

Qwen开源首个长文本新模型,百万Tokens处理性能超GPT-4o-mini
Qwen开源首个长文本新模型,百万Tokens处理性能超GPT-4o-mini谈到大模型的“国货之光”,除了DeepSeek之外,阿里云Qwen这边也有新动作——首次将开源Qwen模型的上下文扩展到1M长度。
来自主题: AI资讯
8968 点击 2025-01-27 14:18
谈到大模型的“国货之光”,除了DeepSeek之外,阿里云Qwen这边也有新动作——首次将开源Qwen模型的上下文扩展到1M长度。

最近,AI界被推理模型刷屏了。国内各家的推理模型,在新年到来之际不断刷新我们的认知。不过,当我们在实际应用中考量大模型,衡量好不好用的标准,就绝不仅仅局限于其性能和规模了。

研究人员首次探讨了大型语言模型(LLMs)在问题生成任务中的表现,与人类生成的问题进行了多维度对比,结果发现LLMs倾向于生成需要较长描述性答案的问题,且在问题生成中对上下文的关注更均衡。

实际上 Operator 只是最近一段时间,全球大模型公司智能体集中发布浪潮的一部分。早于 Operator 发布前两天,字节跳动豆包大模型团队就已经公布了同类型智能体:UI-TARS。

2023年的大模型市场是昂扬的、争先恐后的。2024年的大模型市场是放缓的、冷静取舍的。而在春节前的这一周多时间里,大模型公司们似乎回到了两年前的兴奋状态,一天不止一个重大发布。

1月23日,在第55届世界经济论坛(冬季达沃斯)上,“深度学习”三巨头之一、图灵奖得主、Meta AI首席科学家杨立昆(Yann LeCun),如此对腾讯新闻《一线》透露Meta2025年在AI领域的投资规模。

千诀的大模型已经在多个场景实现了落地,并与多家互联网巨头、3C巨头客户展开了合作。
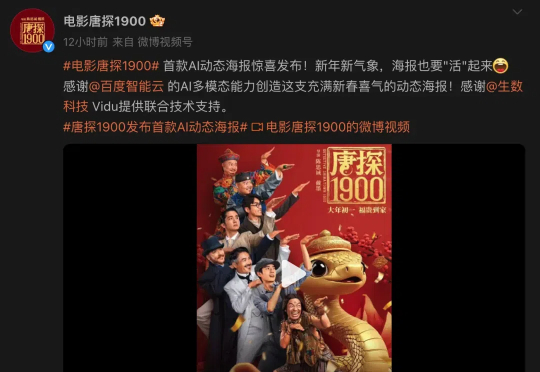
从《唐探1900》官方微博发布的消息来看,这是电影圈里首款AI动态海报,先来看下效果:不止是在网上,甚至是在北京王府井、上海南京路,以及成都春熙路上,都已经开始播放这个AI海报了!

就在刚刚,网上已经出现了一波复现DeepSeek的狂潮。UC伯克利、港科大、HuggingFace等纷纷成功复现,只用强化学习,没有监督微调,30美元就能见证「啊哈时刻」!全球AI大模型,或许正在进入下一分水岭。

文库业务已经成为百度AI的新火种。去年世界大会,文库被提及顺序领先于文心一言。2025年的第一天,百度成立25周年之际,李彦宏的内部信通篇不提文心一言,反而专门为文库留下了一句“在大模型应用领域独树一帜”的评价。