AI 科普丨都2025年了,人们到底在用AI做什么?国外大牛总结了100个案例
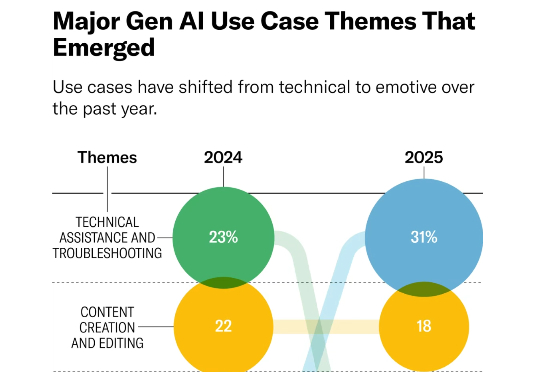
AI 科普丨都2025年了,人们到底在用AI做什么?国外大牛总结了100个案例近一年来,围绕人工智能(AI)、生成式 AI(GenAI)和大语言模型(LLM)的炒作愈演愈烈,大众的兴趣翻了一番,针对 AI 的投资激增,各国政府也采取了更加明确的立场。根据一些人的说法,AI 与人类的未来息息相关。
来自主题: AI资讯
8071 点击 2025-08-08 12:41
 搜索
搜索
近一年来,围绕人工智能(AI)、生成式 AI(GenAI)和大语言模型(LLM)的炒作愈演愈烈,大众的兴趣翻了一番,针对 AI 的投资激增,各国政府也采取了更加明确的立场。根据一些人的说法,AI 与人类的未来息息相关。

强化学习(RL)范式虽然显著提升了大语言模型(LLM)在复杂任务中的表现,但其在实际应用中仍面临传统RL框架下固有的探索难题。
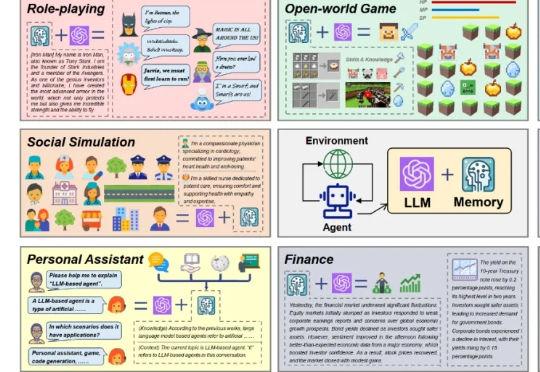
近期,基于大语言模型的智能体(LLM-based agent)在学术界和工业界中引起了广泛关注。对于智能体而言,记忆(Memory)是其中的重要能力,承担了记录过往信息和外部知识的功能,对于提高智能体的个性化等能力至关重要。

你有没有发现,AI 应用生成平台们正在走向一条与大家预期完全不同的路?很多人原本以为这会是一场血腥的零和游戏,大家会在价格战中厮杀到底,最终只剩一家独大。但现实却让人意外:这些平台不但没有互相厮杀,反而开始各自寻找差异化的定位,在不同的细分市场中共存共荣。这让我想起了大语言模型市场的发展轨迹,同样出人意料,同样充满启发。
gpt-oss-120b 和 gpt-oss-20b OpenAI终于把开源的模型放出来了。 gpt-oss系列也是自GPT2以来,OpenAI首次开源的大语言模型。

融资10亿美元,要在开源上挑战Deepseek! 前谷歌DeepMind成员、AlphaGo开发者创立Reflection AI,致力于开发开源大语言模型。
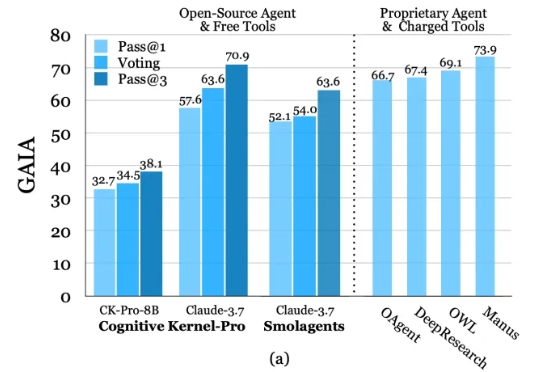
深度研究智能体(Deep Research Agents)凭借大语言模型(LLM)和视觉-语言模型(VLM)的强大能力,正在重塑知识发现与问题解决的范式。
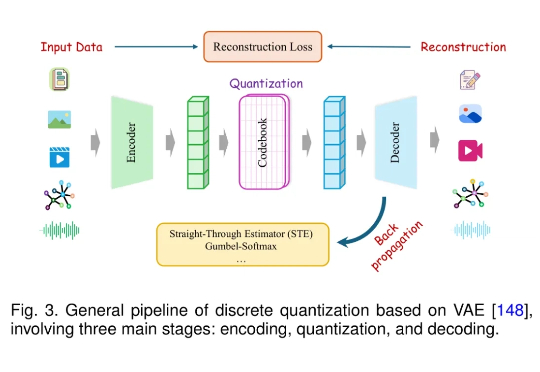
近年来,大语言模型(LLM)在语言理解、生成和泛化方面取得了突破性进展,并广泛应用于各种文本任务。随着研究的深入,人们开始关注将 LLM 的能力扩展至非文本模态,例如图像、音频、视频、图结构、推荐系统等。

成立仅一年的初创公司Reflection AI 正洽谈融资逾 10 亿美元,用于开发开源大语言模型,与中国深度求索(DeepSeek)、法国 Mistral 及美国 Meta 等企业展开竞争。
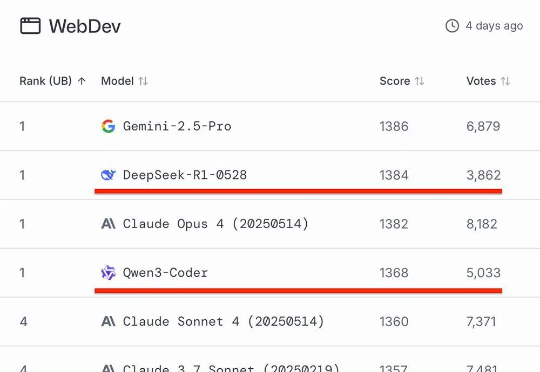
知名AI大模型评测Chatbot Arena放榜!阿里Qwen3-235B-A22B-Instruct-2507位列大语言模型总榜第三,月之暗面Kimi-K2-0711-preview、深度求索DeepSeek-R1-0528并列为总榜第五,以开源之姿超越Claude 4、GPT-4.1等顶尖闭源模型。