# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
多模态图片检索是计算机视觉和多模态机器学习领域很重要的一个任务。现在大家做多模态图片检索一般会用 CLIP/SigLIP 这种视觉语言大模型,因为他们经过了大规模的预训练,所以 zero-shot 的能力比较强。
牛津 VGG ,港大,上交大团队这篇论文旨在提供一种方法,能够用学术界的资源来增强视觉语言大模型的预训练 (Enhance Language-Image Pre-training),使得其可以更好地用于文字 - 图片检索。这篇论文被 IEEE 国际基于内容的多媒体索引大会(IEEE International Conference on Content-Based Multimedia Indexing)接受,并被评选为最佳论文提名,大会近期在爱尔兰都柏林召开。

下图是这篇文章方法的预览图。ELIP 方法的核心思想是,先用传统的 CLIP/SigLIP 对全体图片做一次 ranking,然后选出 top-k candidate 再做一次 re-ranking。做 re-ranking 的时候,作者设计了一个简单的 MLP mapping network,可以用文字的特征来定义一些视觉域中的 token,并把这些 token 插入到 image encoder 当中,使得 image encoder 在编码图片信息的时候可以感知到语言信息。这样重新编码之后的图片信息和语言信息再做比对的时候,同一个语言 query 能得到更好的 ranking 结果。ELIP 可以应用到一系列大模型上,比如 CLIP/SigLIP/SigLIP-2/BLIP-2,作者称之为 ELIP-C/ELIP-S/ELIP-S-2/ELIP-B。
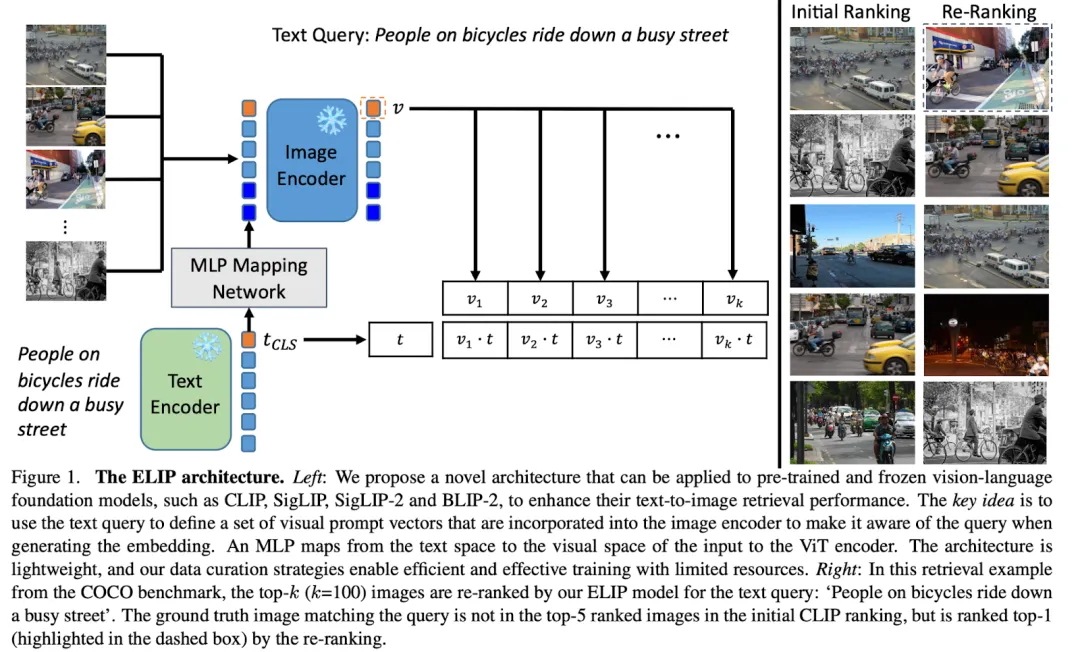
视觉语言大模型的预训练,一般都是工业界做的事情,但作者提出的方法使得用学术界两张 GPU 做训练也变得可能。想法的创新点主要在模型架构和训练数据上。
创新点:模型架构
模型架构上,庞大的图片编码器和文本编码器的权重是固定的,只有作者涉及的由三层 linear + GeLU 构成的 MLP maping network 需要打开训练。
下图是 ELIP-C 和 ELIP-S 的训练图示。训练的时候,一个 batch 的文本图片对输入模型,文本特征映射到视觉特征空间来引导图片信息的编码。对于 CLIP 沿用 InfoNCE 损失函数,对于 SigLIP 沿用 Sigmoid 损失函数,来对齐文本特征和重新计算的图片特征。
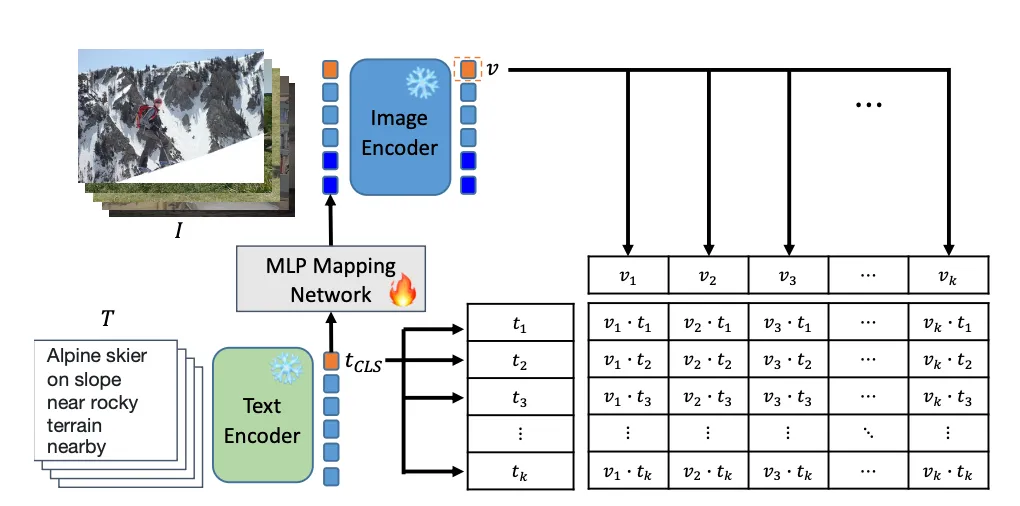
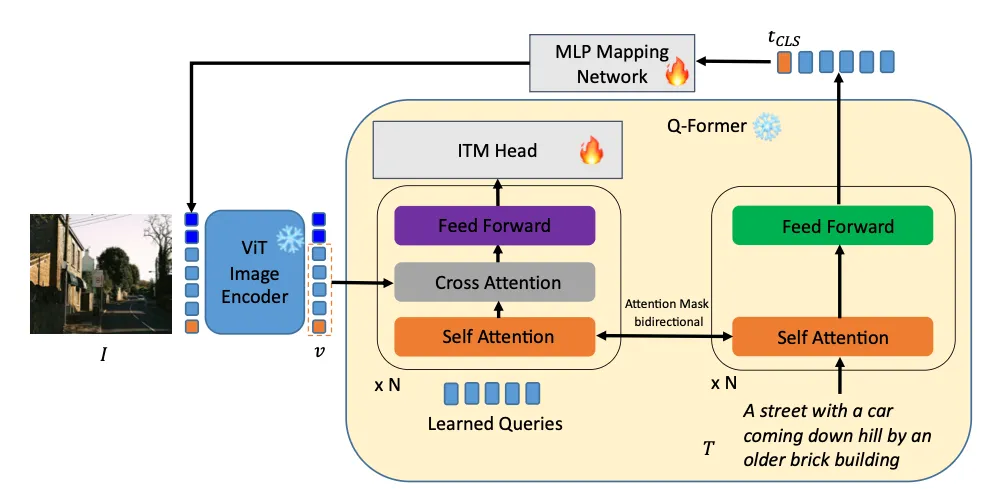
下图是 ELIP-B 的训练图示。和 CLIP/SigLIP 类似,MLP mapping network 把文本特征映射到视觉特征空间。唯一不同的是,在这里由文本引导的图片特征放进了 Q-Former 来和输入的文本做 cross-attention,并最终由 ITM Head 来预测图片和文本是否匹配。训练的时候,ELIP-B 沿用 BLIP-2 的 BCE 损失函数。
创新点:训练数据
训练数据上,在学术界做大模型训练要面临的挑战就是 GPU 数量不够,没法开很大的 batch size 训练,这样可能训练出来的模型分辨能力就会下降。而 ELIP 却是要去分辨 CLIP/SigLIP 排序出来的 hard sample,对模型分辨能力的要求就更高了。为了解决这样的挑战,作者在训练的时候先算了一下每个训练图片和对应文字标题的 CLIP 特征,然后把相似特征的图文对聚集在一起形成 hard sample training batch。下图是作者聚合的训练 batch 的例子。对于每一行,第一个 sample 被用来聚合其他 sample。第一行的 caption 从左往右分别是:'a wooden table with no base'; 'a wooden table with a couple of folding legs on it'; 'a table that has a metal base with an olive wood top'; 'small table outdoors sitting on top of the asphalt'。第二行的 caption 从左往右分别是:'a huge body of blue ice floats in a mountain stream'; 'the big chunk of glacier is falling off of the cliff'; 'there is a broken piece of glass that has been broken from the ground'; 'a body of water surrounded by a forest near a mountain'。

新的评测数据集
除了在标准测试集比如 COCO, Flickr 上做测试之外,作者还提出了两个新的 OOD 测试集:Occluded COCO 和 ImageNet-R。对于 Occluded COCO,正样本包含了文字中描述的物体(物体通常被遮挡);对于 ImageNet-R,正样本中包含了文字中描述的物体,但是是来自一些不常见的领域的。负样本中不含文字中描述的物体。下图是一些例子,第一行是正样本,第二行是负样本。对于 Occluded COCO,正样本中含有被遮挡的自行车,负样本中不含自行车;对于 ImageNet-R,正样本中含有金鱼,负样本中不含金鱼。

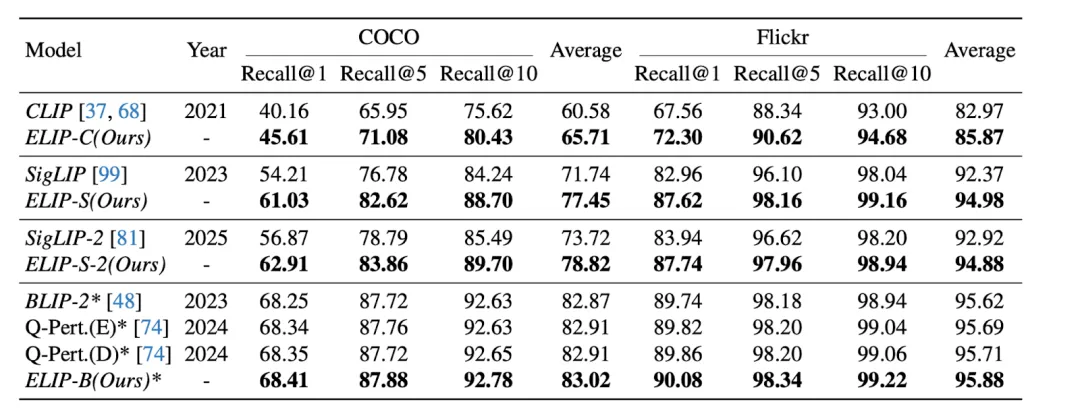
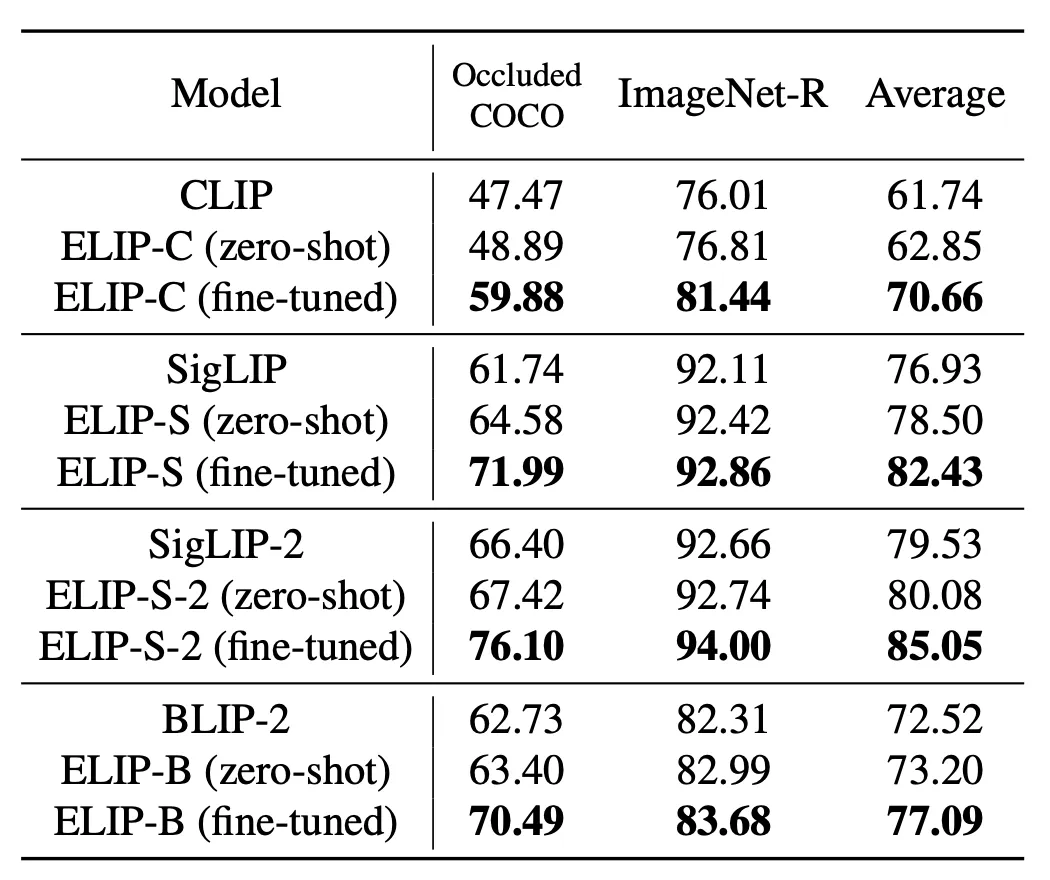
文章的结果如下表。可以看到,应用了 ELIP 之后,CLIP/SigLIP/SigLIP-2 的图片检索表现都显著增长,甚至于 SigLIP 系列模型达到了和 BLIP-2 接近的表现。ELIP-B 应用到 BLIP-2 上之后,也提升了 BLIP-2 的表现,超过了最新的 Q-Pert 方法。
在 OOD 的测试数据集上,ELIP-C/ELIP-S/ELIP-S-2/ELIP-B 都取得了 zero-shot 的泛化提升。如果我们在对应的 domain 上做一些 fine-tune,比如对于 Occluded COCO 我们在 COCO 数据集上 fine-tune,对于 ImageNet-R 数据集我们在 ImageNet 数据集上 fine-tune,可以得到更显著的提升。这进一步说明了 ELIP 除了增强预训练之外,还提供了一种高效的 adaptation 的方式。
作者进一步观察了注意力图,发现当 text query 和图片相关时,ELIP 可以提高图片信息提取 CLS token 对于文字描述的相关区域的注意力和信息提取。

更多细节详见论文原文。
文章来自于“机器之心”,作者“机器之心”。


