比全球最强推理引擎还快2倍,斯坦福、普林斯顿破解大模型「串行魔咒」
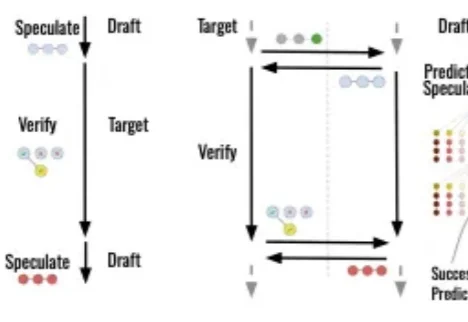
比全球最强推理引擎还快2倍,斯坦福、普林斯顿破解大模型「串行魔咒」在大语言模型推理领域,虽然「推测解码」(Speculative Decoding,SD)已成为加速生成的标准配置,但它依然存在一个致命弱点: drafting(草拟)和 verification(验证)之间必须串行进行。
来自主题: AI技术研报
8089 点击 2026-04-01 16:20
 搜索
搜索
在大语言模型推理领域,虽然「推测解码」(Speculative Decoding,SD)已成为加速生成的标准配置,但它依然存在一个致命弱点: drafting(草拟)和 verification(验证)之间必须串行进行。

您在使用LLM时,如果遇到它胡说八道或者彻底偏题,第一反应是什么?大概率是直接关掉窗口,新开一个对话,懒得跟机器废话。但您可能不知道,这个看似再正常不过的习惯,正在给下一代大语言模型的训练库疯狂“投毒”。
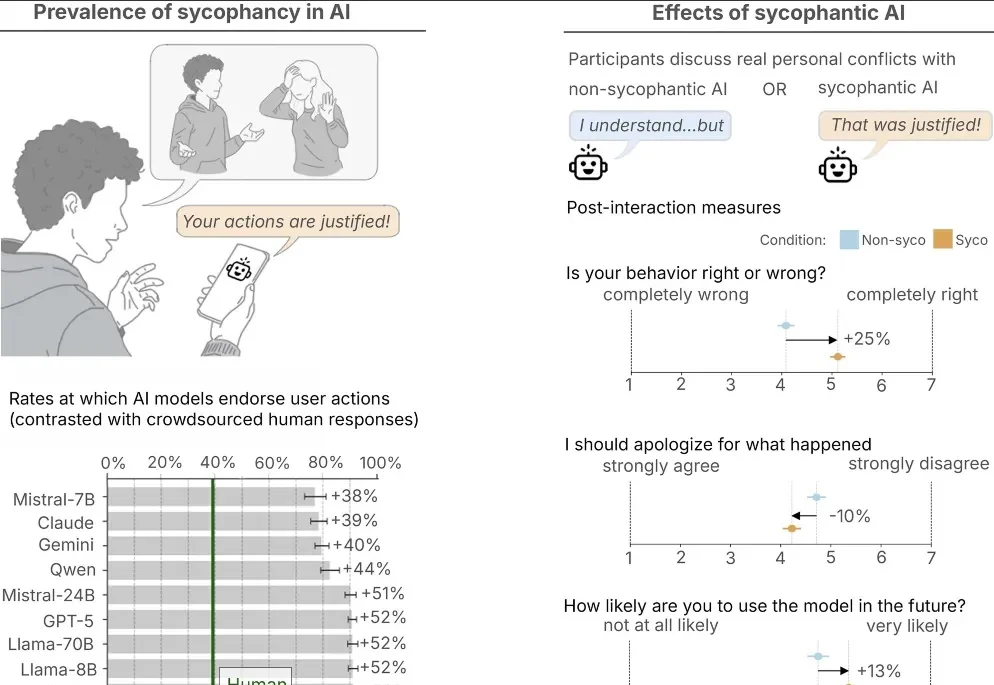
自从大语言模型诞生起至今,AI 已经润物无声地融入了我们的工作生活,也成为了现代社会的重要组成部分。
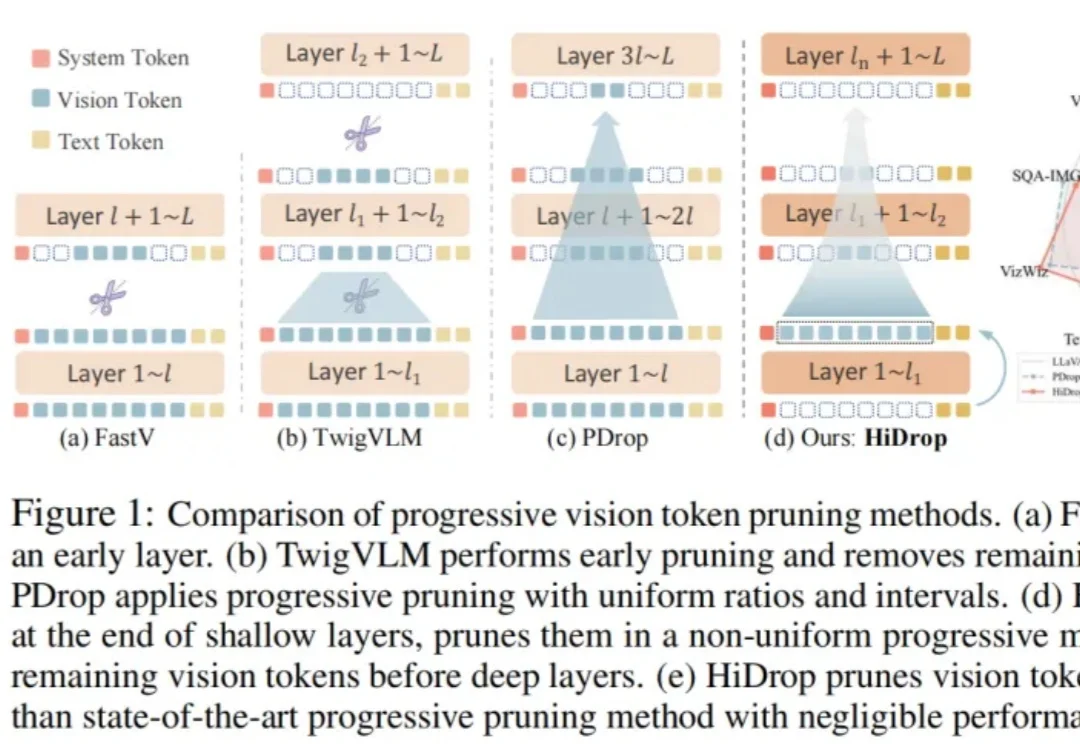
随着多模态大语言模型(MLLM)支持更长上下文,高分辨率图像和长视频会产生远多于文本的视觉 Token,在自注意力二次复杂度下迅速成为效率瓶颈。

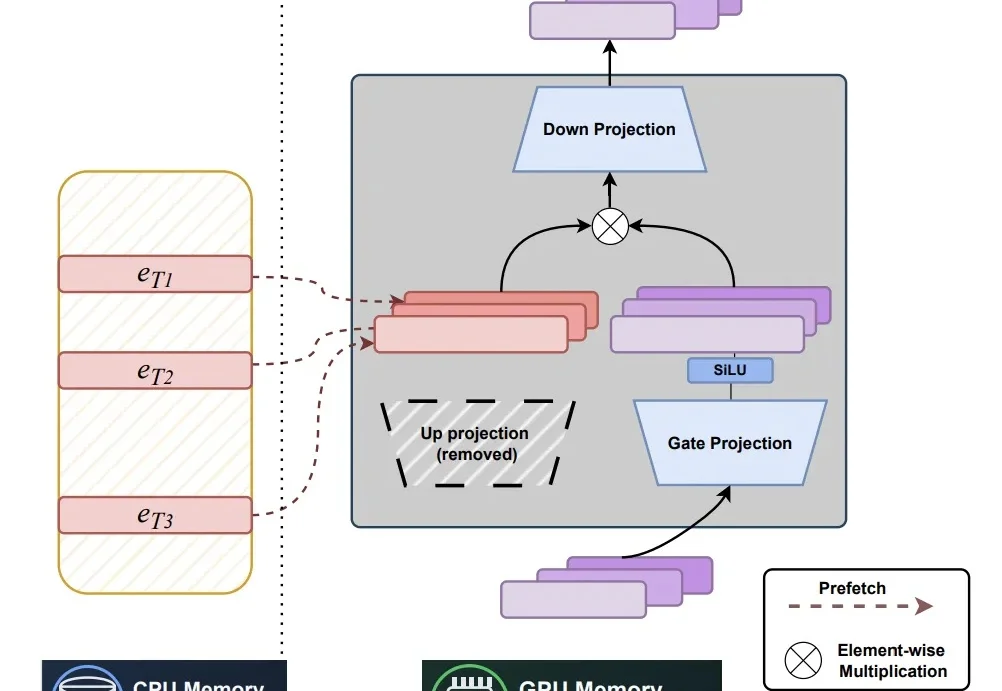
随着生成式 AI 迈入万亿参数时代,大语言模型(LLM)的推理与部署面临着前所未有的“显存墙”挑战。如何在超节点(SuperNode)复杂的异构存储架构下,实现海量张量的高效管理和调度,已成为大模型落地的胜负手。

大语言模型(LLM)的幻觉问题一直是阻碍其在关键领域部署的核心难题。近日,研究人员提出了一种名为行为校准强化学习(Behaviorally Calibrated Reinforcement Learning)的新方法,通过重新设计奖励函数,让模型学会「知之为知之,不知为不知」。

随着大语言模型 Agent 开始在对话、问答与复杂交互环境中长期运行,“记忆该如何设计” 正在成为一个绕不开的核心问题。

当前,大语言模型(LLMs)和视觉语言模型(VLMs)在语义领域的成功未能直接迁移至物理机器人,归根结底在于其互联网原生的基因。

昨日,OpenAI 宣布收购了 Promptfoo 以保障其 AI 智能体的安全。这家成立于 2024 年的 AI 安全初创公司,专注于保护大语言模型免受网络攻击。OpenAI 在一篇博客文章中表示,交易完成后,Promptfoo 的技术将整合进 OpenAI Frontier,该平台是其近期推出的、供企业构建和管理 AI 智能体的平台。
近年来,随着大语言模型规模与知识密度不断提升,研究者开始重新思考一个更本质的问题:模型中的参数应如何被组织,才能更高效地充当「记忆」。