
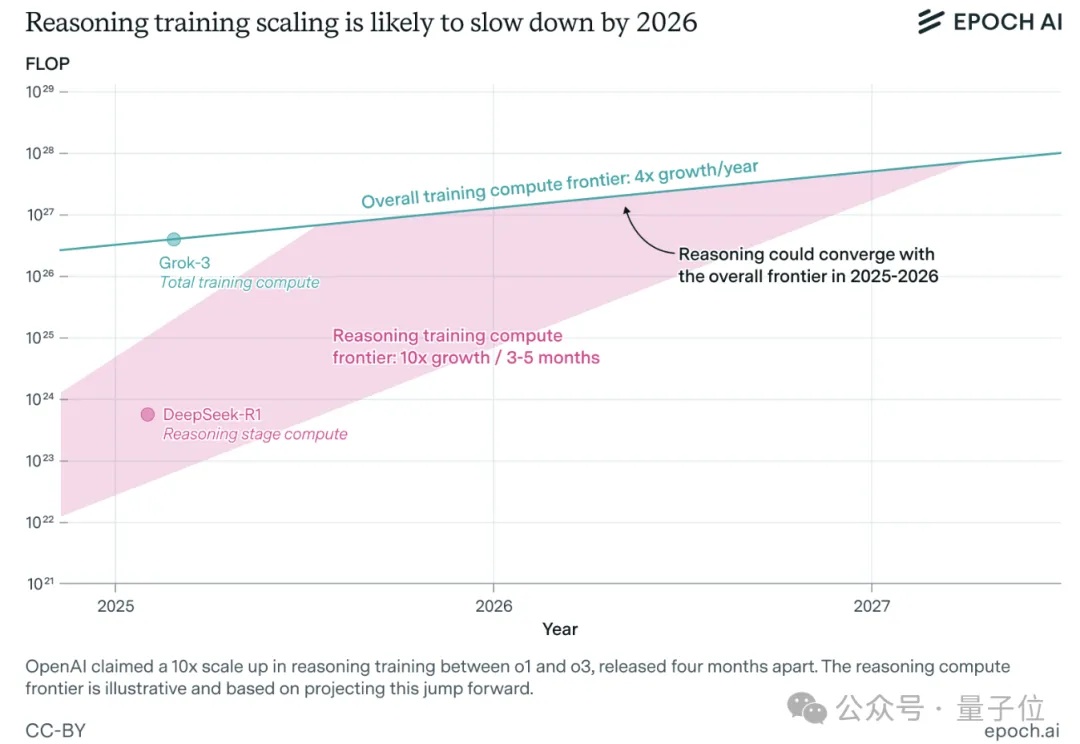
推理大模型1年内就会撞墙,性能无法再扩展几个数量级 | FrontierMath团队最新研究
推理大模型1年内就会撞墙,性能无法再扩展几个数量级 | FrontierMath团队最新研究一年之内,大模型推理训练可能就会撞墙。
来自主题: AI资讯
9775 点击 2025-05-14 11:08
一年之内,大模型推理训练可能就会撞墙。

在多模态大模型快速发展的当下,如何精准评估其生成内容的质量,正成为多模态大模型与人类偏好对齐的核心挑战。然而,当前主流多模态奖励模型往往只能直接给出评分决策,或仅具备浅层推理能力,缺乏对复杂奖励任务的深入理解与解释能力,在高复杂度场景中常出现 “失真失准”。

AI大模型“六小虎”之一的月之暗面,近期对AI医疗产品进行了布局,用于提升旗下产品Kimi在专业领域的搜索质量,并且探索Agent等产品方向。针对上述信息,月之暗面回应《智能涌现》:Kimi近期持续在优化财经、法律、医学等专业领域的搜索信源质量,希望给用户提供更可信、可靠的高质量回答。
还记得刘慈欣在《全频带阻塞干扰》中描绘的耀斑爆发吗?
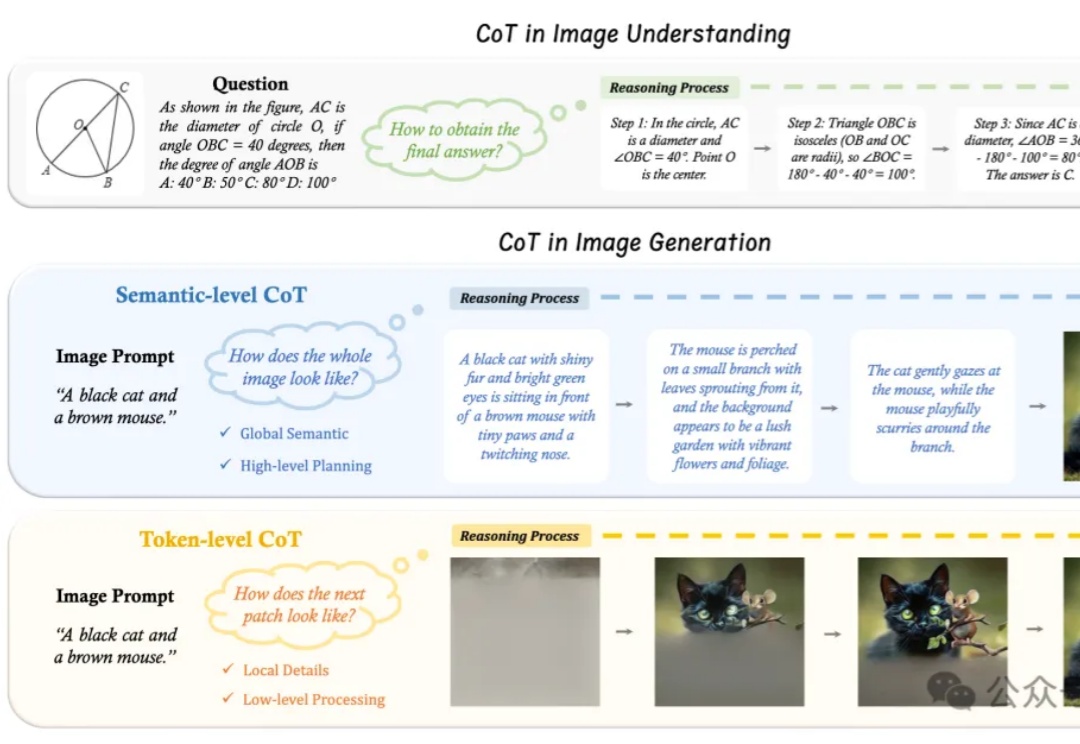
“先推理、再作答”,语言大模型的Thinking模式,现在已经被拓展到了图片领域。
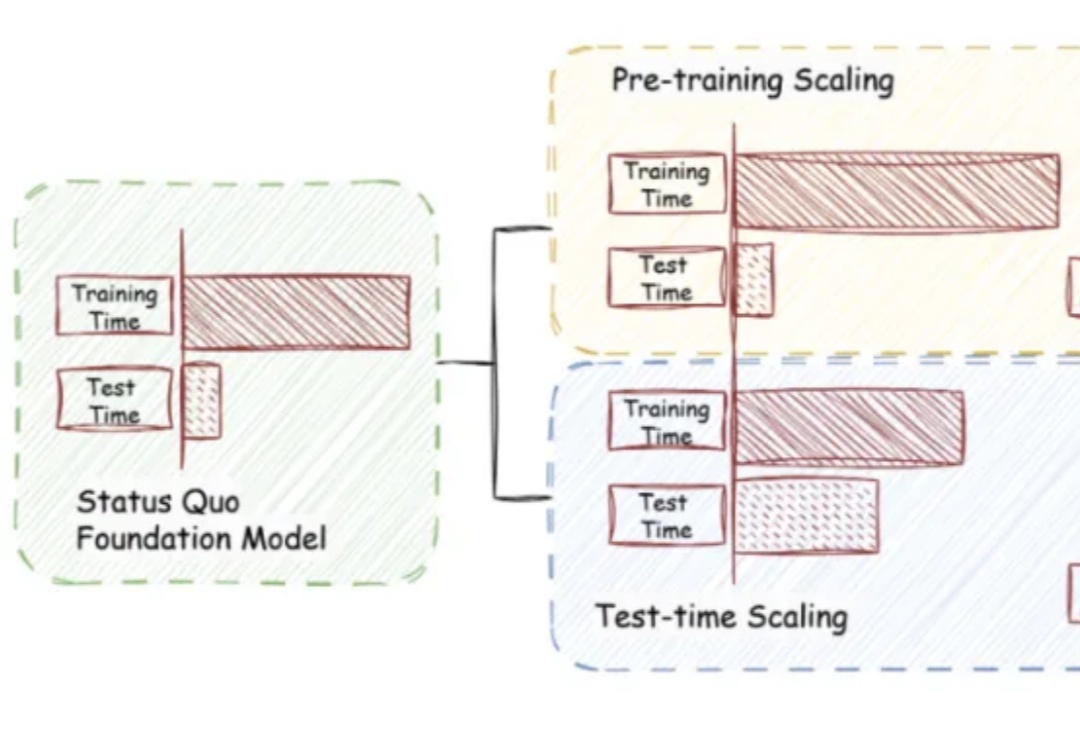
当训练成本飙升、数据枯竭,如何继续激发大模型潜能?

各种AI模型在刚问世时,总有一个屡试不爽的“秀肌肉”手段,那就是让自家AI独立游玩某款游戏,用以检验模型的智能程度。

Cathie’s Letter :滚动衰退下的劳动力“囤积”与技术就业前景

中国基础大模型市场,彻底变天了!如今牌桌上的玩家已经变成了「基模五强」——字节、阿里、阶跃星辰、智谱和DeepSeek。接下来的巅峰之战,关键制胜点又会在哪里?

AI 不允许有人不会搭乐高。