
谷歌Gemini和苹果的顶级华人科学家离职创业,剑指AGI
谷歌Gemini和苹果的顶级华人科学家离职创业,剑指AGI谷歌 Gemini 数据联合负责人 Andrew Dai 联手苹果首席研究科学家 Yinfei Yang,隐身创办 AI 新秀 Elorian。首轮将融资 5000 万美元,剑指「视觉推理」这个下一代大模型的核心问题。
来自主题: AI资讯
7477 点击 2026-01-12 10:31
 搜索
搜索
谷歌 Gemini 数据联合负责人 Andrew Dai 联手苹果首席研究科学家 Yinfei Yang,隐身创办 AI 新秀 Elorian。首轮将融资 5000 万美元,剑指「视觉推理」这个下一代大模型的核心问题。

大模型能写代码、解奥数,却连幼儿园小班都考不过?简单的连线找垃圾桶、数积木,人类一眼即知,AI却因为无法用语言「描述」视觉信息而集体翻车。大模型到底「懂不懂」,这个评测基准给出答案。
这些改变世界的产品,最初居然都是不被当回事儿的支线项目(side project)?!
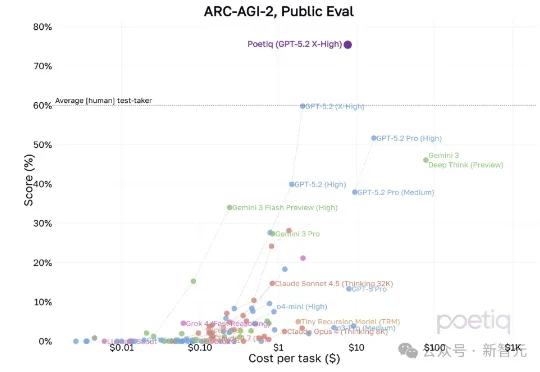
刚刚,GPT-5.2刷新了一项新纪录!OpenAI联合创始人Greg Brockman发帖称使用GPT-5.2在ARC-AGI-2基准测试上,表现超过了人类基线水平。

1月10日,很久没有公开露面的月之暗面创始人杨植麟,在一场定向邀请的行业论坛中,详细地分享了2025年Kimi的技术路线重点,以及对未来的思考。这次分享,有一个核心关键词,Agentic智能时代。这是通用大模型竞争的一个未来高地
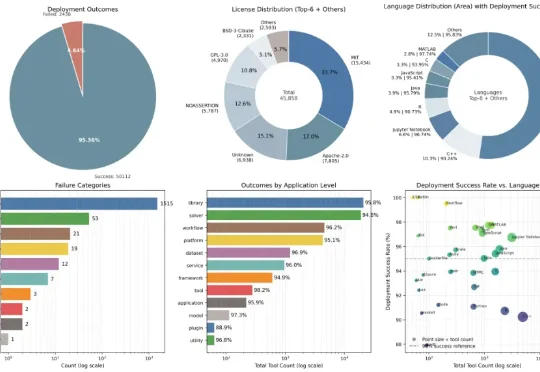
在真实世界中,部署并不是一个孤立步骤,而是一条连续链路:工具能否被发现、是否被正确理解、能否构建环境,以及是否真的可以被执行。Deploy-Master 正是围绕这条链路,被设计为一个以执行为中心的一站式自动化工作流。
就在医疗AI赛道激战正酣时,一个搅局者低调入场了。它就是蚂蚁集团联合浙江省卫生健康信息中心、浙江省安诊儿医学人工智能科技有限公司开源的医疗大模型——蚂蚁·安诊⼉(AntAngelMed)。
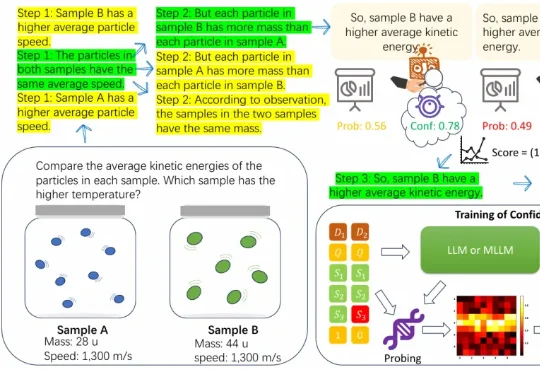
近年来,大语言模型在算术、逻辑、多模态理解等任务上之所以取得显著进展,很大程度上依赖于思维链(CoT)技术。所谓 CoT,就是让模型在给出最终答案前,先生成一系列类似「解题步骤」的中间推理。 这种方式
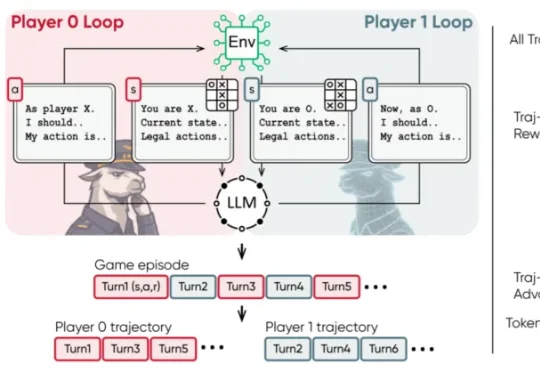
近日,清华大学等机构的研究团队提出了 MARSHAL 框架。该框架利用强化学习,让大模型在策略游戏中进行自博弈(Self-Play)。实验表明,这种多轮、多智能体训练不仅提升了模型在游戏中的博弈决策水

MIT天才博士一毕业,火速加盟OpenAI前CTO初创!最近,肖光烜(Guangxuan Xiao)在社交媒体官宣,刚刚完成了MIT博士学位。下一步,他将加入Thinking Machines,专注于大模型预训练的工作。