# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
谷歌又有新的注意力了!
他们提出的新架构参数减少40%,训练速度较RNN提升5-8倍,在某些任务上性能甚至Transformer好7.2%!
在大语言模型(LLMs)中,他们引入了新的注意力偏向策略,并重新构想了「遗忘」这一过程,用「保留」来取而代之。

所谓的「注意力偏向」现象,是指人类天然倾向于优先处理特定事件或刺激
受人类认知中的「关联记忆」(associative memory)与「注意力偏向」(attentional bias)概念启发,谷歌的团队提出了统一视角:
Transformer与RNN,都可以被看作是优化某种「内在记忆目标」(即注意力偏向),从而学习键值映射的关联记忆系统。
他们发现:
为此,他们把这一切都被整合进了名为Miras的新框架中,提供四个关键设计维度,指导下一代序列模型的构建。
1. 记忆架构— 如何构建记忆,决定了模型的记忆能力,比如向量、矩阵、MLP等
2. 注意力偏向— 模型如何集中注意力,负责建模潜在的映射模式
3. 保留门控— 如何平衡学习新概念和保留已学概念
4. 记忆学习算法— 模型如何训练,负责记忆管理,比如梯度下降、牛顿法等
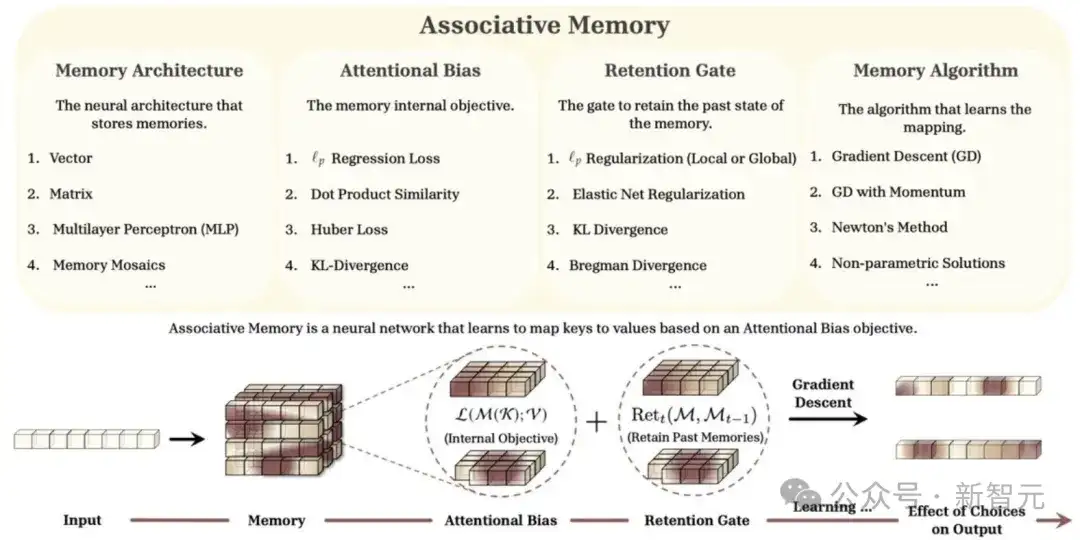
图1:Miras框架概述
这次他们,一口气提出了三种新型序列模型,在某些任务上甚至超越了超越Transformer。
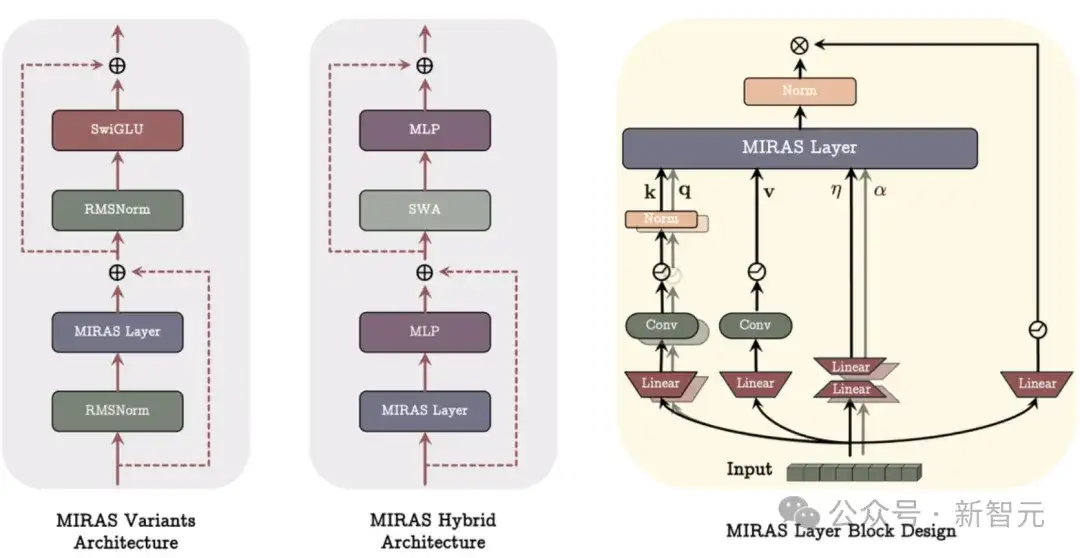
这三种新模型——Moneta、Yaad和Memora,超越了现有线性递归神经网络的能力,同时保持快速可并行训练的过程。
新模型各有所长,在特定任务中表现卓越:
· Moneta:在语言建模任务中PPL指标提升23%
· Yaad:常识推理准确率达89.4%(超越Transformer7.2%)
· Memora:记忆密集型任务召回率提升至91.8%
在多个任务上,新模型提升明显:
• 在PG19长文本建模任务中,参数量减少40%情况下保持相当性能
• 线性计算复杂度使训练速度较传统RNN提升5-8倍
• 在CLUTRR关系推理基准上创造92.3%的新SOTA纪录

论文链接:https://arxiv.org/abs/2504.13173
模型没有失忆,但也有问题
研究者定义并形式化了注意力偏向的概念,作为序列模型的内部记忆目标,旨在学习输入(即键和值)之间的潜在映射。
广义上讲,关联记忆是将一组键K映射到一组值V的操作符(Operator)。
为了学习数据中的潜在映射模式,它需要一个目标,该目标针对某种类型的记忆并衡量学习到的映射质量:

研究人员不再用「遗忘」(forget)这个词,而是提出了「保留」(retention)的概念。
因此,「遗忘门」(forget gate)也就变成了「保留门」(retention gate)。
模型并不会真的清除过去的记忆——
它只是选择对某些信息不那么「上心」而已。
此外,研究人员提供了一套全新的替代保留门控(忘记门)用于序列模型,带来了新的洞察,帮助平衡学习新概念和保留先前学到的概念。
现有的深度学习架构中的遗忘机制,可以重新解释为一种针对注意力偏向的ℓ₂正则化。
比如,softmax注意力是Miras的一个实例,利用Nadaraya-Watson估计器找到MSE损失的非参数解时,无需保留项。

论文链接:https://arxiv.org/abs/2407.04620
实际上,这次谷歌团队发现大多数现有模型(如Transformer、RetNet、Mamba等)都采用了类似的注意力偏向目标,即尝试最小化键值对之间的ℓ₂ 范数(均方误差)。
但它存在几个问题:
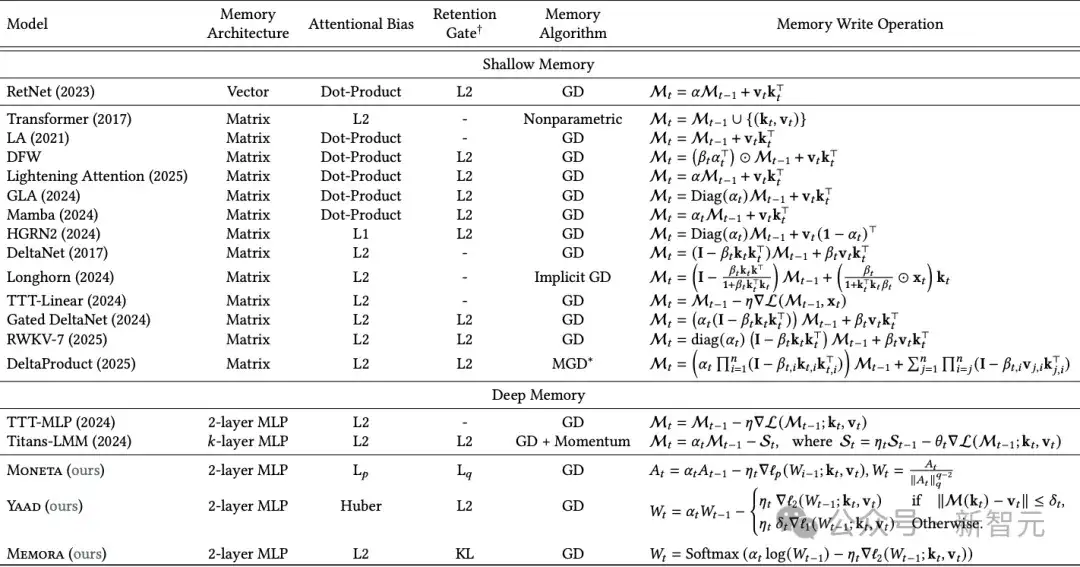
表1:基于Miras框架视角的近期序列模型概览
目标函数:注意力偏向策略
基于关联记忆概念的神经架构设计,被转化为学习键值之间的基本映射,可以利用最小化目标函数L来实现:
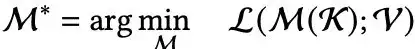
为了求解上述优化问题,最简单的方法就是利用梯度下降。
具体来说,给定一对新的键值对,可以通过以下方式更新记忆(一下叫做更新方程):
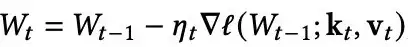
这一公式可以被重新解释为一种瞬时惊讶度度量,其中模型记忆那些违反目标预期的token。
更新方程可以看作是在线梯度下降的一步,涉及损失函数序列的优化:
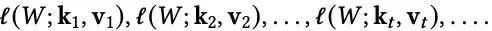
众所周知,在线梯度下降可以被视为跟踪正则化领导者(Follow-The-Regularized-Leader, FTRL) 算法的一个特例。
这其实对应于某些特定选择的损失函数。
具体来说,假设W₀ = 0,则更新方程中的更新规则等价于下列方程(以后称为二次更新方程):
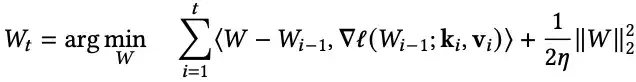
以上方程使用了损失函数的线性近似和二次正则化。
然而,从原则上讲,也可以使用其他损失函数的近似以及其他正则化函数。
更具体地说,可以将二次更新方程推广到如下形式:
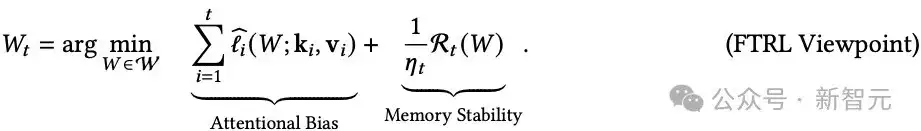
其中:
不同的损失函数和正则化项,对应不同的算法。
在这种情况下,记忆的更新不仅依赖于当前输入数据的特征,还受到记忆结构的影响,正则化项在其中起到了平衡学习和记忆稳定性的作用。
Miras提出的三类新型注意力偏向策略。
ℓₚ范数:记忆精度可调
如正文所述ℓ2回归损失通常是自然选择,但其对数据噪声较为敏感。
自然的扩展是采用ℓ𝑝范数目标函数类。
具体而言,设M为记忆模块,k为键集合,v为值集合,ℓ𝑝注意力偏向定义为:
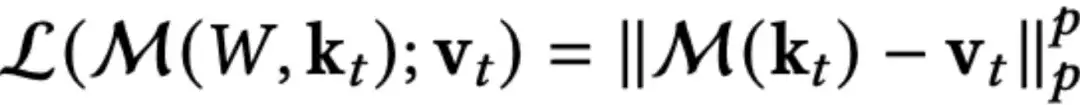
不同的范数对应对噪声的敏感度:
ℓ₁更抗异常值,
ℓ₂是常规选择,
ℓ∞ 聚焦于最大误差。
Huber损失:「应对异常」心理机制
Huber损失具备容错机制的记忆模块。
尽管ℓ2范数目标是许多统计与机器学习任务的常见选择,但其对异常值和极端样本的敏感性众所周知。
这种敏感性同样存在于将ℓ2损失用于注意力偏向的场景。
为解决该问题,并借鉴稳健回归的思路,研究者建议采用Huber损失类型作为注意力偏向,从而降低异常数据对记忆学习过程的负面影响。
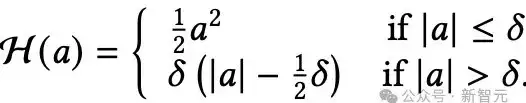
Huber损失结合了ℓ₂(正常情况下)和ℓ₁(出现大误差时),在面对异常值时也能保持学习的稳定性。
鲁棒优化:考虑最坏情况
鲁棒优化(Robust Optimization)的核心思想:最小化最坏情况下的损失;在一个不确定性集合(uncertainty set)内优化性能。
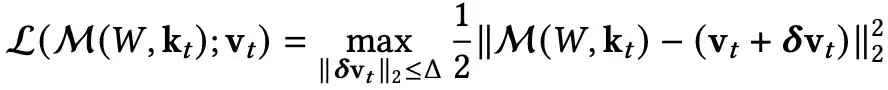
类似「备份记忆」策略——即使现实偏离,也不崩盘。
鲁棒优化使模型在输入有小幅变动时也能保持稳定。
正则化:保留门策略
在多数传统模型中(如 LSTM、Mamba、Transformer),信息的遗忘或记忆更新是隐式的,模型只是不断地「覆盖」旧状态。
但现实中,大家知道:
并不是所有信息都值得被长期记住,有些应该快速遗忘,有些则必须深深保留。
因此,Miras 框架提出了一个明确的设计目标:
引入可控的、可设计的保留机制 Retention Gate,使模型显式判断是否保留旧记忆。
这就是Retention Gate的作用核心。
另一种解读的方法是,将更新方程视为从最新的键值对(kᵢ, vᵢ)中学习(通过使用其梯度或惊讶度度量),同时保持接近先前状态 Wᵗ₋₁,以保留先前记忆的token。
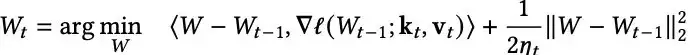
这种形式可以推广为:
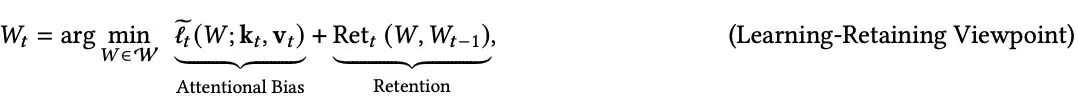
其中,右侧第一项是ℓ(W; k_t, v_t) 的近似,最小化它对应于从新概念(kₜ, vₜ)中学习。
第二项则对W的变化进行正则化,以使学习动态稳定,并保留先前学到的知识。
Retention函数可能包括局部和全局组件:
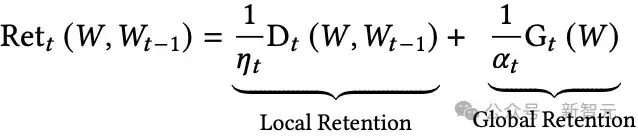
其中:
从目标函数角度,保留门对应正则项。
基于概率的机制:将记忆处理为概率分布(比如用KL散度)来保持其稳定性。
弹性网(Elastic net):结合了软遗忘(ℓ₂)和硬遗忘(ℓ₁)的方法。
Lq稳定性:可调节记忆对变化的抵抗程度。
Bregman散度:引入非线性、能感知数据结构形状的记忆更新方式。
三个新模型
研究人员利用 Miras 框架构建了三个新模型:
• Moneta —— 灵活且表达力强。它采用可定制的 ℓp/ℓq范数来灵活控制记忆更新的精度。
• Yaad —— 抗噪和抗极端值能力强。它使用Huber损失和自适应更新机制来保持模型的稳定性。
• Memora —— 稳定且规范的记忆控制。它通过KL散度和Softmax更新方法,确保记忆在合理范围内波动。
在实验中,这些新模型在以下任务中表现优于现有最强模型: 语言理解、常识推理、发现罕见事实(像「大海捞针」那样找出隐藏信息)、 在长文本中保留细节信息。
实验表明,Miras中的不同设计选择产生了具有不同优势的模型。
Moneta专注于记忆更新中的可定制精度,使用灵活的ℓₚ/ℓq 范数。
Yaad使用Huber损失和自适应更新来保持稳定性。
Memora利用KL散度和Softmax更新来保持记忆的边界。
实验结果
首先关注语言建模中的困惑度(perplexity)以及常识推理任务的表现。
研究者在表2中报告了Memora、Yaad、Moneta三个模型变体,以及一些基准模型(参数量为340M、760M 和 1.3B)的结果。
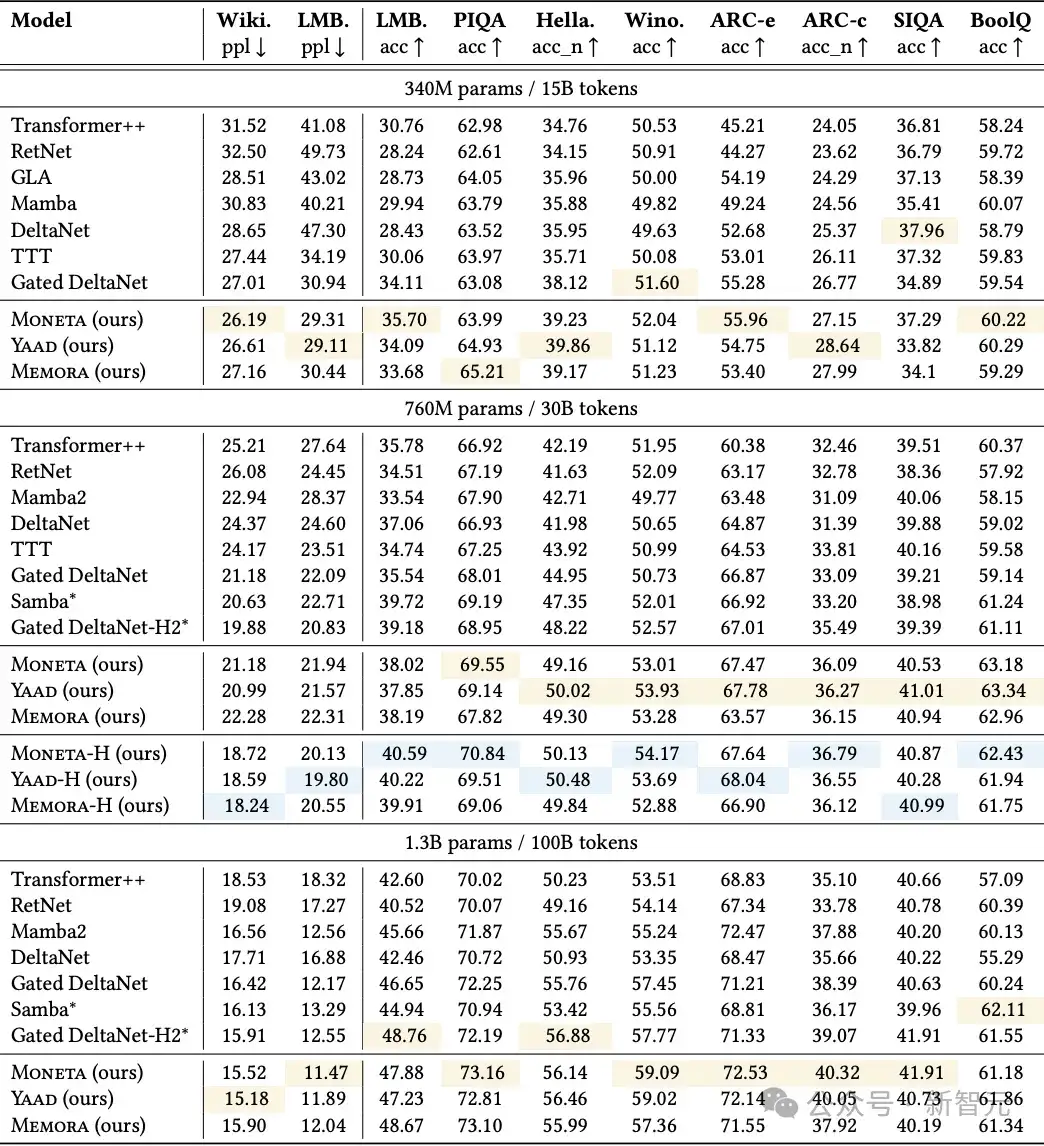
表2:Miras各个变体与基准模型在语言建模和常识推理任务中的表现。带有*标记的为混合模型,高亮的内容是表现最好的纯模型和混合模型
所有模型变体都优于包括Transformer++、现代线性递归模型和混合方法在内的全部基准方法。
尤其是在与混合模型的比较中取得更好表现更为关键,因为所有模型变体都是纯递归结构(完全不依赖注意力机制)。
在Miras的三个变体中,虽然Moneta的表现略逊于Memora和Yaad,但这三者的差距并不大,且具体哪个模型效果最好会因任务类型和模型大小而异。
扩展模式分析(Scaling Pattern)
为了评估新模型的扩展能力,并与基准模型做对比,研究者绘制了模型在不同大小和上下文窗口下的性能变化图。
上下文长度
研究者将训练时使用的上下文长度从2K扩展到32K,分别在模型大小为340M和760M的两个版本上进行实验。结果如图3中间和右侧所示。
Miras的三个变体在上下文长度增加时的扩展能力均优于当前最先进的基准模型。
这种性能优势主要来自两个方面:
(1) 更强表达能力的记忆结构。与Mamba2和GSA这些使用向量或矩阵形式记忆的基准模型不同,新模型变体使用了两层的多层感知机(MLP),能更有效地学习长序列信息;
(2) 保留门(retention gate)和注意力偏向的设计:新的模型突破了传统做法,这有助于更高效地管理固定容量的记忆。
模型大小
研究者还在图3左侧展示了模型的计算量(FLOPs)与困惑度的关系。
在相同的 FLOPs(计算预算)下,三个模型变体的表现都超过了所有基准模型。再次证明了强大的记忆机制设计对模型性能的重要性。

图3:在C4数据集上扩展模型规模和序列长度时的表现趋势。(左)随着模型规模增加的表现;(中)在模型规模为340M时,序列长度增加带来的影响;(右)在模型规模为760M时,序列长度增加带来的影响
大海捞针任务(Needle In Haystack)
为了评估模型在处理长文本时的有效上下文能力,研究者采用了「大海捞针」(Needle In Haystack)任务。
在「大海捞针」任务中,模型需要从一段很长的干扰文本中找出一条特定的信息(即「针」)。
在RULER基准中的S-NIAH(单一大海捞针)任务,在文本长度分别为1K、2K、4K和8K的情境下对新模型和基准模型进行测试,结果见表3。
所有模型变体都以显著优势超过了所有基准模型。
值得注意的是,在处理合成噪声数据(S-NIAH-PK)时,Moneta 的表现优于其他模型。这一发现说明 𝑝-范数目标函数和保留门机制在噪声环境下更具鲁棒性,能更好地保持模型性能。
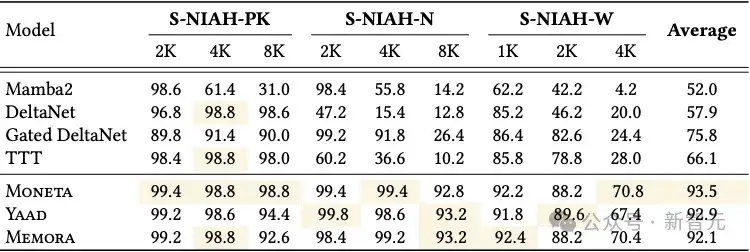
表3:Moneta、Yaad、Memora以及基准模型在RULER中的NIAH任务上的表现。最佳结果用高亮表示。
更多细节和理论推导,请参阅原文。
作者介绍
Peilin Zhong目前是谷歌纽约的算法与优化团队的研究科学家。
他在哥伦比亚大学获得了博士学位。
在此之前,他曾是清华大学跨学科信息科学研究院(姚班)的本科生。
他的研究兴趣广泛,主要集中在理论计算机科学领域,特别是算法的设计与分析。
具体包括并行算法和大规模并行算法、隐私算法、压缩算法、流式算法、图算法、机器学习、高维几何、度量嵌入、数值线性代数、聚类以及与大规模数据计算相关的其他算法。
参考资料:
https://arxiv.org/abs/2504.13173
https://x.com/TheTuringPost/status/1914316647386714289
文章来自公众号“新智元”




【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
