# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
还记得刘慈欣在《全频带阻塞干扰》中描绘的耀斑爆发吗?
现在科幻照进现实,人类踏出了理解耀斑的重要一步——预测。

来自紫东太初和中国科学院国家天文台的研究团队,联合开发了天文耀发预测大模型FLARE (Forecasting Light-curve-based Astronomical Records via features Ensemble)。
该模型能精准预测恒星耀发事件,为天文学研究提供了全新的有力工具,也展示了AI for Science在天文学领域的巨大潜力。
相关研究论文已成功被人工智能领域国际顶级会议IJCAI 2025录用。

以下是更多详细内容介绍。
恒星耀发是恒星大气中磁场能量的快速释放过程,对于理解恒星结构、演化、磁活动以及探索系外宜居行星和外星生命意义重大。
然而,目前通过观测获得的耀发样本数量有限,难以满足全面深入的研究需求。
因此,准确预测恒星耀发时间成为天文学研究的重要任务,但此前这一领域一直缺乏相关研究成果。
与相对容易预测的太阳耀斑不同,恒星耀发预测主要依赖光变曲线。
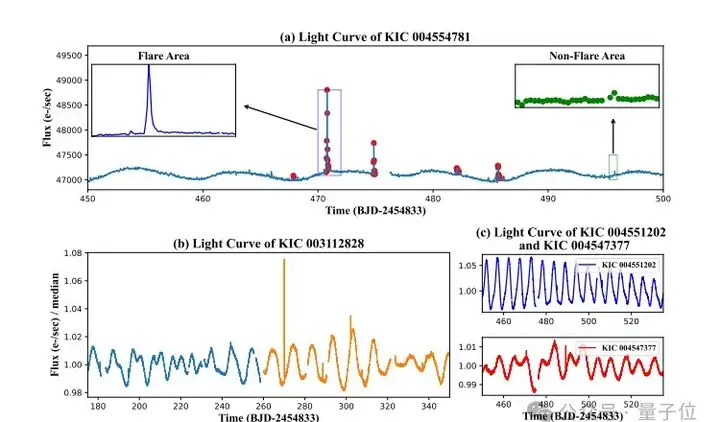
△恒星的光变曲线
光变曲线不仅常存在数据缺失问题,而且不同恒星、同一恒星在不同时期的光变曲线变化趋势差异极大,这些复杂因素给预测工作带来诸多挑战。
在此背景下,紫东太初研究团队与国家天文台联合开展研究。
他们发现,恒星的物理属性(如年龄、自转速度、质量等)以及历史耀发记录,与恒星耀发存在显著关联。
基于此,双方合作开发了FLARE模型。
该模型通过独特的软提示模块 (Soft Prompt Module)和残差记录融合模块 (Residual Record Fusion Module),有效整合了恒星物理属性和历史耀发记录,提升了光变曲线特征提取能力,进而提高了耀发预测的准确性。
在模型架构方面,FLARE首先将光变曲线分解为趋势和残差成分,利用移动平均法去除数据缺失的影响,分别对其进行处理,并通过残差记录融合模块将历史耀发记录融入残差中,增强模型的稳健性。
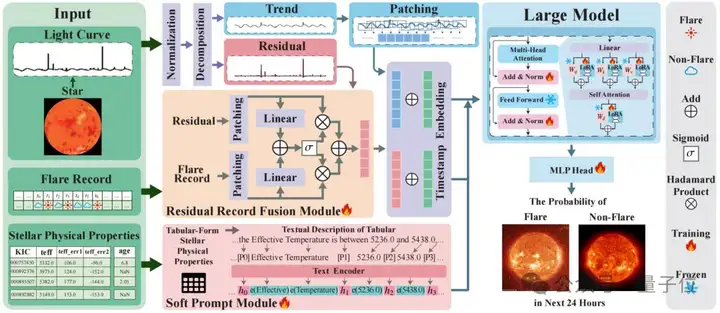
△天文耀发预测大模型FLARE的整体结构图
对于恒星物理属性,软提示模块将属性名称和数值组织成文本结构,借鉴P-tuning方法,部分替换词向量为可训练参数,更好地保留了物理属性的意义,有助于区分不同恒星。
此外,研究团队采用预训练大模型,并利用低秩微调LoRA技术对模型进行微调,使其能够同时处理文本和光变曲线数据,最终通过多层感知器预测未来24小时内恒星耀发的概率。
为验证FLARE模型的性能,研究人员使用7160颗恒星的高精度光变曲线数据进行实验。
他们将FLARE模型与多种基线模型对比,涵盖了基于时间序列表示学习的各类方法,如多层感知器 (MLPs)、循环神经网络 (RNNs)、卷积神经网络 (CNNs)、图神经网络 (GNNs)、Transformer,以及基于预训练语言大模型的时间序列分析方法。
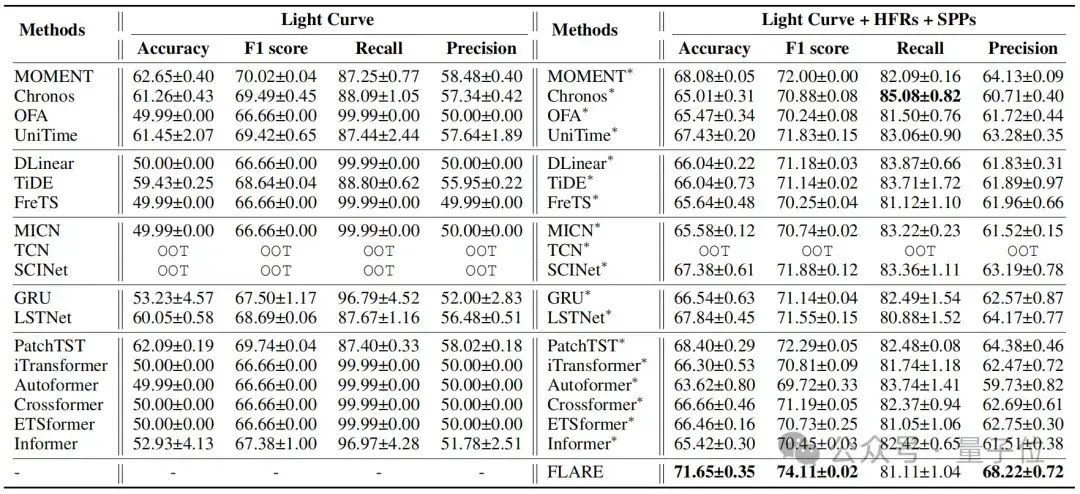
△FLARE模型与多种基线模型的对比结果
实验结果显示,FLARE模型在准确率、F1值、召回率、精度等多项评估指标上表现优异,准确率超过70%,显著优于其他模型。
通过具体实例研究,FLARE模型展现出强大的适应性。
它能够根据不同恒星的光变曲线变化模式,准确预测耀发事件,即使是同一恒星不同变化模式的光变曲线,也能实现精准预测。
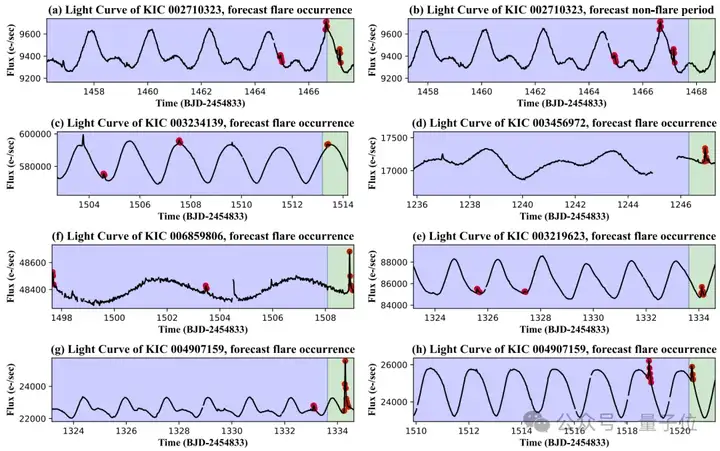
△FLARE模型对多个样本耀发预测结果
未来,随着研究的深入,FLARE模型有望在天文研究中发挥更大作用,助力科学家们探索更多宇宙奥秘。
论文链接:https://arxiv.org/abs/2502.18218
文章来自于“量子位”,作者“FLARE团队”。



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
