登顶开源SOTA!上交大&小红书LoopTool实现工具调用任务的「数据进化」
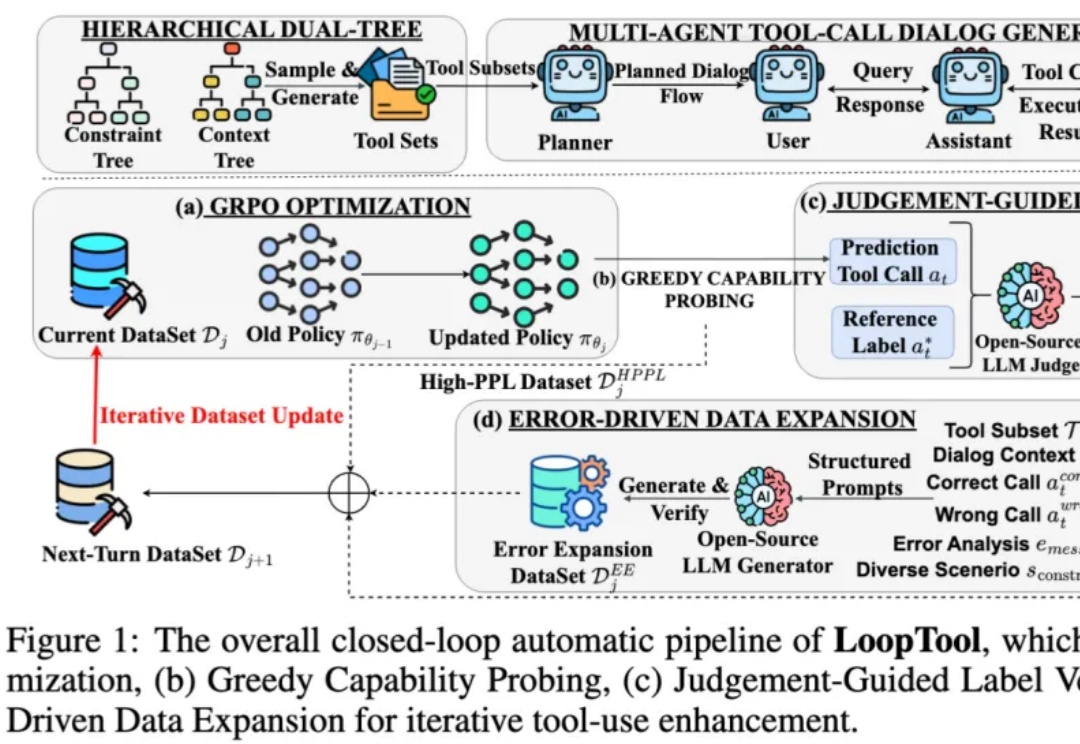
登顶开源SOTA!上交大&小红书LoopTool实现工具调用任务的「数据进化」在过去两年,大语言模型 (LLM) + 外部工具的能力,已成为推动 AI 从 “会说” 走向 “会做” 的关键机制 —— 尤其在 API 调用、多轮任务规划、知识检索、代码执行等场景中,大模型要想精准调用工具,不仅要求模型本身具备推理能力,还需要借助海量高质量、针对性强的函数调用训练数据。
来自主题: AI技术研报
10705 点击 2025-11-19 16:40