
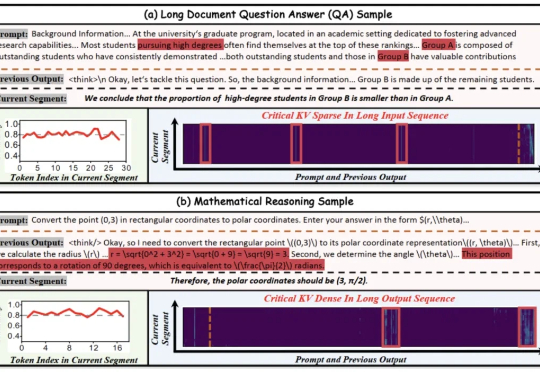
长序列推理不再卡顿!北大华为KV缓存管理框架实现4.7倍推理加速
长序列推理不再卡顿!北大华为KV缓存管理框架实现4.7倍推理加速北大华为联手推出KV cache管理新方式,推理速度比前SOTA提升4.7倍! 大模型处理长序列时,KV cache的内存占用随序列长度线性增长,已成为制约模型部署的严峻瓶颈。
来自主题: AI技术研报
6838 点击 2025-10-22 14:52
北大华为联手推出KV cache管理新方式,推理速度比前SOTA提升4.7倍! 大模型处理长序列时,KV cache的内存占用随序列长度线性增长,已成为制约模型部署的严峻瓶颈。
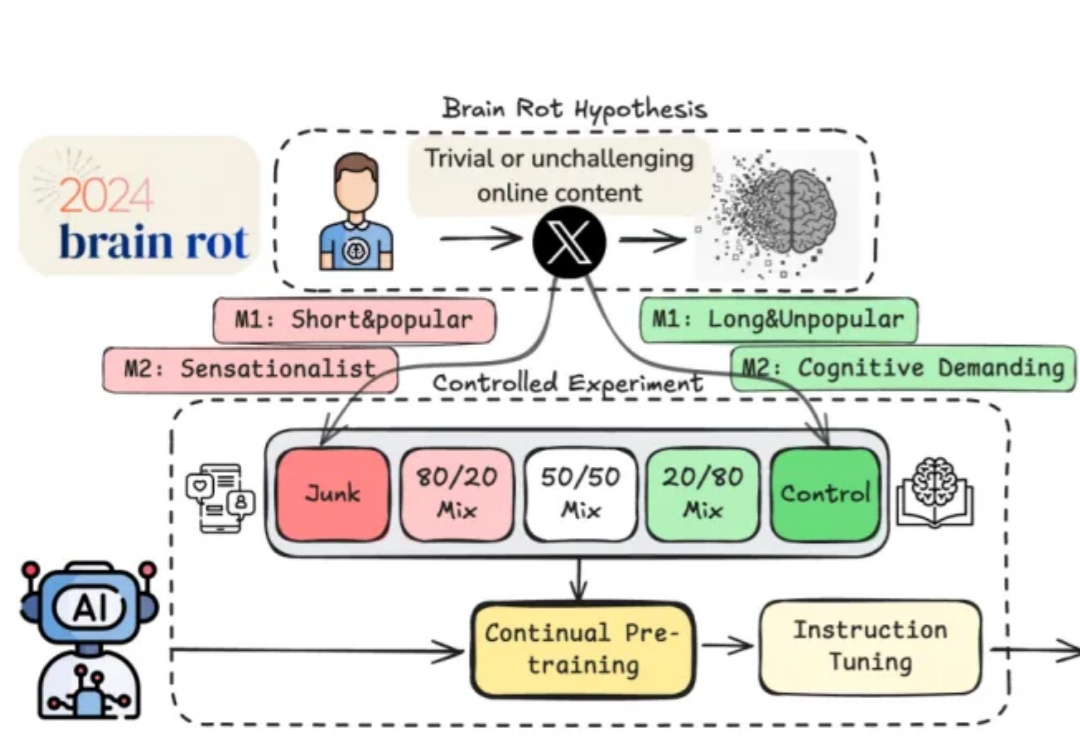
“脑腐”(Brain Rot)指的是接触了过多社交媒体的低质量、碎片化信息后,人类的精神和智力状态恶化,如同腐烂一般。它曾入选 2024 年牛津大学出版社年度热词。
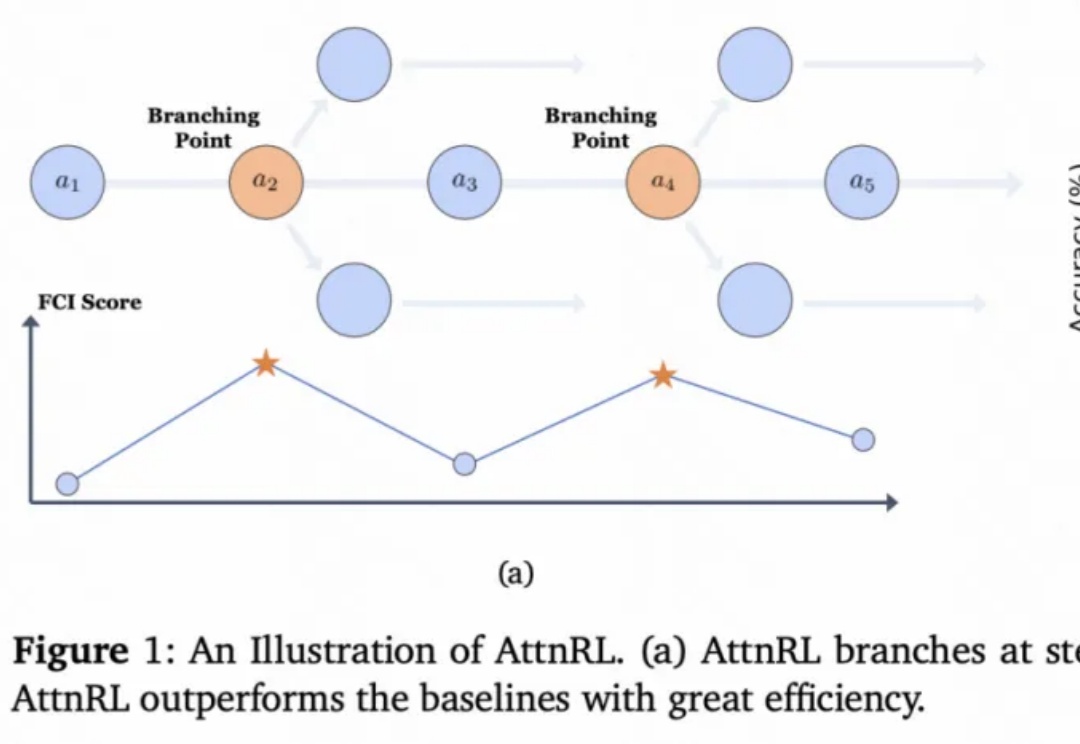
从 AlphaGo 战胜人类棋手,到 GPT 系列展现出惊人的推理与语言能力,强化学习(Reinforcement Learning, RL)一直是让机器「学会思考」的关键驱动力。
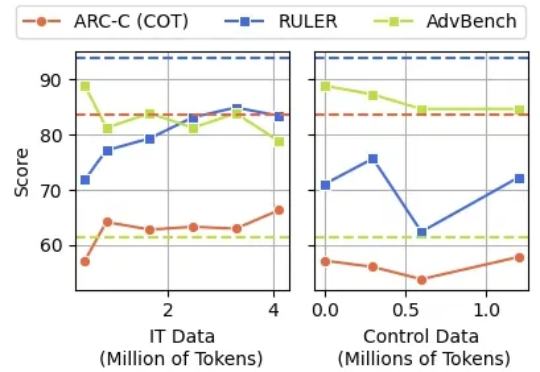
天天刷推,大模型的脑子也会坏掉。 终于有研究证明,互联网上的烂内容会让大模型得「脑腐」。 相信许多读者对「脑腐」这个词并不陌生,长时间沉浸在碎片化的网络信息中,我们经常会感到注意力下降、思维变钝。
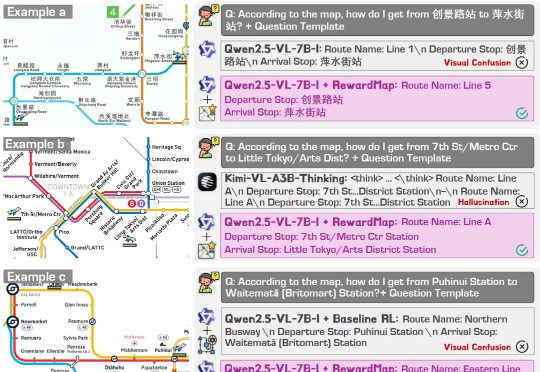
近年来,大语言模型(LLMs)以及多模态大模型(MLLMs)在多种场景理解和复杂推理任务中取得突破性进展。
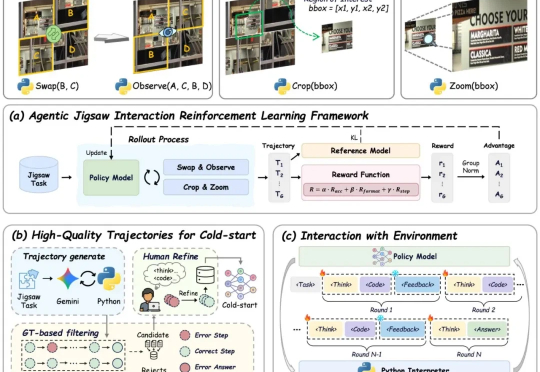
现有视觉语言大模型(VLMs)在多模态感知和推理任务上仍存在明显短板:1. 对图像中的细粒度视觉信息理解有限,视觉感知和推理能力未被充分激发;2. 强化学习虽能带来改进,但缺乏高质量、易扩展的 RL 数据。
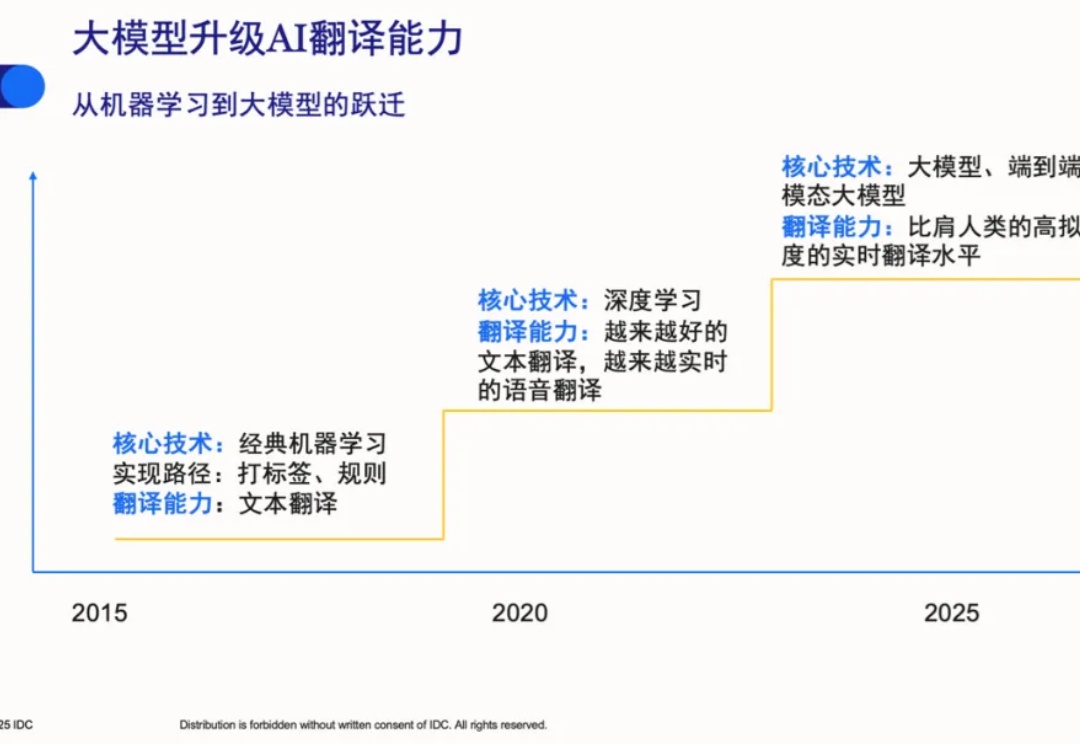
2025 年 10 月,国际数据公司(International Data Corporation,IDC)发布了《中国 AI 翻译技术评估》报告。这份以“大模型驱动 AI 翻译能力全面换新”为主题的报告指出,大模型技术的全面渗透正在深刻重塑 AI 翻译市场。

那个叫大模型的高手,被下毒了
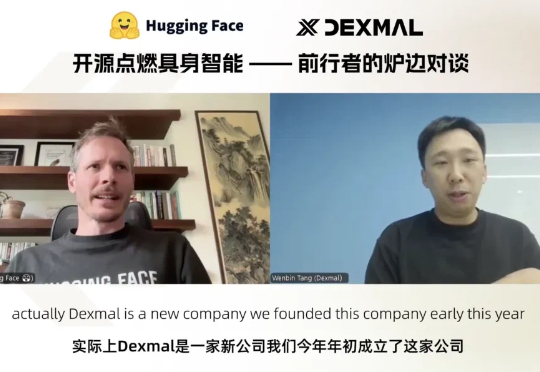
“很多模型在模拟器里完美运行,但一到现实就彻底失灵。” 在最新一次线上对谈中,Dexmal联合创始人唐文斌与Hugging Face联合创始人Thomas Wolf指出了当前机器人研究的最大痛点。
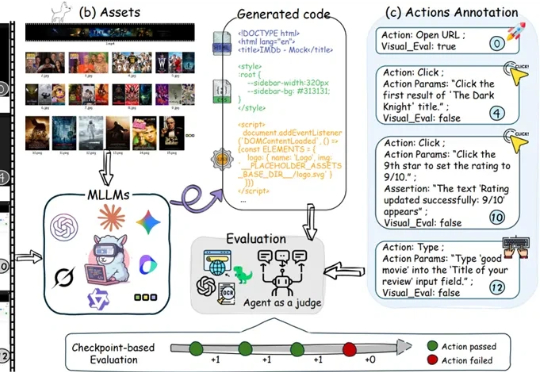
多模态大模型在根据静态截图生成网页代码(Image-to-Code)方面已展现出不俗能力,这让许多人对AI自动化前端开发充满期待。