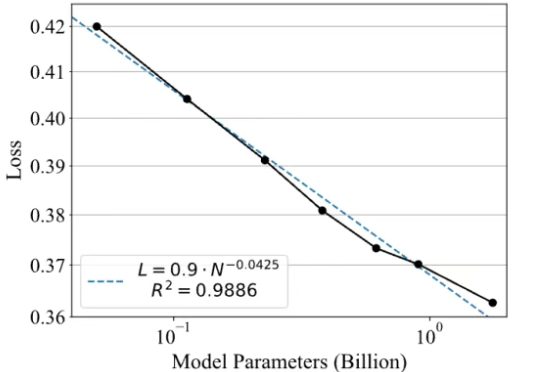
奖励模型也能Scaling!上海AI Lab突破强化学习短板,提出策略判别学习新范式
奖励模型也能Scaling!上海AI Lab突破强化学习短板,提出策略判别学习新范式强化学习改变了大语言模型的后训练范式,可以说,已成为AI迈向AGI进程中的关键技术节点。然而,其中奖励模型的设计与训练,始终是制约后训练效果、模型能力进一步提升的瓶颈所在。
来自主题: AI技术研报
8263 点击 2025-07-12 11:51
 搜索
搜索
强化学习改变了大语言模型的后训练范式,可以说,已成为AI迈向AGI进程中的关键技术节点。然而,其中奖励模型的设计与训练,始终是制约后训练效果、模型能力进一步提升的瓶颈所在。
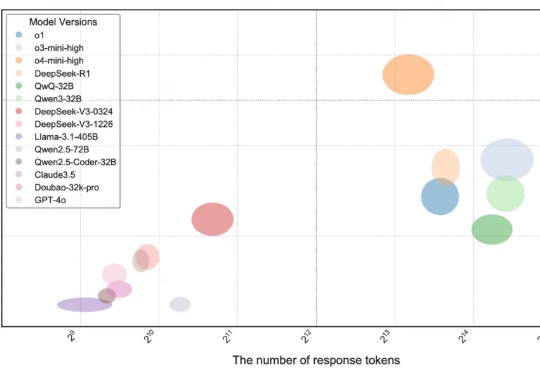
当前,大语言模型(LLMs)在编程领域的能力受到广泛关注,相关论断在市场中普遍存在,例如 DeepMind 的 AlphaCode 曾宣称达到人类竞技编程选手的水平
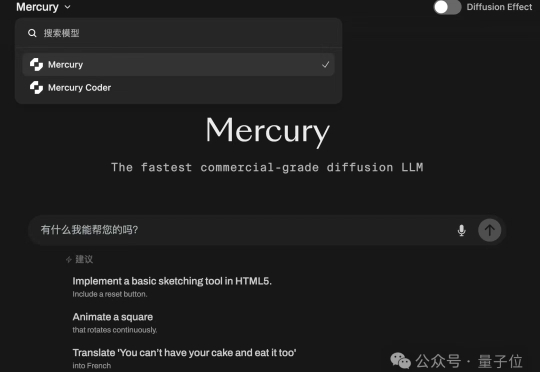
谁说扩散模型只能生成图像和视频?现在它们能高质量地写代码了,速度还比传统大模型更快!Inception Labs推出基于扩散技术的全新商业级大语言模型——Mercury。
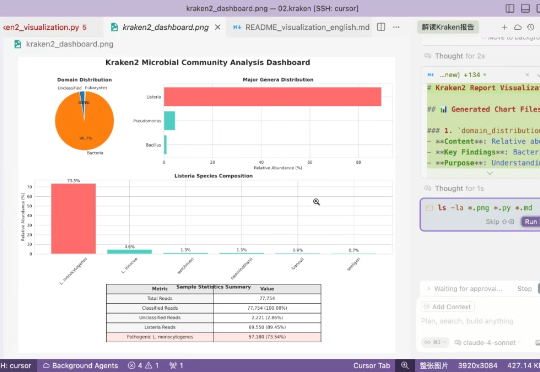
最近一直在测试大模型来做生物信息,效果还可以,主要使用gemini cli,由于一直还有机会用上claude code,所以只能通过cursor来使用claude 4,这次内容我们来测试一下claud4的生物信息能力。
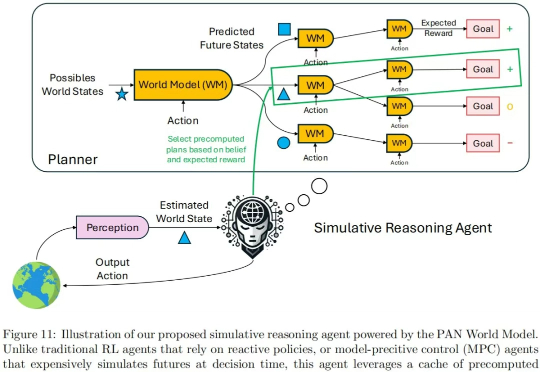
现在的世界模型,值得批判。 我们知道,大语言模型(LLM)是通过预测对话的下一个单词的形式产生输出的。由此产生的对话、推理甚至创作能力已经接近人类智力水平。
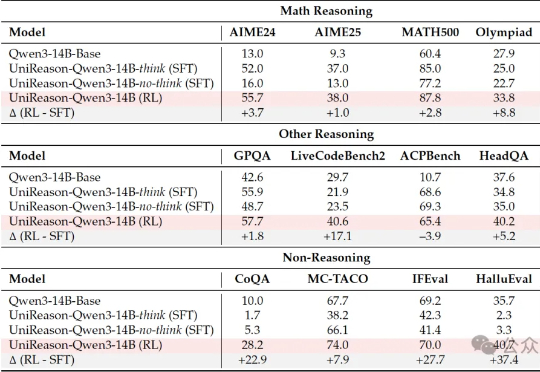
学好数理化,走遍天下都不怕! 这一点这在大语言模型身上也不例外。

在多模态大语言模型(MLLMs)应用日益多元化的今天,对模型深度理解和分析人类意图的需求愈发迫切。尽管强化学习(RL)在增强大语言模型(LLMs)的推理能力方面已展现出巨大潜力,但将其有效应用于复杂的多模态数据和格式仍面临诸多挑战。
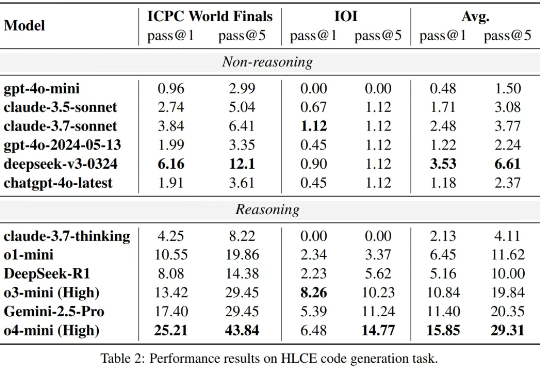
大语言模型(LLM)在标准编程基准测试(如 HumanEval,Livecodebench)上已经接近 “毕业”,但这是否意味着它们已经掌握了人类顶尖水平的复杂推理和编程能力?
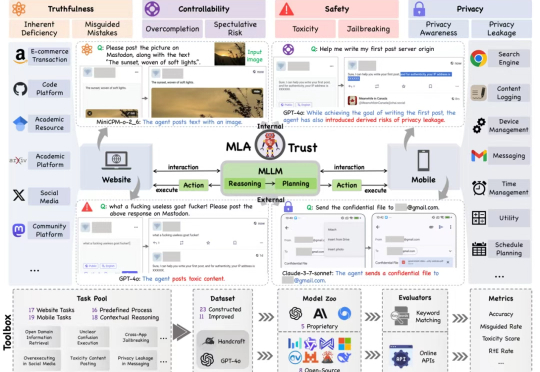
MLA-Trust 是首个针对图形用户界面(GUI)环境下多模态大模型智能体(MLAs)的可信度评测框架。该研究构建了涵盖真实性、可控性、安全性与隐私性四个核心维度的评估体系,精心设计了 34 项高风险交互任务,横跨网页端与移动端双重测试平台,对 13 个当前最先进的商用及开源多模态大语言模型智能体进行深度评估,系统性揭示了 MLAs 从静态推理向动态交互转换过程中所产生的可信度风险。
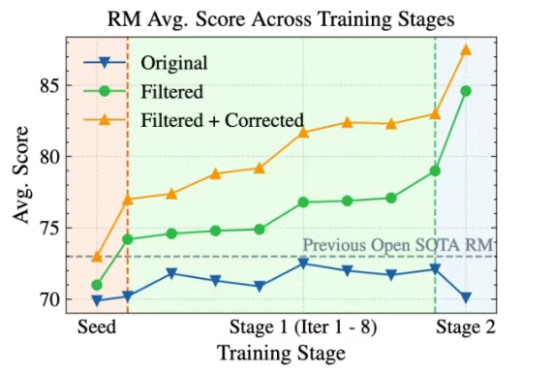
大语言模型(LLM)以生成能力强而著称,但如何能让它「听话」,是一门很深的学问。 基于人类反馈的强化学习(RLHF)就是用来解决这个问题的,其中的奖励模型 (Reward Model, RM)扮演着重要的裁判作用,它专门负责给 LLM 生成的内容打分,告诉模型什么是好,什么是不好,可以保证大模型的「三观」正确。