牛津VGG、港大、上交发布ELIP:超越CLIP等,多模态图片检索的增强视觉语言大模型预训练
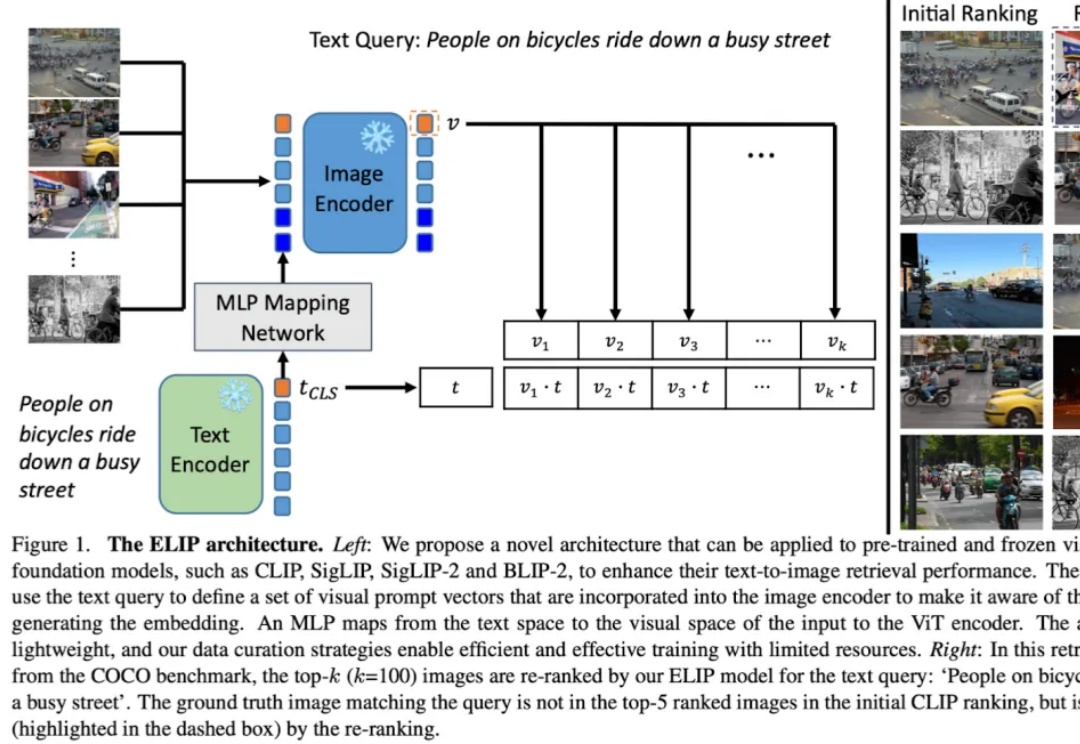
牛津VGG、港大、上交发布ELIP:超越CLIP等,多模态图片检索的增强视觉语言大模型预训练多模态图片检索是计算机视觉和多模态机器学习领域很重要的一个任务。现在大家做多模态图片检索一般会用 CLIP/SigLIP 这种视觉语言大模型,因为他们经过了大规模的预训练,所以 zero-shot 的能力比较强。
来自主题: AI技术研报
7768 点击 2025-10-30 10:42
 搜索
搜索
多模态图片检索是计算机视觉和多模态机器学习领域很重要的一个任务。现在大家做多模态图片检索一般会用 CLIP/SigLIP 这种视觉语言大模型,因为他们经过了大规模的预训练,所以 zero-shot 的能力比较强。