# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
推理模型的内心世界是怎么想的?推理模型与普通LLM之间有没有本质的区别?
一直以来,AI内部的运作机理就像个「黑箱子」。
我们知道模型输入的是什么,也能看到它们输出的结果,但中间的过程,就连开发AI的人自己也不知道。
像谜一样。

这种不透明带来了很多问题。比如,我们不知道模型为什么会「胡说八道」,也就是出现所谓的「幻觉」。
更可怕的是,有些情况下模型会撒谎,甚至是故意骗人!
这给AI的安全应用带来了很大的阻碍。
一直有团队试图破解这个「黑箱子」。比如不久前,Anthropic就推出一项研究,深入Claude 3.5 Haiku的「脑子」,揭开了一些它运行的秘密。
就在刚刚,AI安全公司Goodfire发布了首个基于DeepSeek-R1训练的开源稀疏自编码器(SAE),为我们提供了理解和引导模型思考的新工具。

稀疏自编码器(SAE)是一种特殊的神经网络,类似于「压缩包」,能将复杂的数据压缩成更简单的形式,然后再恢复原来的数据。
不同之处在于,SAE会确保中间处理层(隐藏层)中只有少数神经元被激活,大部分神经元保持「沉默」(接近零的激活)。
这种「稀疏性」就像团队合作:假设你有一个团队,每次任务只需要少数几个人完成,
SAE通过让大部分神经元「休息」,只让少数神经元「工作」,来学习数据的关键特征。
这不仅使模型更高效,还能让结果更容易理解,比如减少数据维度,同时保留重要信息。
简单地说,SAE就像一个「挑剔的专家」,它只保留数据中最有价值的部分,特别适用于需要高可解释性的场景。
像DeepSeek-R1、o3和Claude 3.7这样的推理模型能够通过增加「思考」计算量,为复杂问题提供更可靠、更连贯的响应。
但理解它们的内部机制仍然是个挑战。
不过,Goodfire这个基于DeepSeek-R1训练的SAE,则可以像显微镜一样,深入模型内部,揭示R1如何处理和响应信息。
研究者从SAE中发现了一些有趣的早期洞察,通俗点说就是:
这说明模型内部的推理token方式挺出人意料的。
这些发现表明,推理模型和普通的大语言模型在根本上有很大不同。

Goodfire对加快可解释性和对齐研究方面的进展感到了兴奋,目前它们已将这些SAE开源,希望确保人工智能系统既安全又强大。
开源地址:https://github.com/goodfire-ai/r1-interpretability
推理模型的内部结构
本次研究团队分享了两个最先进的开源稀疏自动编码器 (SAE)。
研究人员的早期实验表明,R1与非推理语言模型在本质上有所不同,并且需要一些新的见解来理解它。
由于R1是一个非常大的模型,因此对于大多数独立研究者来说本地运行很困难,团队上传了包含每个特征的最大激活示例的SQL数据库。
本次分享的SAE已经学习了许多能够重建推理模型核心行为的特性,例如回溯。
首先展示的是通用推理SAE中的5个精选特性(比如研究团队命名为Feature 15204),分别看一下:
回溯:当模型识别出其推理中的错误并明确纠正自身时的特性。下图中的「wait...not」表明模型意识到错误,然后回溯并纠正。

自引用:模型在响应中引用其先前的陈述或分析时所具备的功能。下图中的「earlier...previously」等。

句子关于子集和子序列之后的时期:在模型引用了子集或子序列后触发的功能。

需要跟踪的实体:用于标识模型需要跟踪的实体的功能。比如下图中「beacon 4、section 3」等表明模型正在跟踪实体。

在多步骤计算的结果之前:在多步骤计算结果之前触发的功能。比如下图中各个公式计算前触发的「空格」。

推理机制可解释性
如果想要「解释」推理模型的内部机制,目前有办法吗?
研究团队构建了一个工具:通过逆向工程神经网络的内部组件来科学地理解它们如何处理信息。
关于这一领域的最新研究,比如有Anthropic在Claude中的电路追踪研究,揭示了从心算到幻觉等模型行为背后的计算路径和特征。
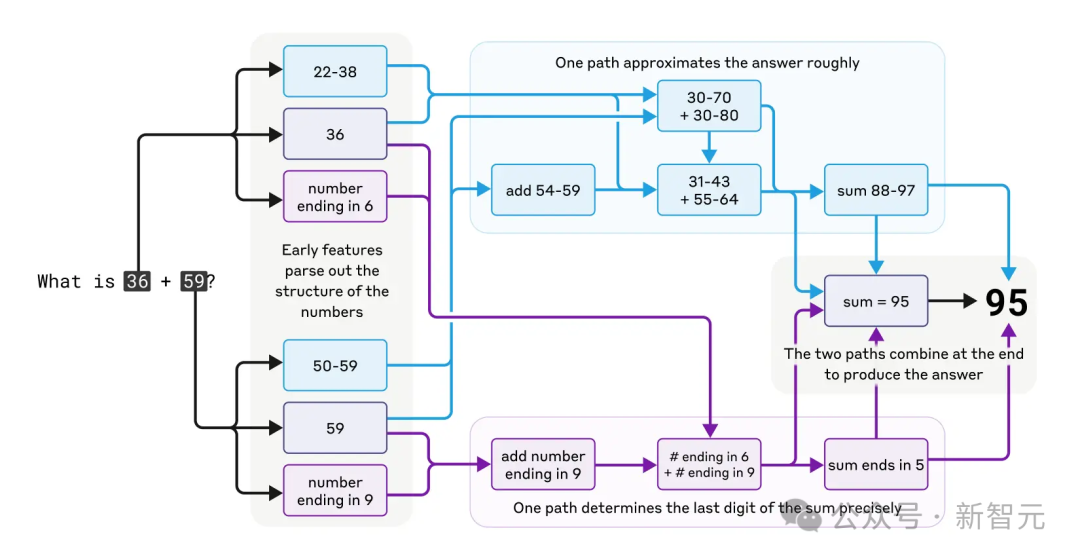
Claude做心算时思维过程中复杂而平行的路径
发展这种更深层次的理解,对于科学进步以及确保这些日益强大的系统可靠且符合人类意图至关重要。
作为这一使命的一部分,为生成式AI能力的前沿构建可解释性工具是至关重要的。
虽然SAE并不能解决推理机制可解释性的全部问题,但它们仍然是当今研究模型推理机制工具箱中的核心「武器」。
无监督可解释性技术的进一步发展最终可能允许更可靠的对齐、按需增强或抑制特定推理能力,甚至在不破坏整体模型性能的情况下纠正特定故障模式。
如果能实现这一愿景,也许对于人类现在还是「黑箱」的大模型会有真正被理解的一天。
团队为DeepSeek-R1发布了两个SAE:
第一个是在自定义推理数据集上使用R1的激活进行训练的(开源了这个数据集);
第二个使用了OpenR1-Math,这是一个用于数学推理的大规模数据集。
这些数据集使得能够发现R1用来回答那些考验其推理能力的难题时所使用的特征。
在671B参数下,未蒸馏的R1模型在大规模运行时是一个工程挑战。
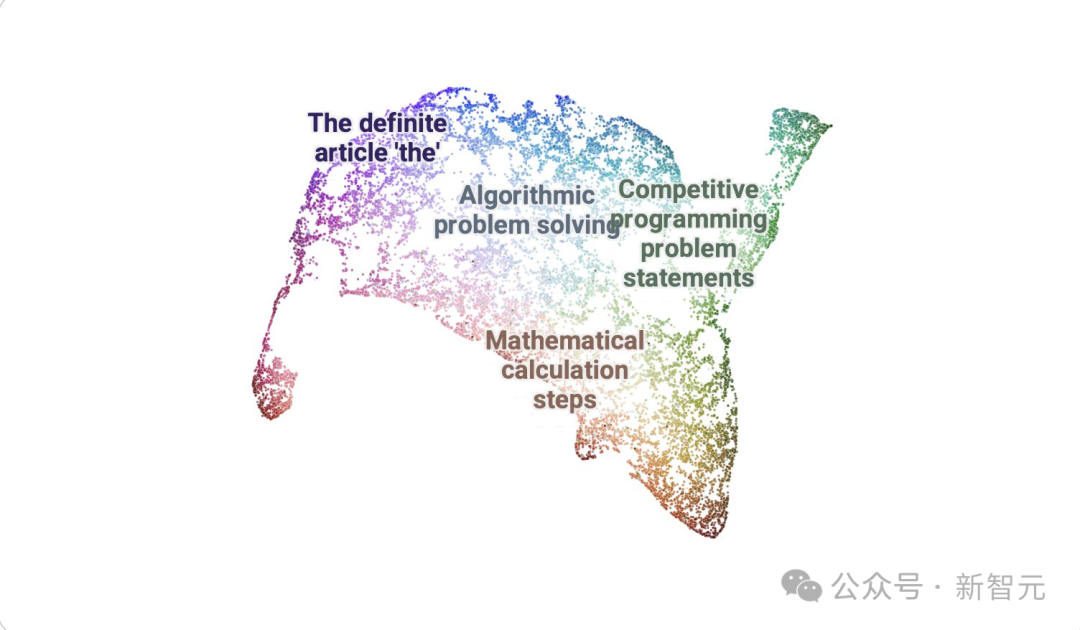
使用DataMapPlot创建了通用推理SAE特征的交互式UMAP可视化的特征图。
UMAP (Uniform Manifold Approximation and Projection for Dimension Reduction) 是一种用于降维的算法和工具。它基于流形学习和拓扑数据分析的数学理论。
UMAP将高维度的数据(有很多特征或变量的数据)映射到低维度空间(通常是 2 维或 3 维),以便于可视化和分析。
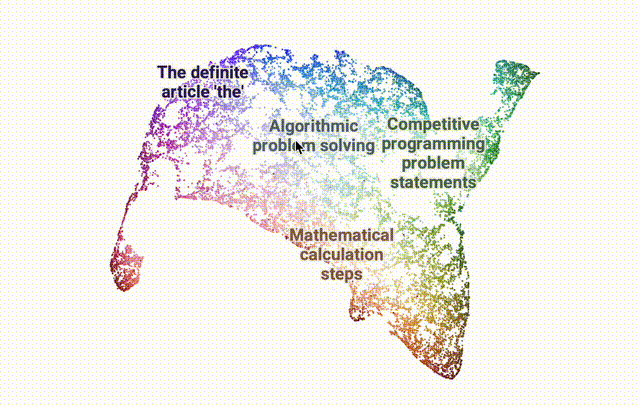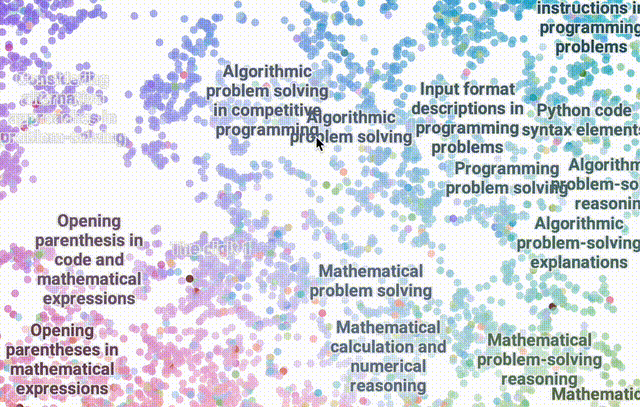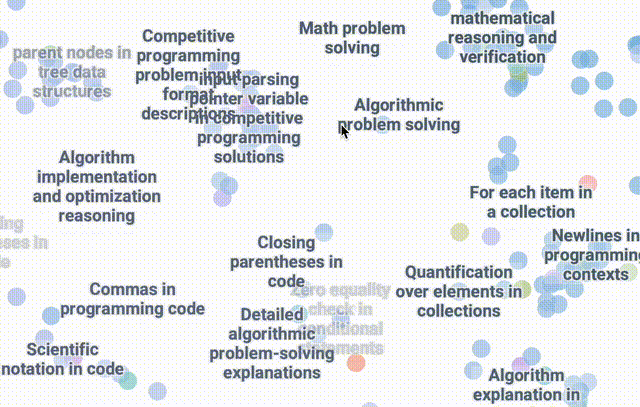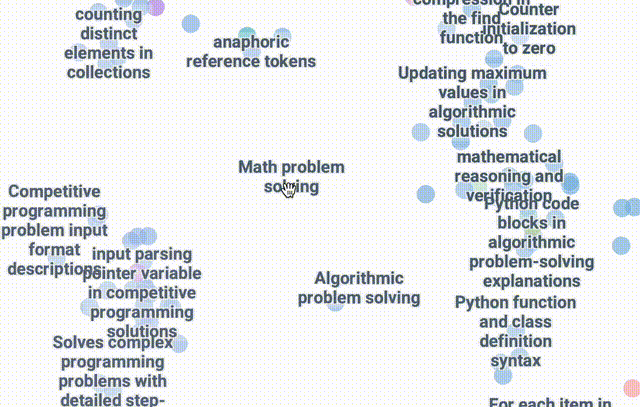
关于引导R1的两个初步见解
虽然还没有系统地研究这些特征的出现频率或原因,但这里想分享两个关于引导R1的见解,这些是在非推理模型中没有遇到过的。
在「好吧,用户问了一个关于……」之后进行引导
通常会从模型响应的第一个token开始进行引导。
然而,直接在R1思考链条的开始阶段进行引导是无效的。
相反,需要等到模型以类似「好吧,用户问了一个关于……」这样的话语开始响应之后,才能有效地进行引导。
在这种「响应前缀」的末尾,存在注意力汇聚(attention sinks)的现象,即某些token的平均激活强度远高于正常水平。
通常情况下,注意力汇聚会出现在模型响应的开始阶段。
这表明,R1在开始响应之前并没有真正识别出自己进入了「真实的响应」阶段,直到「好吧……」这个前缀出现。
研究人员最后囤点,像上面这样的短语在R1训练时的推理轨迹中非常常见,因此模型实际上将其视为提示的一部分。
(类似的前缀在R1的推理轨迹中极为常见:超过95%的英语推理轨迹都以「好吧」开头)。
在提示(包括这个思考轨迹的前缀)、思考轨迹和助手的响应之间,特征分布发生了显著的变化。
这种微妙的、不直观的R1内部过程特征表明,最初对外部用户来说直观的概念边界,可能并不完全符合模型自身所使用的边界。
引导示例#1,在数学问题中交换运算符,比如下图将times变成了divide。

过度引导R1会导致其恢复原来的行为
在引导模型时,我们通过调整所操控特征的强度,从而控制该特征对下游模型输出的显著性。
例如,如果增加一个表示「狗」的特征的激活强度,那么模型的输出会更多地与狗相关。
如果过度引导,通过不断增加这个特征的激活强度,通常会观察到模型越来越专注于狗,直到其输出变得不连贯。
然而,在对R1进行某些特征的引导时,发现过度引导反而会让模型恢复到原始行为中去。
引导示例#2(减少思考时间)
研究者初步猜想是,当模型内部的激活状态受到过度干扰时,它会隐性地察觉到一种困惑或不连贯的状态,从而停下来进行调整。
为什么这种「重新平衡」效应会特别出现在推理模型中?
研究人员认为,这可能与它们的训练方式有关,训练过程可能促使模型对自身内部状态有更高的隐性「察觉」。
从经验上看,推理模型在处理难题时,如果某条推理路径行不通,常常会回溯并尝试其他方法,这暗示它们在某种程度上能「感知」到自己何时「迷路」了。
如果这种现象是推理模型的普遍特性,那么试图改变模型行为——比如抑制不诚实的回答——可能需要更复杂的技术,因为模型可能会找到绕过修改的方法。
推理机制可解释性通过深入研究模型如何生成回答,可以帮我们:
Goodfire此次开源的是针对R1的SAE,他们很期待看到社区如何基于这些成果进一步发展,开发新的技术来理解和对齐强大的AI系统。
随着推理模型的能力和应用不断增强,像这样的工具将对确保模型的可靠性、透明度,以及与人类意图的一致性起到关键作用。
参考资料:
https://www.goodfire.ai/blog/under-the-hood-of-a-reasoning-model
https://x.com/GoodfireAI/status/1912217312566137335
https://github.com/goodfire-ai/r1-interpretability
文章来自于微信公众号 “新智元”,作者 :犀牛 定慧




