让搜索Agent不「傻等」:人大团队依托扩散模型实现「一心二用」,边等搜索结果边思考,加速15%性能不减
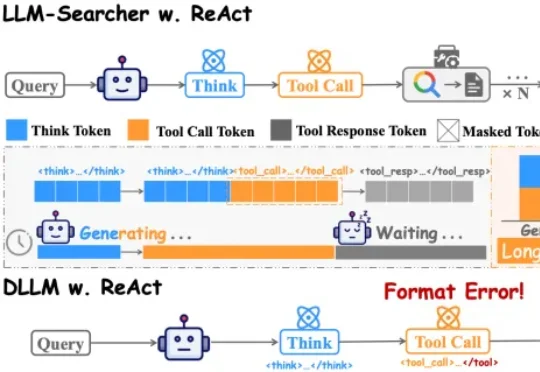
让搜索Agent不「傻等」:人大团队依托扩散模型实现「一心二用」,边等搜索结果边思考,加速15%性能不减中国人民大学团队在论文DLLM-Searcher中,第一次让扩散大语言模型(dLLM)学会了这种“一心二用”的本事。目前主流的搜索Agent,不管是Search-R1还是R1Searcher,用的都是ReAct框架。这个框架的执行流程是严格串行的:
来自主题: AI技术研报
8572 点击 2026-03-02 10:00