# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
当强大的多模态大语言模型应用于地球科学研究时,它面临着无法忽视的 「阿克琉斯之踵」:
而今,这些 「致命伤」 终于迎来了它们的解药。想象一下,有一个能真正理解并执行复杂地球科学任务的 「AI 科学家」。它能够理解你的研究意图,像人类专家一样自主规划分析流程;可以处理原始光谱数据、遥感影像和地球产品,进行专业的指数计算和参数反演;能在多步骤推理中调用最合适的工具,完成从数据预处理到时空分析的全流程工作。
这一切不再是想象,由上海人工智能实验室与中山大学联合研发的 Earth-Agent,正在将这一愿景转化为现实。

想象一名地球科学领域的学生如何成为一个成熟的研究者?他需要在数年的学习中,从专业课程中汲取海量知识,将每一个理论和算法内化为自己心中的 「工具」。而后在面对真实的数据分析场景时从储备的 「工具库」 中精准挑选并串联起 「指标计算」、「参数反演」、「统计分析」 等一系列工具链路,最终形成解决复杂问题的完整工作流。
我们能否借助 AI 智能体(Agent)复现这一 「知识工具化」 与 「流程自动化」 的专家能力?

基于上述灵感,研究者构建了 Earth-Agent 的核心框架,其关键在于两个层面的构建:

Earth-Bench 包含 248 个专家标注的任务,涵盖 13,729 张图像,分布于三大模态:
与以往侧重于对单张或少量遥感影像进行描述(Captioning)、分类(Classification)或简单问答(VQA) 的基准不同的是,Earth-Bench 的核心在于评估智能体执行完整地球科学分析工作流的能力。
举一个例子:「利用 2022 年纽约市 Landsat 8 热成像和反射率数据,采用单通道方法基于 NDVI 和热波段 10 估算 LST,然后计算夏季和秋季的平均 LST,并确定平均差以评估这两个时期之间的季节性温度差值。A. 8.65K B. 10.89K C.12.42K D.14.75K。」可以看到,Earth-Bench 的题目不再局限于对于原始地球观测数据进行简单的一步即可完成的描述、分类、计数任务,而是强调利用地球科学的知识进行严格的指标计算和时空分析。
Earth-Bench 只有 248 个题目,但是需要处理 13729 张 image 图像,平均每个题目需要处理 55 张影像,平均每个问题需要 5.4 步才能完成。这意味着智能体必须具备批量数据处理、时序分析和跨文件信息整合的能力,这直接对应了真实地球科学研究中处理大规模观测数据的核心需求。

另一方面,以往的 Agent 基准测试陷入了 「唯结果论」 的陷阱,侧重于最终结果的准确性而忽视了对于 Agent 推理轨迹的评估。
研究者认为 「怎么得出这个结论」 的过程和结论本身同样重要,因此邀请了一支由遥感专业研究生组成的专家小组针对 Earth-Bench 的每一个问题都进行逐步的解答求得最终结果。他们把每一步调用了什么工具、输入了什么参数、得到了什么中间结果,都完整地记录了下来。 这就形成了一条条标准的 「专家推理轨迹」。接着将专家推理轨迹纳入到了 step-by-step 评估,并将最终的答案和效率纳入到了结果的 end-to-end 评估。

实验一:比较不同的 LLM Backbone
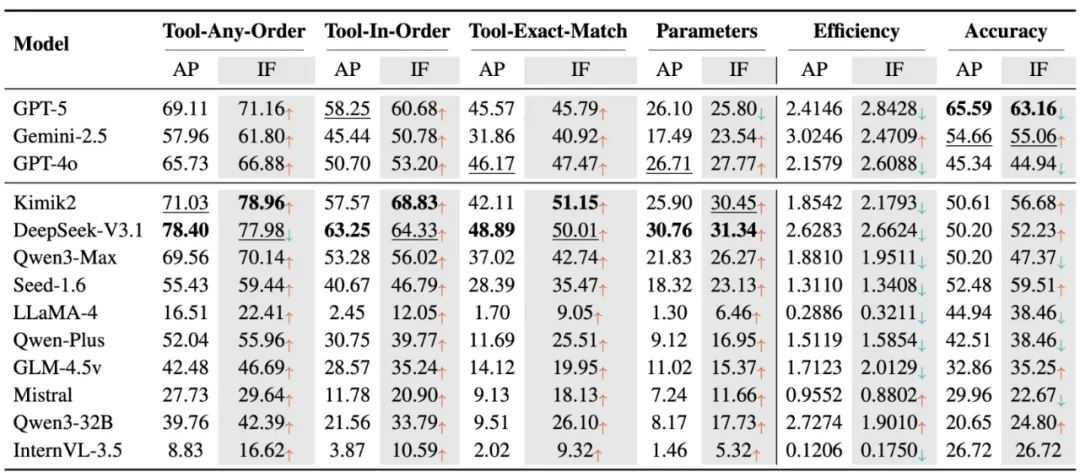
通过对 GPT、Gemini、Kimik2、DeepSeek、Qwen 等主流模型的测试,评测结果揭示了进行工具调用(Tool Calling)预训练的语言模型表现大幅领先于没有进行工具调用预训练的模型。闭源模型最终准确率更高,但 DeepSeek-V3.1 和 Kimik2 在推理过程中工具使用的准确率上超越 GPT-5。
研究者还对比了 Query 中不进行步骤提示的 Auto Planning(AP)和在 Query 中加入步骤提示的 Instruct Following (IF) 的实验结果,可以发现 IF 可以提升工具的感知准确率,但是往往会使得智能体在中间过程中引入无关的工具,使得效率下降并引起级联误差,导致最终的准确率不一定上升。
实验二:与通用的 Agent 架构的对比

实验三:与 MLLM 方法的对比

研究者还将 Earth-Agent 和通用的 Agent 架构以及 MLLM 方法进行了横向对比,可以发现 Earth-Agent 在各个 Spectrum、Products、RGB 三个模态的效果领先于通用的 Agent 架构,并且在经典的遥感分类、检测、分割任务中相比于 MLLM 都取得了领先的性能,这验证了 Earth-Agent 在地球观测任务的巨大应用前景。
消融实验

为了验证 Earth-Agent 的能力提升来自于 LLM 对于工具的调用而非其他的因素,研究者对 Earth-Agent 进行了系统的消融实验,划分为 A 组:不使用工具;B 组:使用工具。结果表明,在 LLM 无法使用工具的情况下,不同的 LLM 准确率都在 37%(图中蓝色虚线)。
而允许 LLM 调用工具后,不同的 LLM 对于地球科学问题的回答准确性提升出现了明显的差异。GPT5 的回答准确率提升到了 65%;Gemini-2.5、DeepSeek-V3.1、Kimik2、Qwen3-max 的回答准确率提升到 50%,GPT-4o 的回答准确率仅提升到 45%。
Earth-Agent 为地球观测数据分析提供了一个新的学习范式:不再像 MLLM 将全部能力编码到大模型预训练的参数中,而是将能力外化为一个结构化的、可随时调用的工具库,让大模型扮演一个了解 「何时调度和决策」 的大脑。这种范式更接近我们人类的学习和工作方式:我们并非把所有知识都记在脑子里,而是学会在需要时,精准地选择并使用合适的工具。Earth-Agent 未来还有广阔的发展前景:
文章来自于“机器之心”,作者“冯沛林和吕主涛”。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
