存在的难题始终没有真正解决:现实环境中的反馈往往稀疏且延迟,模型很难从简单的奖励信号中推断出应该如何调整行为。