腾讯发布SpecExit算法,无损压缩端到端加速2.5倍!解决大模型长思考效率难题
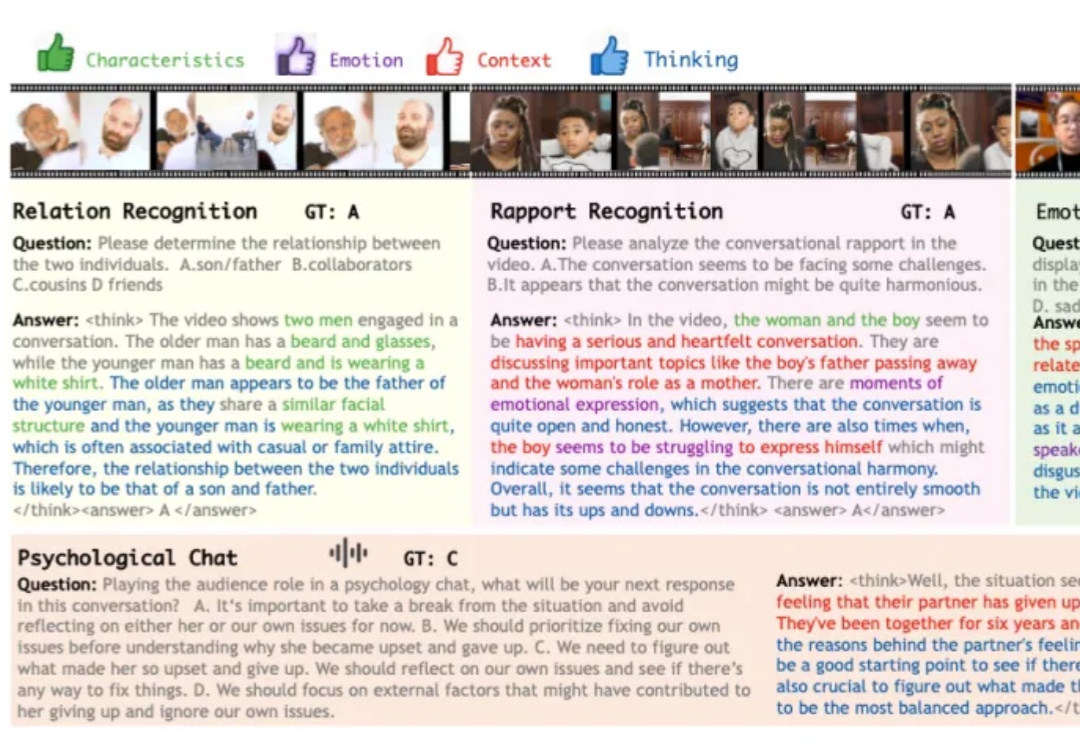
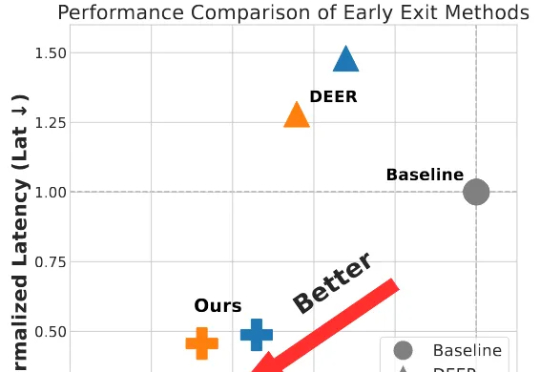
腾讯发布SpecExit算法,无损压缩端到端加速2.5倍!解决大模型长思考效率难题为破解大模型长思维链的效率难题,并且为了更好的端到端加速落地,我们将思考早停与投机采样无缝融合,提出了 SpecExit 方法,利用轻量级草稿模型预测 “退出信号”,在避免额外探测开销的同时将思维链长度缩短 66%,vLLM 上推理端到端加速 2.5 倍。
来自主题: AI技术研报
7997 点击 2025-10-24 16:53