

EMNLP2025 | 通研院揭秘MoE可解释性,提升Context忠实性!
EMNLP2025 | 通研院揭秘MoE可解释性,提升Context忠实性!在大模型研究领域,做混合专家模型(MoE)的团队很多,但专注机制可解释性(Mechanistic Interpretability)的却寥寥无几 —— 而将二者深度结合,从底层机制理解复杂推理过程的工作,更是凤毛麟角。
来自主题: AI技术研报
9364 点击 2025-11-17 09:25
在大模型研究领域,做混合专家模型(MoE)的团队很多,但专注机制可解释性(Mechanistic Interpretability)的却寥寥无几 —— 而将二者深度结合,从底层机制理解复杂推理过程的工作,更是凤毛麟角。

人类的下一个分裂,从算法开始。 作者|Moonshot 编辑|靖宇 在生成式 AI 的早期叙事里,AI 大模型曾被描绘得理性、冷静、无偏见。 然而,不到三年时间,这个叙事迅速崩塌。事实正在变得越来越清

从手机、PC、汽车到机器人,我们需要怎样的端侧AI "芯" 思路? 作者 | 云鹏 编辑 | 漠影 机器人走猫步引爆行业、舞蹈功夫如人类般丝滑;AI手机一句话订外卖做报告、懂你所想知你所言;AI PC

智能家居不够“智能”,怎么办?小米集团给出了智能家居未来探索方案Xiaomi Miloco。该方案基于大模型独特的开发范式,用户可以跟智能家居系统对话沟通,经过大模型的推理计算,自动完成家庭生活中的各类智能需求和规则。

今年也是阿里从芯片到云到 PaaS 到大模型,再到顶层 agent 等全栈 AI 能力接入的首个双 11——世界范围内,从未有过如此大规模生产场景 AI 落地。 场景变化,用户量增加,叠加全栈 AI 接入——当双 11 技术备战进入第 17 个年头,其意义早已超越一次促销的技术保障。
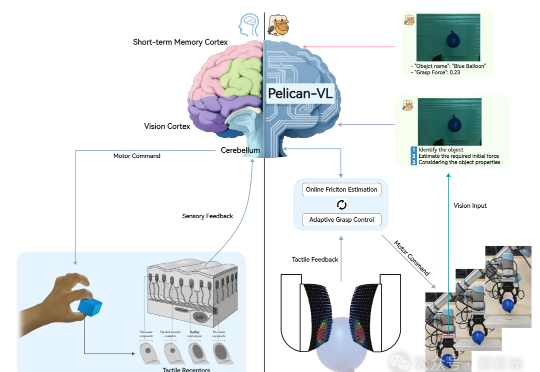
昨天,全球参数量最大的具身智能多模态大模型——Pelican-VL 1.0正式开源。它不仅覆盖了7B到72B级别,能够同时理解图像、视频和语言指令,并将这些感知信息转化为可执行的物理操作。
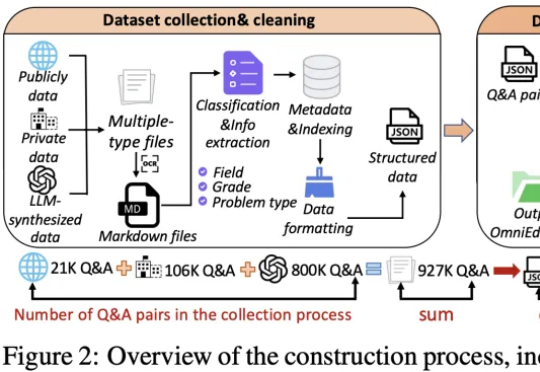
华东师范大学智能教育学院发布OmniEduBench,首次从「知识+育人」双维度评测大模型教育能力。测评2.4万道中文题后,实验结果显示:GPT-4o等顶尖AI会做题,却在启发思维、情感支持等育人能力上远不及人类,暴露AI当老师的关键短板。

刚刚,在理解大模型复杂行为的道路上,OpenAI又迈出了关键一步。他们从自己训练出来的稀疏模型里,发现存在结构小而清晰、既可理解又能完成任务的电路(这里的电路,指神经网络内部一组协同工作的特征与连接模式,是AI可解释性研究的一个术语)。
随着现在的主流大模型都能轻松通过图灵测试,这个持续了数十年的标准开始逐渐过时。奥特曼和量子计算之父David Deutsch讨论得出了一个新的图灵测试2.0标准,可以更好地衡量究竟怎样AI才算拥有真正的智能。
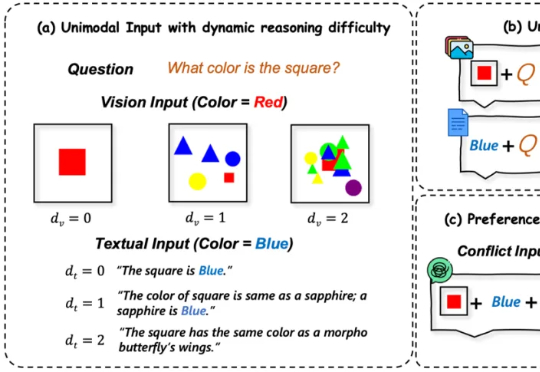
多模态大语言模型(MLLMs)在处理来自图像和文本等多种来源的信息时能力强大 。 然而,一个关键挑战随之而来:当这些模态呈现相互冲突的信息时(例如,图像显示一辆蓝色汽车,而文本描述它为红色),MLLM必须解决这种冲突 。模型最终输出与某一模态信息保持一致的行为,称之为“模态跟随”(modality following)