

腾讯挖来多位字节Seed骨干,向姚顺雨汇报丨智能涌现独家
腾讯挖来多位字节Seed骨干,向姚顺雨汇报丨智能涌现独家据接近腾讯混元团队的知情人士透露,原字节Seed视觉AI平台团队负责人肖学锋,Infra团队张弛于近期低调入职腾讯,负责大模型Infra相关工作,向腾讯首席AI科学家姚顺雨汇报。
来自主题: AI资讯
8331 点击 2026-03-24 22:32
据接近腾讯混元团队的知情人士透露,原字节Seed视觉AI平台团队负责人肖学锋,Infra团队张弛于近期低调入职腾讯,负责大模型Infra相关工作,向腾讯首席AI科学家姚顺雨汇报。
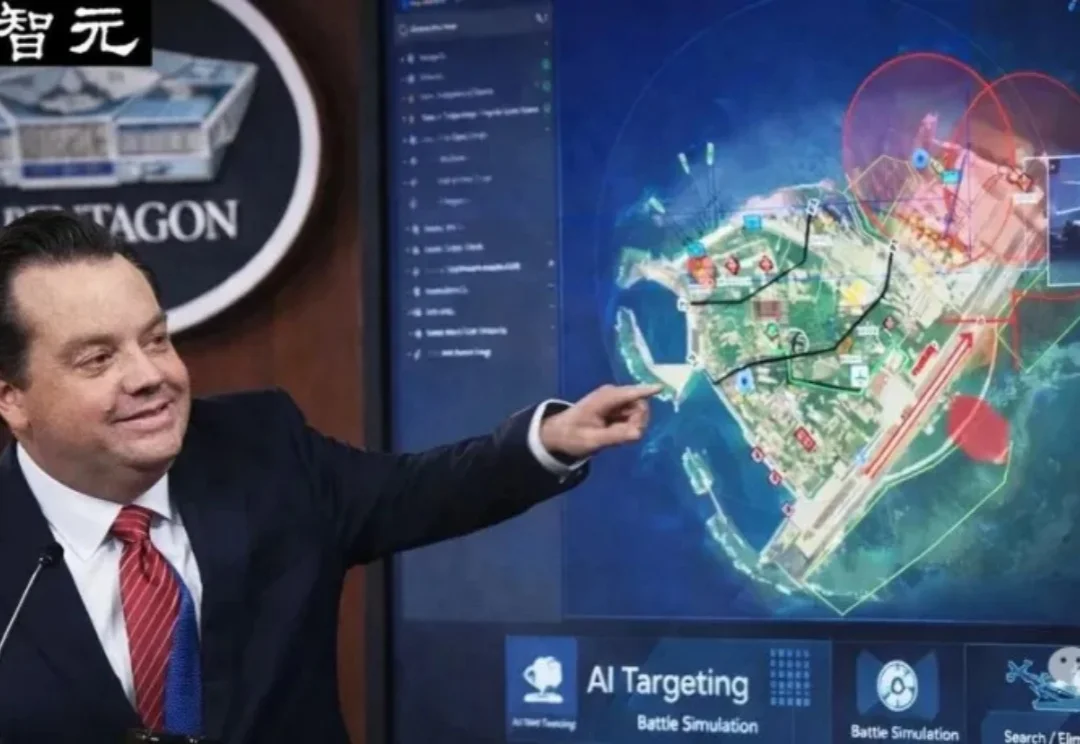
当大众还在热衷于让大模型编代码、写周报或者生成搞笑图片时,硅谷最顶尖的AI技术,已经悄悄渗入了五角大楼的「杀伤链」。

4月21-22日北京站将正式举行~

多模态大模型,到底有多“嘴硬”? 浙江大学联合阿里巴巴、香港城市大
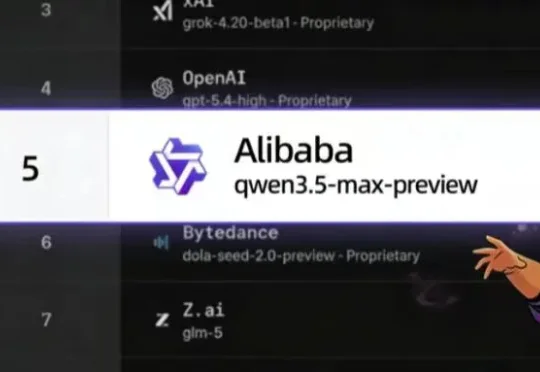
今日,阿里千问最新旗舰模型预览版Qwen3.5-Max-Preview正式亮相,并登上全球大模型评测平台LMArena。在最新榜单中,该模型拿下1464分,进入第一梯队,同时带动阿里千问跻身全球大模型实验室前五、国内第一。
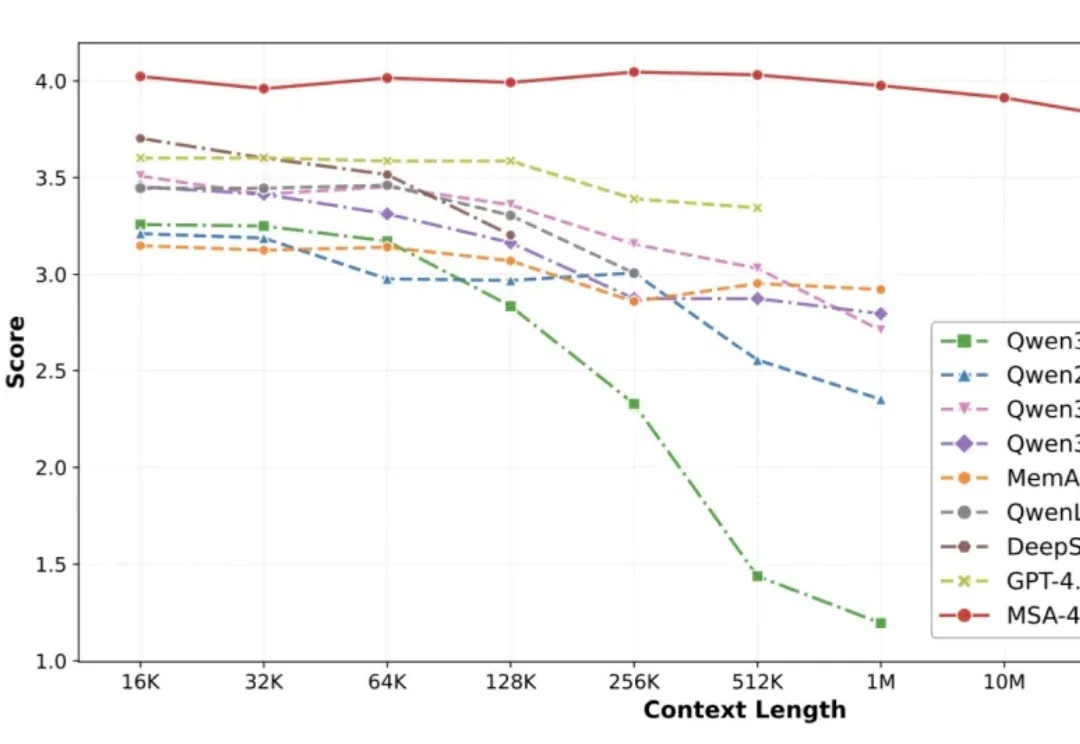
人的智能能力主要由推理能力和长期记忆能力构成。近年来,大模型的推理能力一直处于快速发展过程,但大模型的长期记忆能力一直受限于上下文长度,无法取得突破。在历史上,曾经有多种路线进行尝试,但都无法突破扩展性(Scalability)、精度(Precision)和效率(Efficiency)的不可能三角。
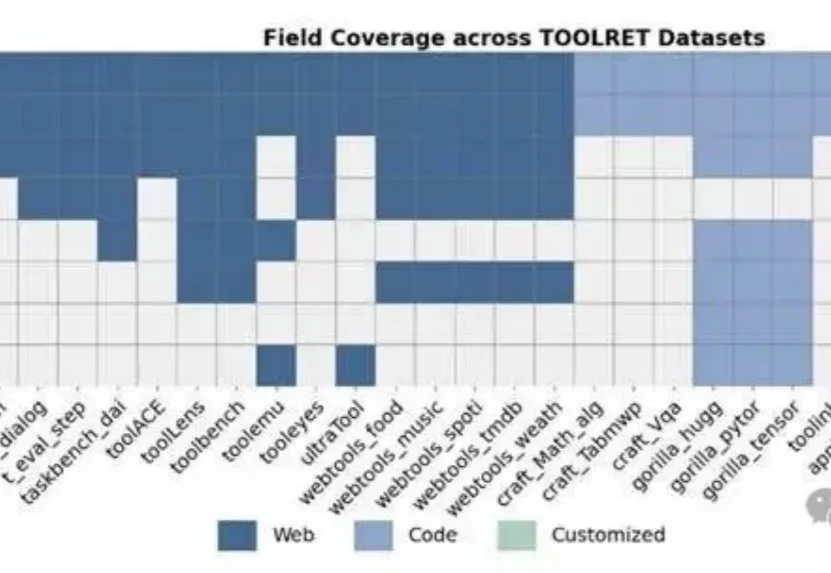
在大模型时代,Tool-Use已经成为智能体能力的核心组成部分。
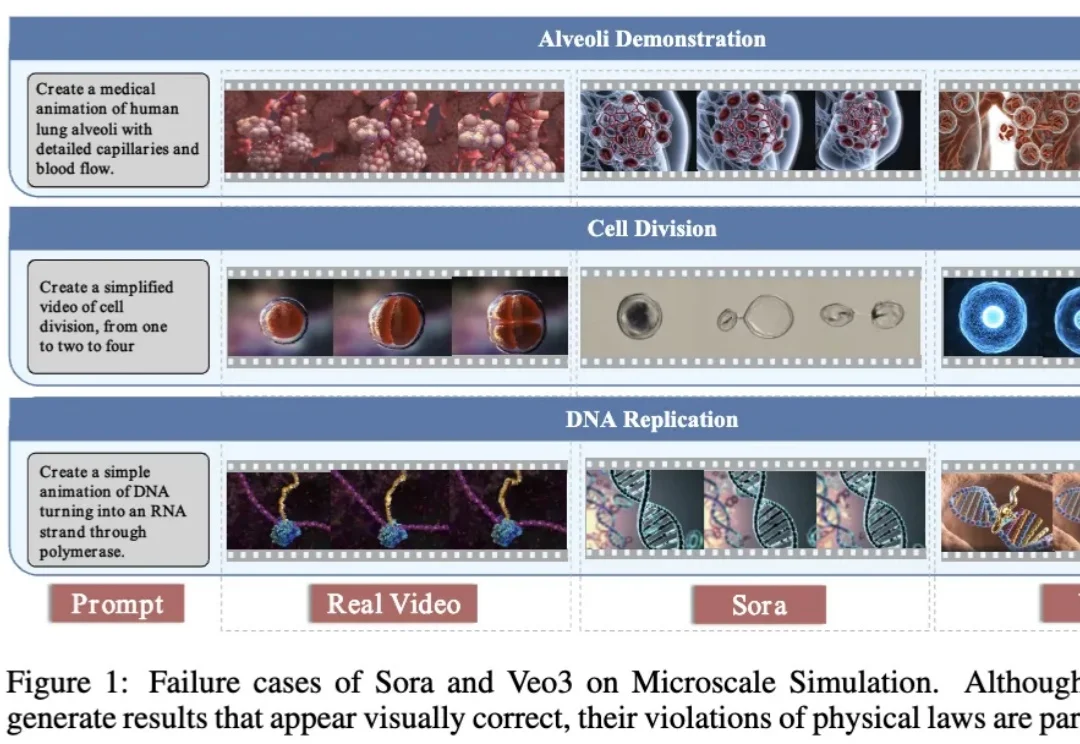
过去两年,世界模型(World Model)正在成为大模型演进的重要方向。

十亿参数单细胞基础模型scLong不再只看少数高表达基因,而是把一个细胞里接近 2.8 万个基因 都纳入建模,并结合 Gene Ontology(GO) 的生物学知识,去理解更完整的基因上下文。
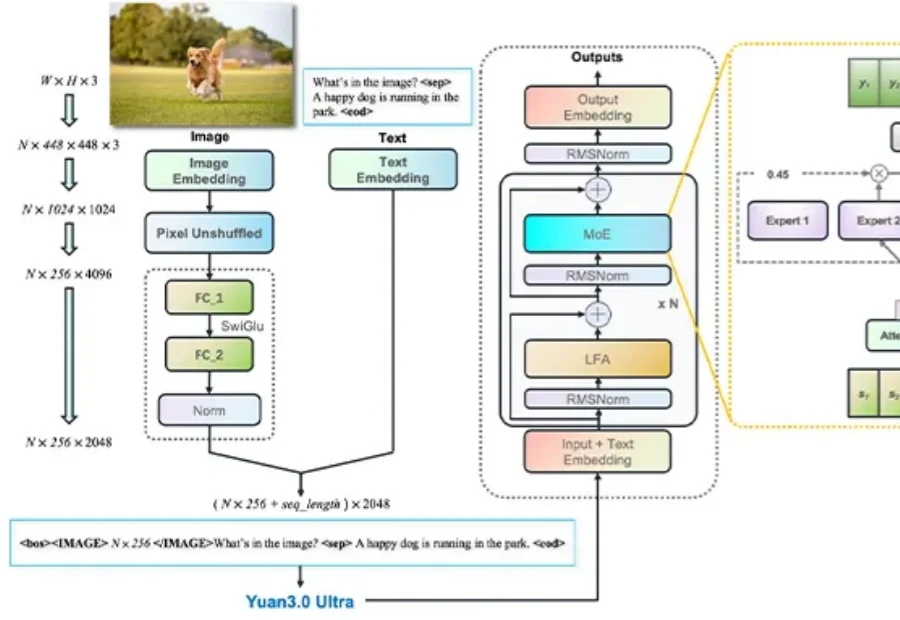
告别Token老虎,给大模型来了个“减脂增肌”。