

文生视频大模型,短视频的过弯点?
文生视频大模型,短视频的过弯点?这次,快手又先字节一步。
来自主题: AI资讯
7481 点击 2024-07-30 12:08
这次,快手又先字节一步。
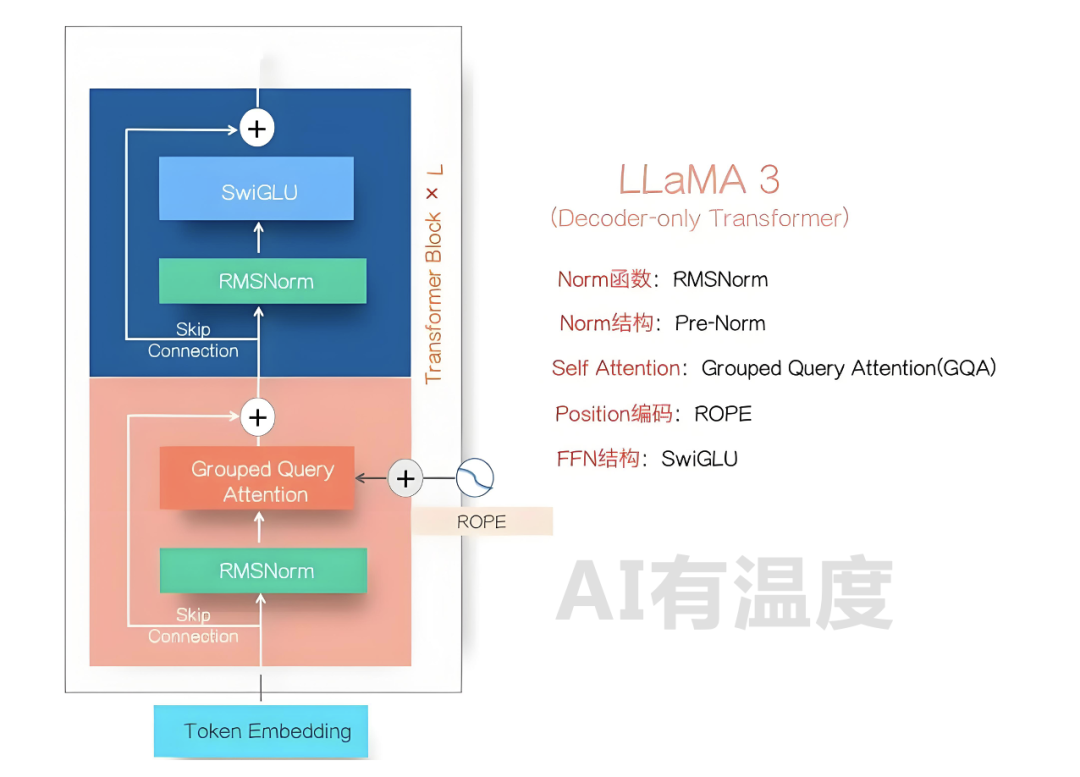
LLaMA3-405B的模型效果已经赶上目前最好的闭源模型GPT-4o和Claude-3.5,这可能是未来大模型开源与闭源的拐点,这里就LLaMA3的模型结构、训练过程与未来影响等方面说说我的看法。

开发和应用大语言模型的杭州波形智能,正式杀入多模态领域。

7月27日,与ICLR(国际学习表示会议)、NeurIPS(神经信息处理系统会议)并称三大机器学习顶级会议的ICML(国际机器学习大会),在奥地利维也纳会展中心落下帷幕。
随着人工智能(AI)技术的迅猛发展,特别是大语言模型(LLMs)如 GPT-4 和视觉语言模型(VLMs)如 CLIP 和 DALL-E,这些模型在多个技术领域取得了显著的进展。

只用1890美元、3700 万张图像,就能训练一个还不错的扩散模型。

2024 年的 AI 图像生成技术,又提升到了一个新高度。
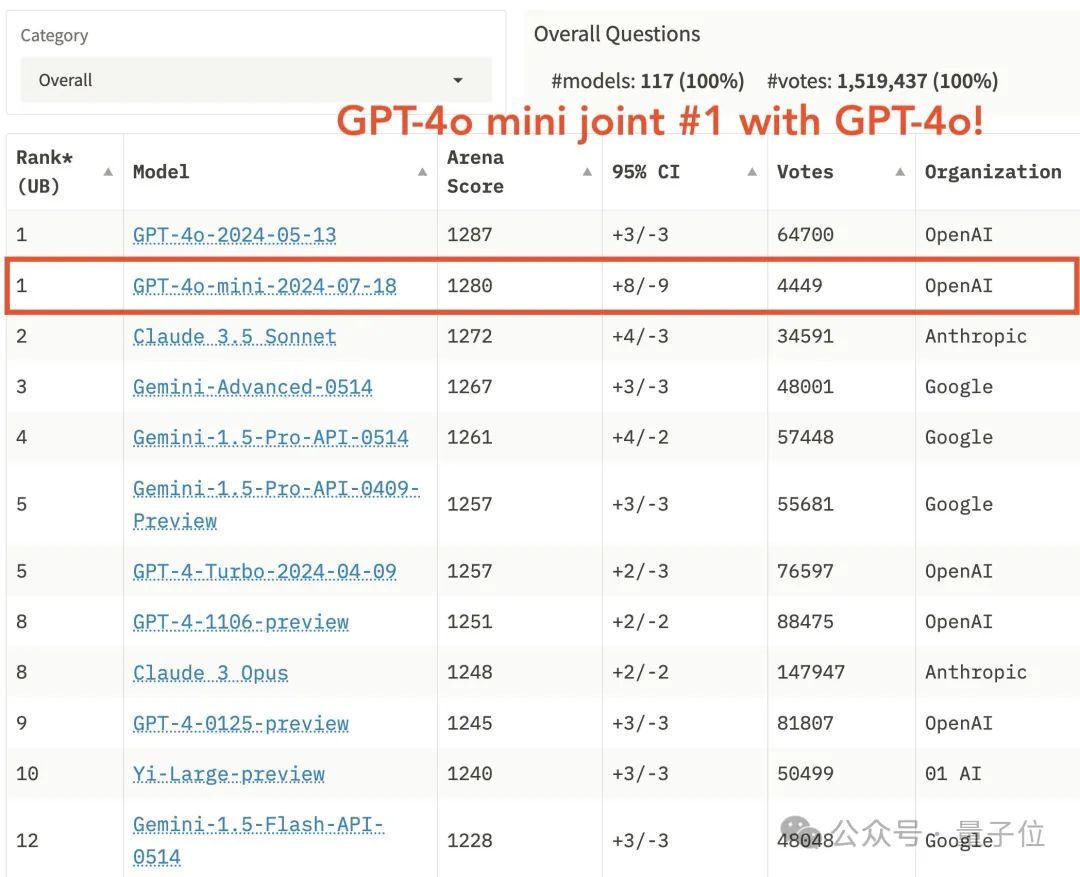
为啥GPT-4o mini能登顶大模型竞技场??

解决问题:语言智能体的动作通常由 Token(令牌,语言模型中表示单词/短语/汉字的最小符号单元)序列组成,直接将强化学习用于语言智能体进行策略优化的过程中,一般需要预定义可行动作集合,同时忽略了动作内 Token 细粒度信用分配问题,团队将 Agent 优化从动作层分解到 Token 层,为每个动作内 Token 提供更精细的监督,可在语言动作空间不受约束的环境中实现可控优化复杂度

不是大模型用不起,而是小模型更有性价比。