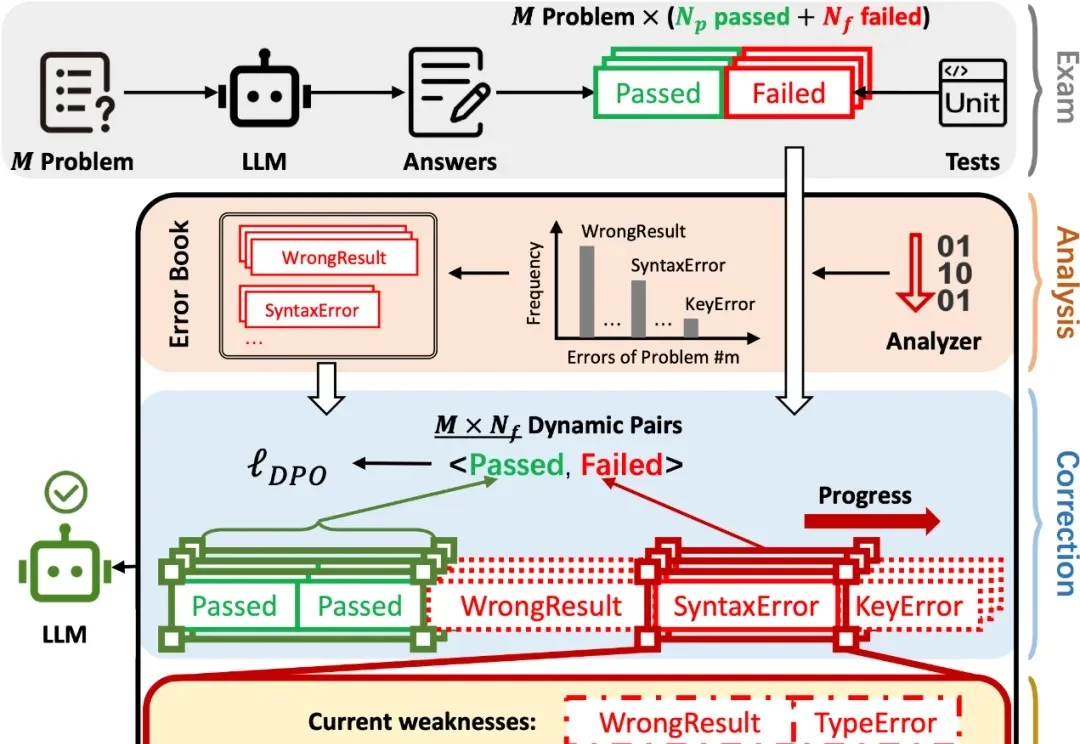
AAAI 2026|AP2O-Coder 让大模型拥有「错题本」,像人类一样按题型高效刷题
AAAI 2026|AP2O-Coder 让大模型拥有「错题本」,像人类一样按题型高效刷题在 AI 辅助 Coding 技术快速发展的背景下,大语言模型(LLMs)虽显著提升了软件开发效率,但开源的 LLMs 生成的代码依旧存在运行时错误,增加了开发者调试成本。
来自主题: AI技术研报
10024 点击 2026-01-14 15:28
 搜索
搜索
在 AI 辅助 Coding 技术快速发展的背景下,大语言模型(LLMs)虽显著提升了软件开发效率,但开源的 LLMs 生成的代码依旧存在运行时错误,增加了开发者调试成本。

现在,我们越来越多地将大语言模型应用于搜索、编程、内容生成和决策辅助等现实场景中。尽管每天有数百万人使用大模型,但它的问题也随之而来,例如有时会产生幻觉,甚至在特定情境下表现出误导或欺骗用户的倾向。
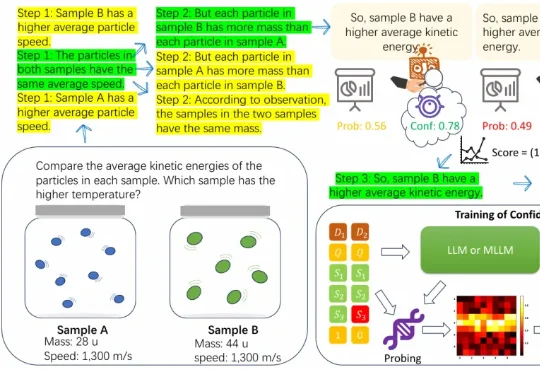
近年来,大语言模型在算术、逻辑、多模态理解等任务上之所以取得显著进展,很大程度上依赖于思维链(CoT)技术。所谓 CoT,就是让模型在给出最终答案前,先生成一系列类似「解题步骤」的中间推理。 这种方式
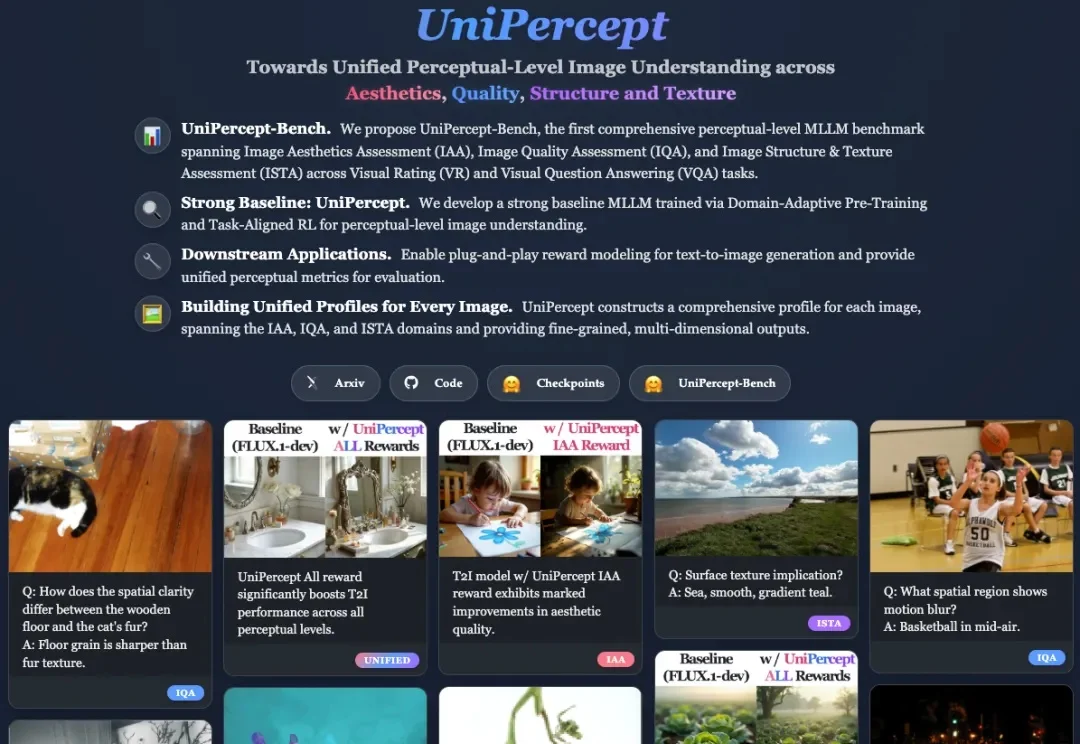
尽管多模态大语言模型(MLLMs)在识别「图中有什么」这一语义层面上取得了巨大进步,但在理解「图像看起来怎么样」这一感知层面上仍显乏力。

2023年启动大模型研发以来,腾讯第一次把大语言模型变成一把手工程,负责人是个27岁的年轻人;

空间理解能力是多模态大语言模型(MLLMs)走向真实物理世界,成为 “通用型智能助手” 的关键基础。但现有的空间智能评测基准往往有两类问题:一类高度依赖模板生成,限制了问题的多样性;另一类仅聚焦于某一种空间任务与受限场景,因此很难全面检验模型在真实世界中对空间的理解与推理能力。
财大气粗的老黄,又要出手了!为了将200多位顶尖AI人才纳入麾下,英伟达被曝拟用20~30亿美金收购一家以色列AI初创公司。这家公司名为AI21 Labs,是以色列为数不多的自主研发大语言模型的公司,其联创还曾创办了明星自动驾驶公司Mobileye(Mobileye被收购后成了英特尔副总裁)。
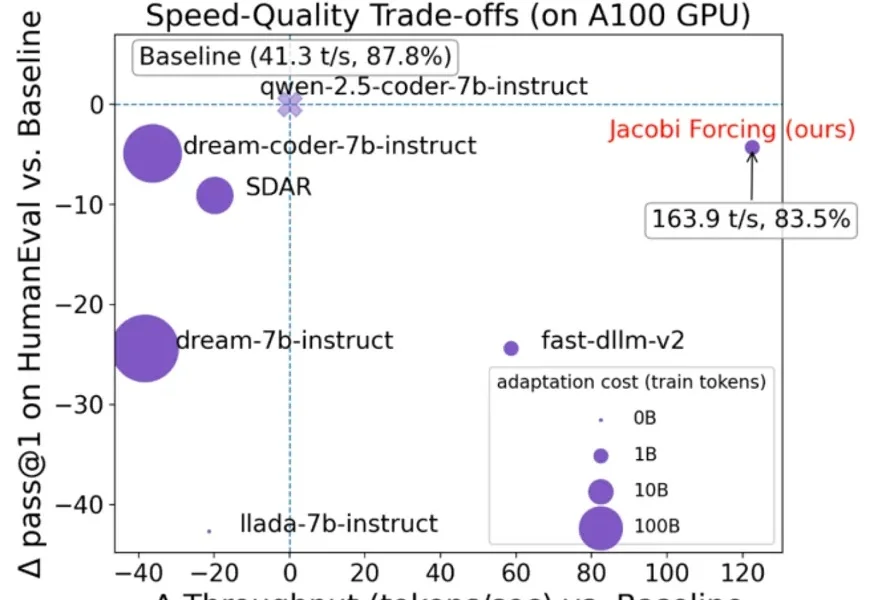
在大语言模型(LLM)落地应用中,推理速度始终是制约效率的核心瓶颈。传统自回归(AR)解码虽能保证生成质量,却需逐 token 串行计算,速度极为缓慢;扩散型 LLM(dLLMs)虽支持并行解码,却面

清华大学等多所高校联合发布SR-LLM,这是一种融合大语言模型与深度强化学习的符号回归框架。它通过检索增强和语义推理,从数据中生成简洁、可解释的数学模型,显著优于现有方法。在跟车行为建模等任务中,SR-LLM不仅复现经典模型,还发现更优新模型,为机器自主科学发现开辟新路径。
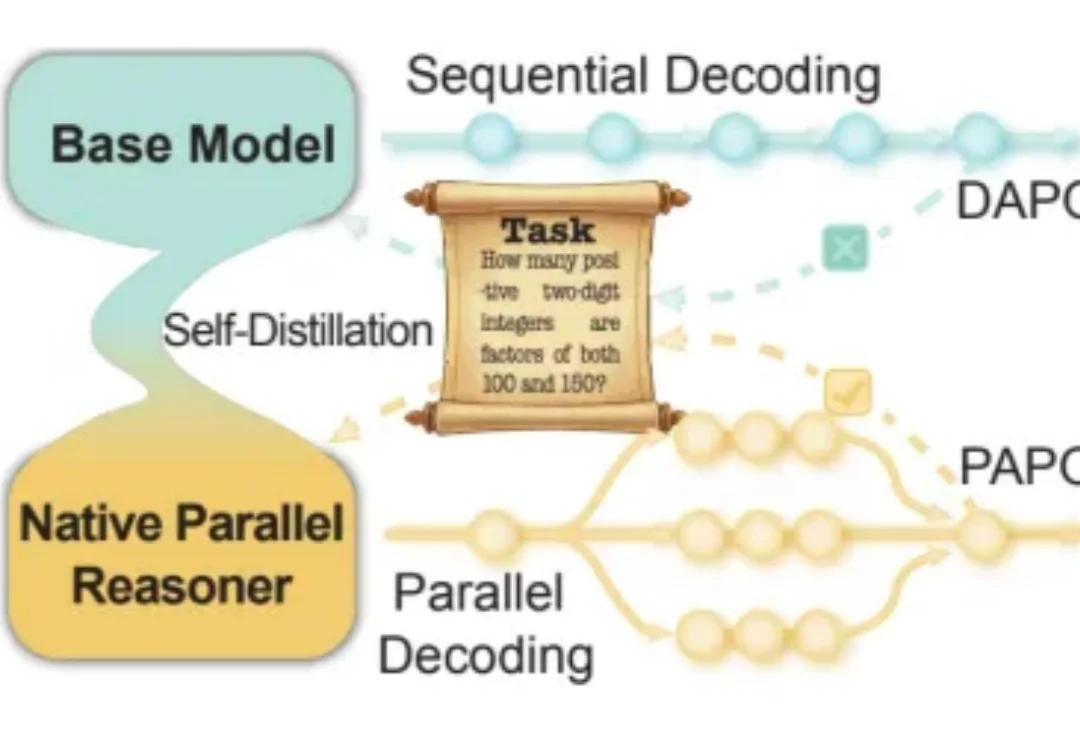
近年来,大语言模型在「写得长、写得顺」这件事上进步飞快。但当任务升级到真正复杂的推理场景 —— 需要兵分多路探索、需要自我反思与相互印证、需要在多条线索之间做汇总与取舍时,传统的链式思维(Chain-of-Thought)往往就开始「吃力」:容易被早期判断带偏、发散不足、自我纠错弱,而且顺序生成的效率天然受限。