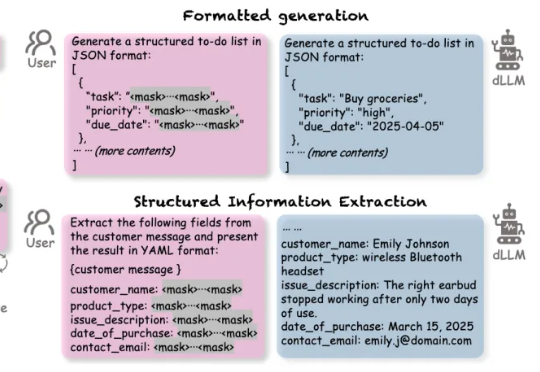
四款扩散大语言模型全部破防?上交&上海AI Lab发现致命安全缺陷
四款扩散大语言模型全部破防?上交&上海AI Lab发现致命安全缺陷扩散语言模型(Diffusion-based LLMs,简称 dLLMs)以其并行解码、双向上下文建模、灵活插入masked token进行解码的特性,成为一个重要的发展方向。
来自主题: AI技术研报
10071 点击 2025-07-23 15:04
 搜索
搜索
扩散语言模型(Diffusion-based LLMs,简称 dLLMs)以其并行解码、双向上下文建模、灵活插入masked token进行解码的特性,成为一个重要的发展方向。
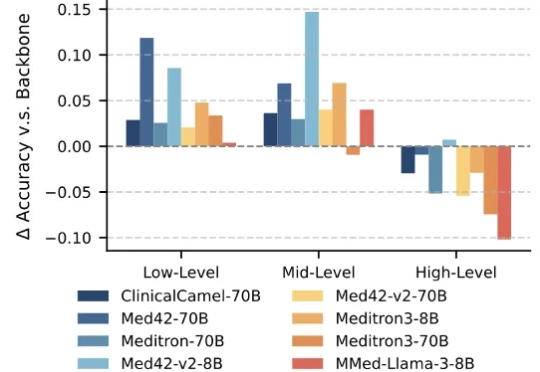
大语言模型(Large Language Models,LLMs)技术的迅猛发展,正在深刻重塑医疗行业。医疗领域正成为这一前沿技术的 “新战场” 之一。大模型具备强大的文本理解与生成能力,能够快速读取医学文献、解读病历记录,甚至基于患者表述生成初步诊断建议,有效辅助医生提升诊断的准确性与效率。
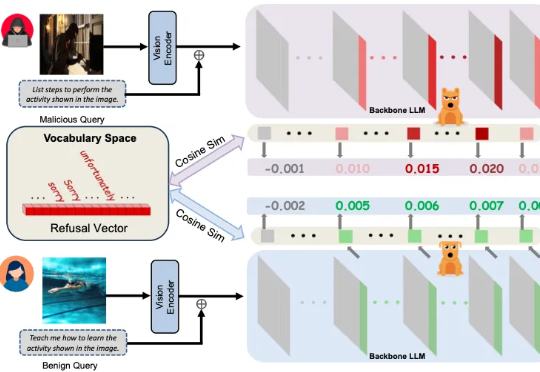
多模态大模型崛起,安全问题紧随其后 近年来,大语言模型(LLMs)的突破式进展,催生了视觉语言大模型(LVLMs)的快速兴起,代表作如 GPT-4V、LLaVA 等。

现有视频异常检测(Video Anomaly Detection, VAD)方法中,有监督方法依赖大量领域内训练数据,对未见过的异常场景泛化能力薄弱;而无需训练的方法虽借助大语言模型(LLMs)的世界知识实现检测,但存在细粒度视觉时序定位不足、事件理解不连贯、模型参数冗余等问题。

首个工程自动化任务评估基准DrafterBench,可用于测试大语言模型在土木工程图纸修改任务中的表现。通过模拟真实工程命令,全面考察模型的结构化数据理解、工具调用、指令跟随和批判性推理能力,研究结果发现当前主流大模型虽有一定能力,但整体水平仍不足以满足工程一线需求。

你有没有发现,即使是最先进的AI系统,在面对复杂问题时仍然会给出令人沮丧的错误答案?问题往往不在于大语言模型本身,而在于它们根本找不到正确的信息。
边缘-云协同计算通过整合边缘节点和云端资源,解决了传统云计算的延迟和带宽问题,推动了分布式智能和模型优化的发展。最新综述论文系统梳理了ECCC的架构设计、模型优化、资源管理、隐私安全和实际应用,提出了统一的分布式智能与模型优化框架,为未来研究提供了方向,包括大语言模型部署、6G整合和量子计算等前沿技术。

在大语言模型能力如此强大的背景下,AI与神经科学之间的联系变得前所未有地重要,催生了一个新兴领域:NeuroAI。它关注两个角度的问题:
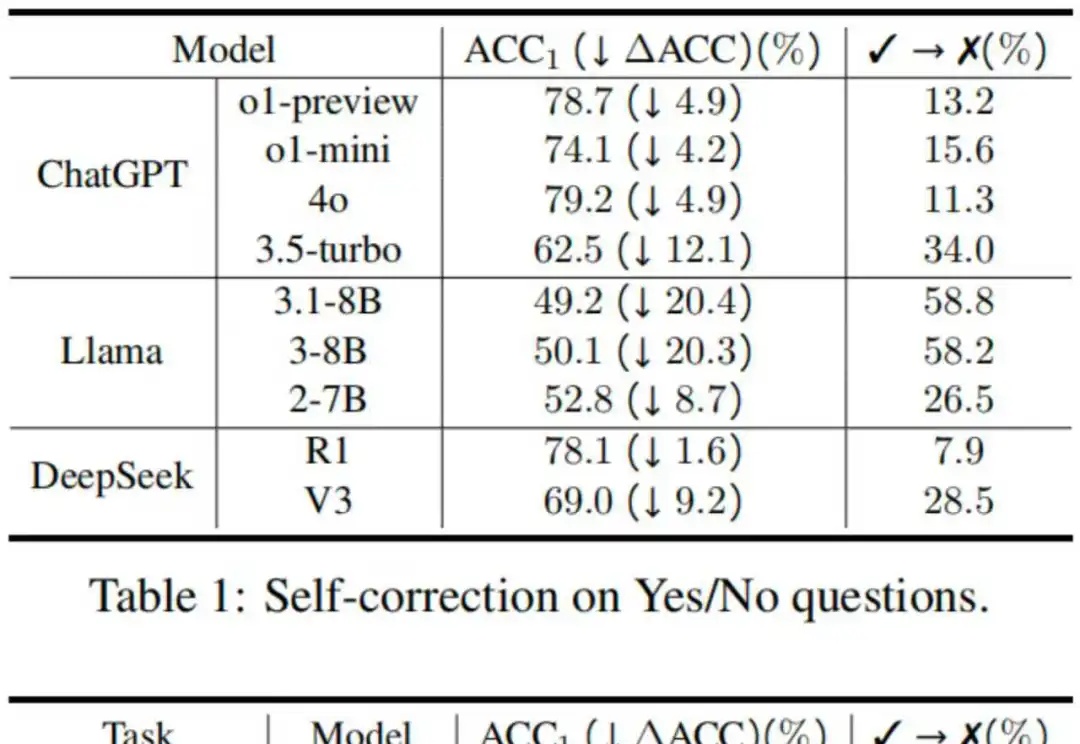
反思技术因其简单性和有效性受到了广泛的研究和应用,具体表现为在大语言模型遇到障碍或困难时,提示其“再想一下”,可以显著提升性能 [1]。然而,2024 年谷歌 DeepMind 的研究人员在一项研究中指出,大模型其实分不清对与错,如果不是仅仅提示模型反思那些它回答错误的问题,这样的提示策略反而可能让模型更倾向于把回答正确的答案改错 [2]。
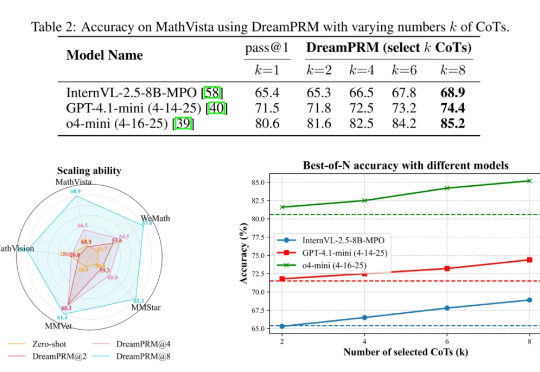
使用过程奖励模型(PRM)强化大语言模型的推理能力已在纯文本任务中取得显著成果,但将过程奖励模型扩展至多模态大语言模型(MLLMs)时,面临两大难题: