

刚刚,智源悟界·Emu3.5重塑世界模型格局,原生具备世界建模能力
刚刚,智源悟界·Emu3.5重塑世界模型格局,原生具备世界建模能力今天,北京智源人工智能研究院(BAAI)重磅发布了其多模态系列模型的最新力作 —— 悟界・Emu3.5。这不仅仅是一次常规的模型迭代,Emu3.5 被定义为一个 “多模态世界大模型”(Multimodal World Foudation Model)。
来自主题: AI资讯
8919 点击 2025-10-30 18:07
今天,北京智源人工智能研究院(BAAI)重磅发布了其多模态系列模型的最新力作 —— 悟界・Emu3.5。这不仅仅是一次常规的模型迭代,Emu3.5 被定义为一个 “多模态世界大模型”(Multimodal World Foudation Model)。

用 iPhone 本地跑大模型已经不是新鲜事了,但能不能在 iPhone 上微调模型呢?
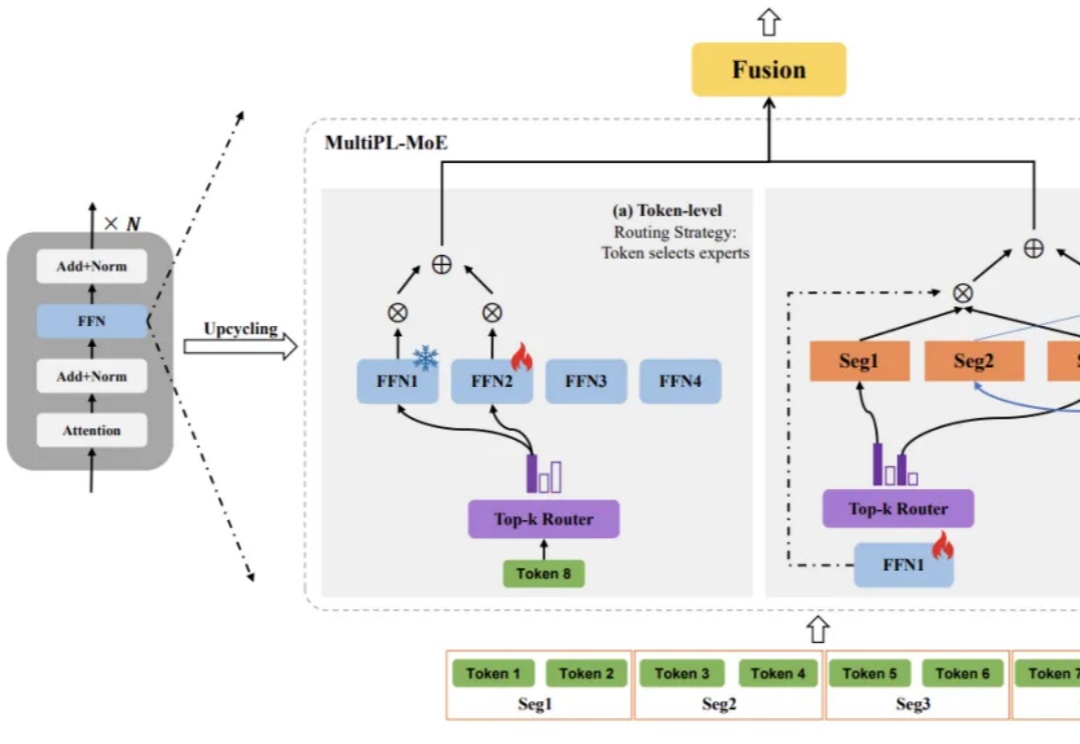
大语言模型(LLM)虽已展现出卓越的代码生成潜力,却依然面临着一道艰巨的挑战:如何在有限的计算资源约束下,同步提升对多种编程语言的理解与生成能力,同时不损害其在主流语言上的性能?

杨红霞要走一条和阿里、字节截然不同的模型训练之路。

具身智能赛道的想象力,远比眼前的机器人要辽阔。
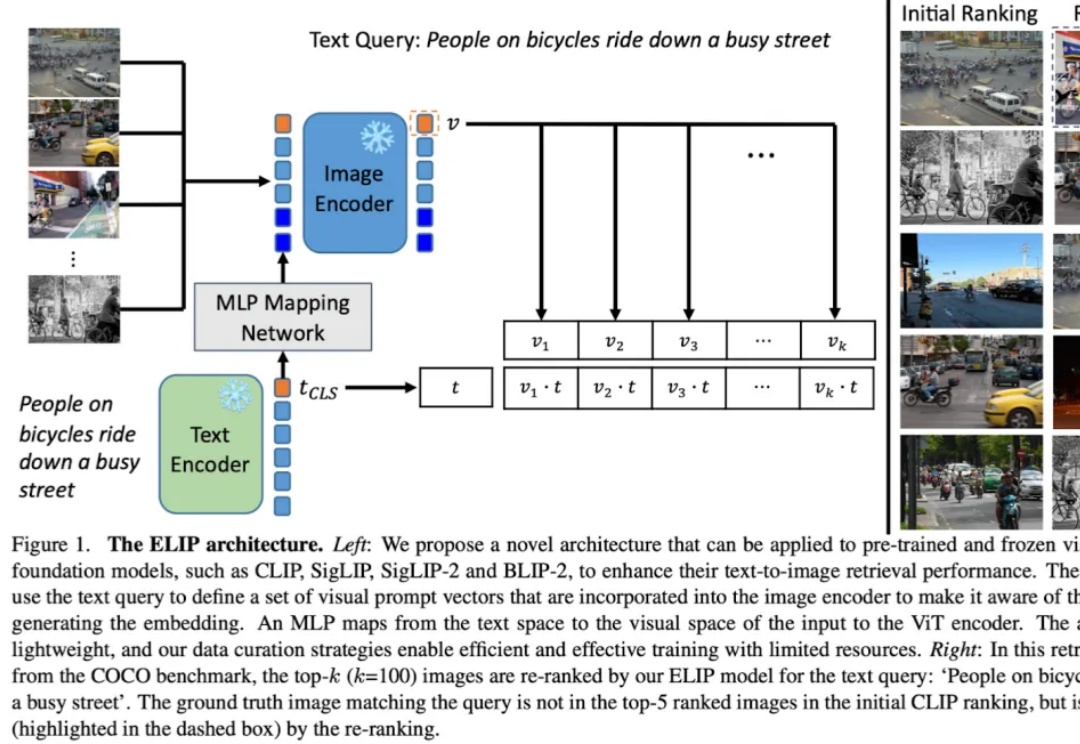
多模态图片检索是计算机视觉和多模态机器学习领域很重要的一个任务。现在大家做多模态图片检索一般会用 CLIP/SigLIP 这种视觉语言大模型,因为他们经过了大规模的预训练,所以 zero-shot 的能力比较强。

最新进展,Cursor 2.0正式发布,并且首次搭载了「内部」大模型。 没错,不是GPT、不是Claude,如今模型栏多了个新名字——Composer。实力相当炸裂:据官方说法,Composer仅需30秒就能完成复杂任务,比同行快400%

大语言模型(LLMs)推理能力近年来快速提升,但传统方法依赖大量昂贵的人工标注思维链。中国科学院计算所团队提出新框架PARO,通过让模型学习固定推理模式自动生成思维链,只需大模型标注1/10数据就能达到全量人工标注的性能。这种方法特别适合像金融、审计这样规则清晰的领域,为高效推理监督提供了全新思路。

在当前评测生成式模型代码能力的浪潮中,传统依赖人工编写的算法基准测试集,正日益暴露出可扩展性不足与数据污染严重两大瓶颈。

蚂蚁集团这波操作大圈粉!智东西10月28日报道,10月25日,蚂蚁集团在arXiv上传了一篇技术报告,一股脑将自家2.0系列大模型训练的独家秘籍全盘公开。今年9月至今,蚂蚁集团百灵大模型Ling 2.0系列模型陆续亮相,其万亿参数通用语言模型Ling-1T多项指标位居开源模型的榜首