
一口气集齐老黄苏妈英特尔,还得是AI,还得是联想
一口气集齐老黄苏妈英特尔,还得是AI,还得是联想联想给出的公式是,混合AI=个人智能+企业智能+公共智能。这种模式下,AI智能体应用不再依赖于单一的云端模型,而是云端大模型与本地定制化小模型的深度融合。
来自主题: AI资讯
9434 点击 2026-01-09 14:41
 搜索
搜索
联想给出的公式是,混合AI=个人智能+企业智能+公共智能。这种模式下,AI智能体应用不再依赖于单一的云端模型,而是云端大模型与本地定制化小模型的深度融合。

谁能想到,AI界最权威的大模型排行榜,竟然是个彻头彻尾的骗局?最近,2025年底的一篇名为《LMArena is a cancer on AI》的文章被翻了出来。登上了Hacker News的首页,引起轩然大波!
今日,小米前高管王腾在个人微博发文透露创业新动态。据其所述,从小米离开后开始筹备创业,最近新公司已经成立,公司取名为“今日宜休”,目标是通过研发睡眠健康相关的产品。谈及入局“AI+健康睡眠”领域,王腾认为,新时代下AI大模型发展迅速,让很多产品的体验能大幅提升。

针对端到端全模态大模型(OmniLLMs)在跨模态对齐和细粒度理解上的痛点,浙江大学、西湖大学、蚂蚁集团联合提出 OmniAgent。这是一种基于「音频引导」的主动感知 Agent,通过「思考 - 行动 - 观察 - 反思」闭环,实现了从被动响应到主动探询的范式转变。

今天,Qwen 家族新成员+2,我们正式发布 Qwen3-VL-Embedding 和 Qwen3-VL-Reranker 模型系列,这两个模型基于 Qwen3-VL 构建,专为多模态信息检索与跨模态理解设计,为图文、视频等混合内容的理解与检索提供统一、高效的解决方案。
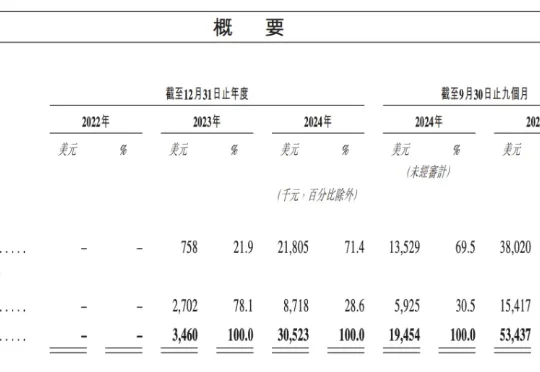
即将于 1 月 9 日敲钟上市的大模型公司 MiniMax,创下近年来港股 IPO 机构认购历史记录。此次参与 MiniMaxIPO 认购的机构超过 460 家,超额认购达 70 多倍。此前的认购记录属于宁德时代,其在 2025 年登陆港股市场时,剔除基石后超额认购 30 倍。
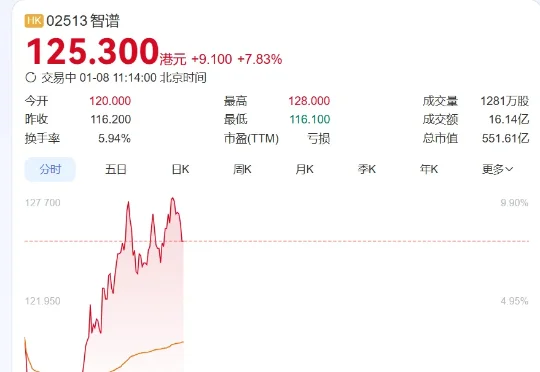
1月8日,大模型六小龙第一股,智谱上市了,市值直超551亿港元,而且一路涨幅超已逾7%。而就在上市前一天,小编注意到,智谱创立发起人兼首席科学家唐杰在微博上发布了一条充满预告意味的帖子,称:“AA(artificialanalysis)换了几个benchmark,基本是把原来刷爆的都换了,现在评估越来越难,新增加的Physical Reasoning貌似还很难。。。。”

本文为《2025 年度盘点与趋势洞察》系列内容之一,由 InfoQ 技术编辑组策划。本系列覆盖大模型、Agent、具身智能、AI Native 开发范式、AI 工具链与开发、AI+ 传统行业等方向,通过长期跟踪、与业内专家深度访谈等方式,对重点领域进行关键技术进展、核心事件和产业趋势的洞察盘点。
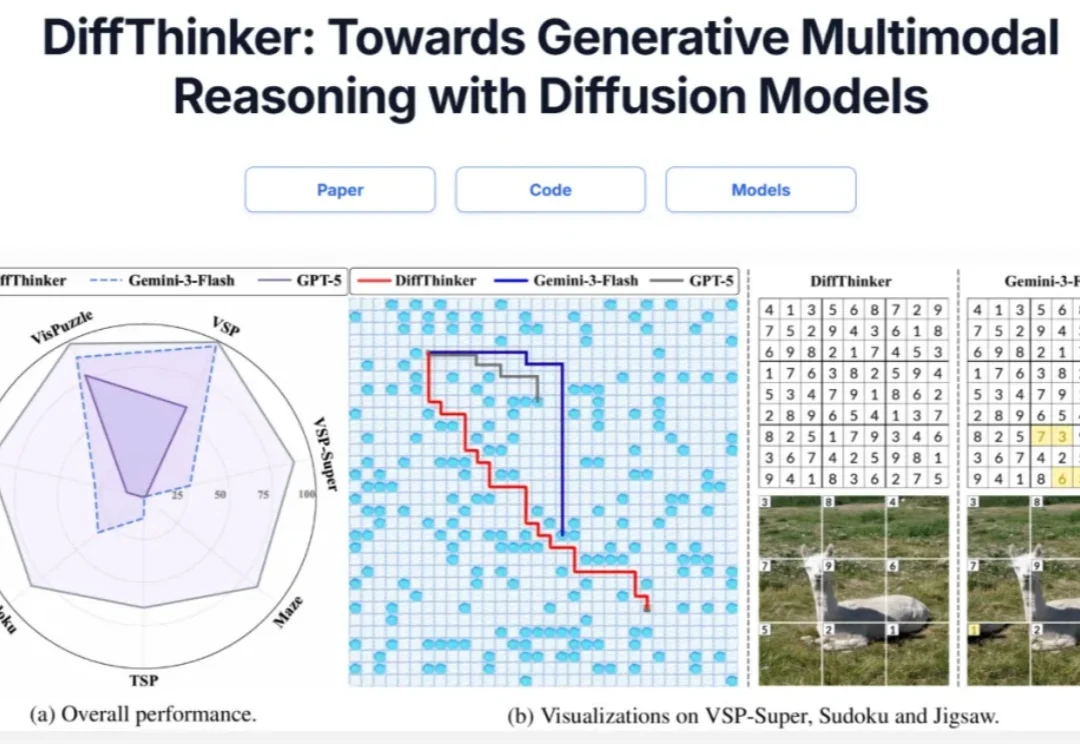
在多模态大模型(MLLMs)领域,思维链(CoT)一直被视为提升推理能力的核心技术。然而,面对复杂的长程、视觉中心任务,这种基于文本生成的推理方式正面临瓶颈:文本难以精确追踪视觉信息的变化。形象地说,模型不知道自己想到哪一步了,对应图像是什么状态。
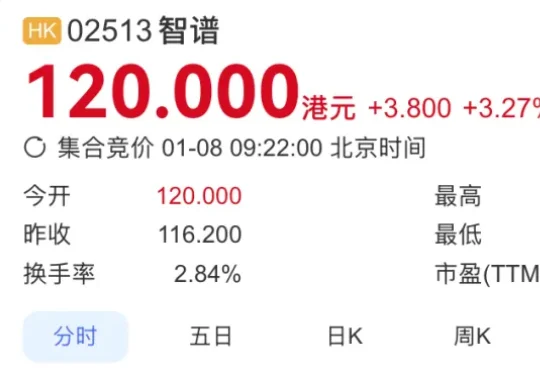
刚刚,全球大模型第一股,终于在港交所敲钟!被称为中国版OpenAI的智谱正式挂牌上市(股票代码2513)。不仅拿下全球首家AGI基座模型上市公司头衔,首日开盘涨超3%,报120港元/股,市值突破528亿港元。