
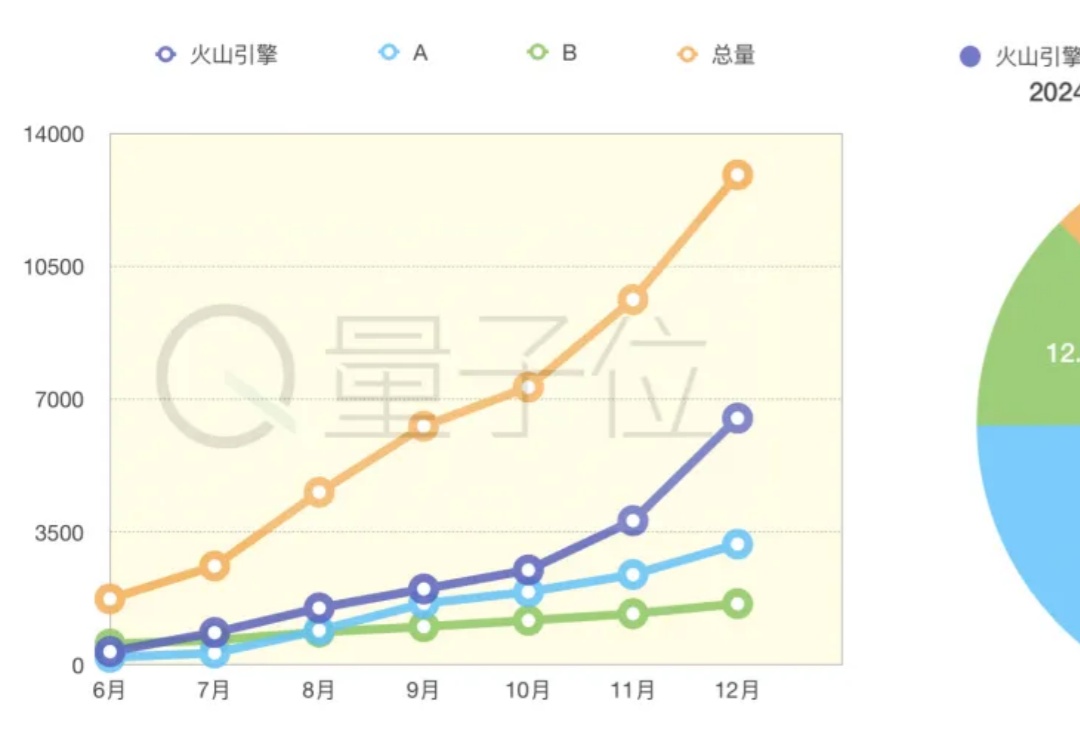
大模型商用格局雏形初现:Tokens用量决高下,火山引擎问鼎2024
大模型商用格局雏形初现:Tokens用量决高下,火山引擎问鼎2024大模型应用落地元年,谁家业务更值得关注?
来自主题: AI资讯
4716 点击 2025-01-22 11:06
大模型应用落地元年,谁家业务更值得关注?
提一个冷知识。

下一代 AI 的发展,似乎遇到了难以逾越的瓶颈。去年 12 月,OpenAI 在 ChatGPT 两周年期间连续发布了 12 天,我们期待的新一代大模型 GPT-5 却从头到尾没有踪影。

代理型人工智能具有显著的潜力。

WaveForms致力于开发音频大模型(LLMs),通过创新的端到端音频处理技术,实现更加实时、类人化且情感智能化的语音交互。与传统语音模型不同,WaveForms的音频模型不是语音转文本再转语音,而是能够直接处理音频,实现更自然的对话和情感互动。
早上MiniMax上线TTS,字节上线AI编程Trae;下午字节全量上线豆包实时语音;晚上DeepSeek开源R1性能直接对标OpenAI o1,然后Kimi的k1.5直接正面硬刚。昨天的余温还没过,今天下午,腾讯混元又悄悄开了个闭门发布会,作为混元的老基友,我自然是受邀参加期期不落。
Grok AI 最近网页版刚刚上线。我看到不少人都在比较 Grok 对标 ChatGPT 等等 LLM 大模型的研究和生成能力。我想说,背靠 X (前推特)数据库的 Grok AI,最好的使用方式难道不是实时监测全球媒体热点吗?

AI具备的能力,本质上来自算法和训练大模型所用的数据,数据的数量和质量会对大模型起到决定性作用。此前OpenAI工作人员表示,因没有足够多的高质量数据,Orion项目(即GPT-5)进展缓慢。不得已之下,OpenAI招募了许多数学家、物理学家、程序员原创数据,用于训练大模型。
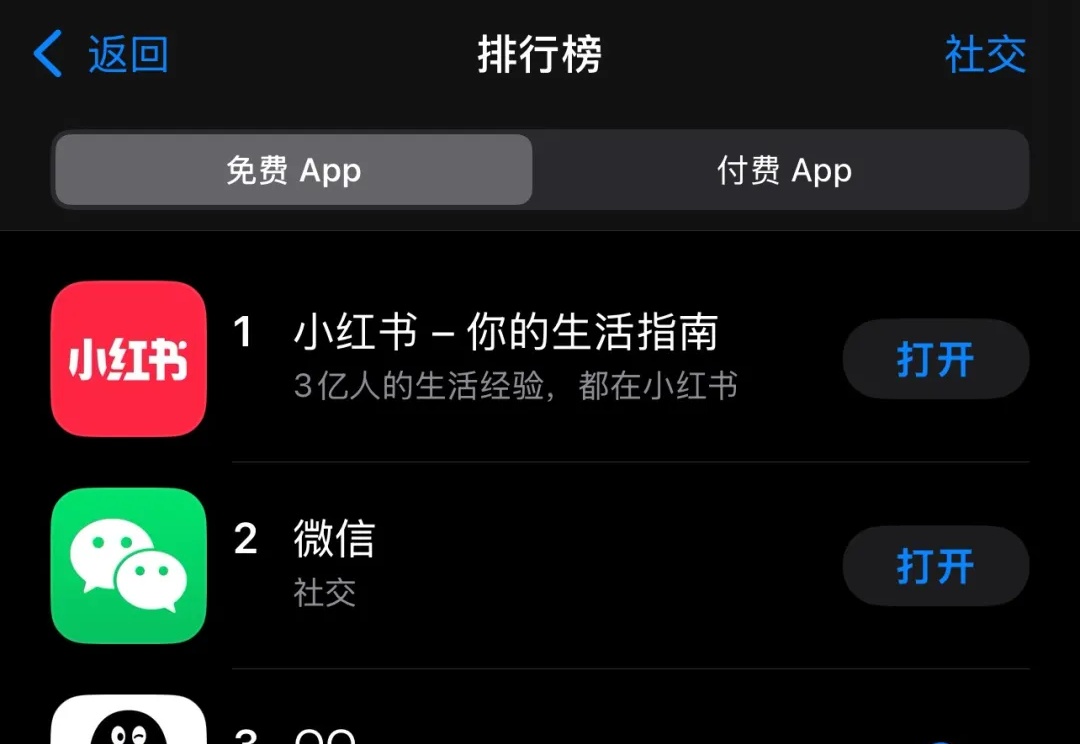
网友盛赞“最有用的大模型应用”,小红书AI翻译功能上线了!(Doge)
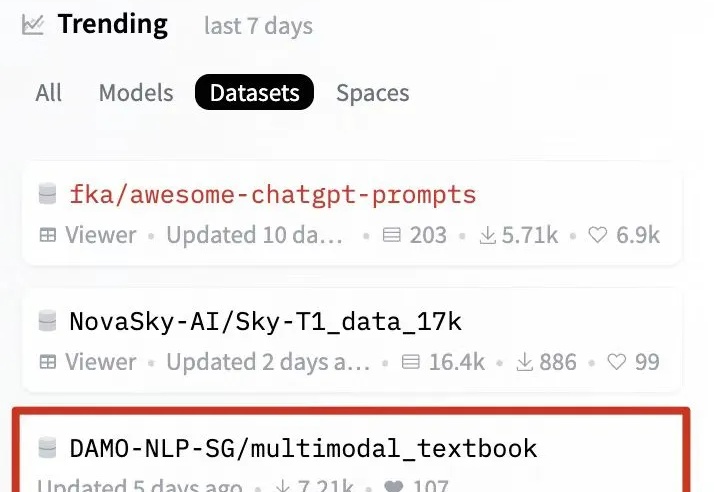
近期关于 scaling law 的讨论甚嚣尘上,很多观点认为 scale law is dead. 然而,我们认为,高质量的 “无监督” 数据才是 scaling law 的关键,尤其是教科书级别的高质量的知识语料。此外,尽管传统的语料快枯竭了,但是互联网上还有海量的视频并没有被利用起来,它们囊括了丰富的多种模态的知识,可以帮助 VLMs 更好好地理解世界。