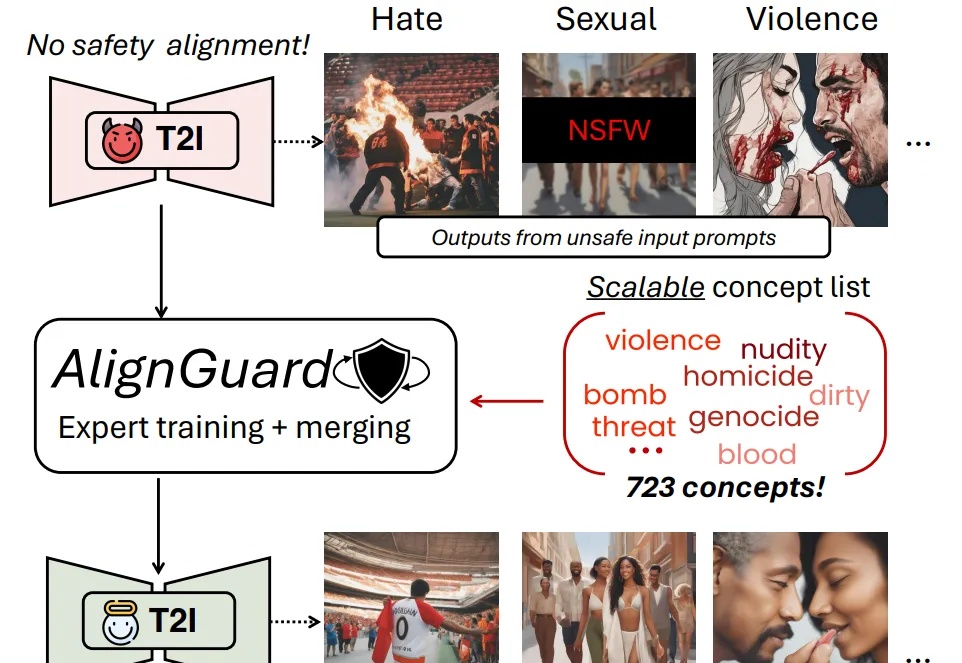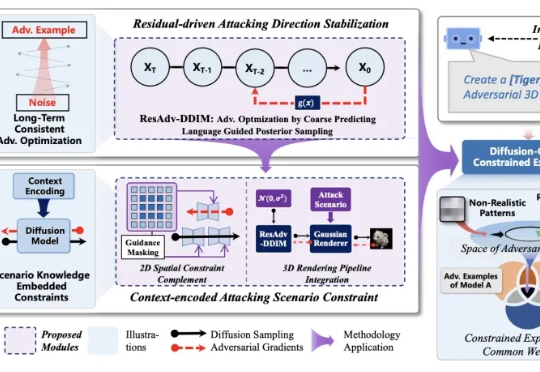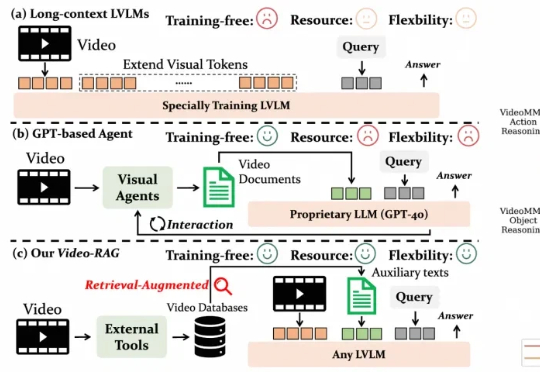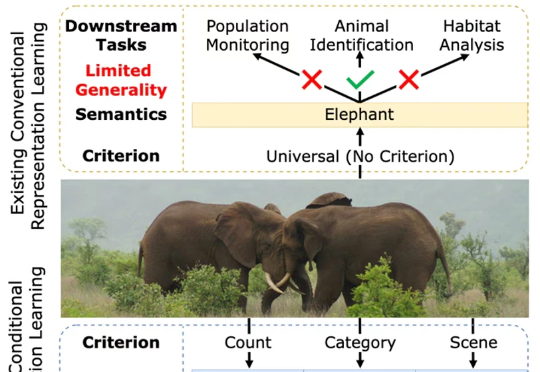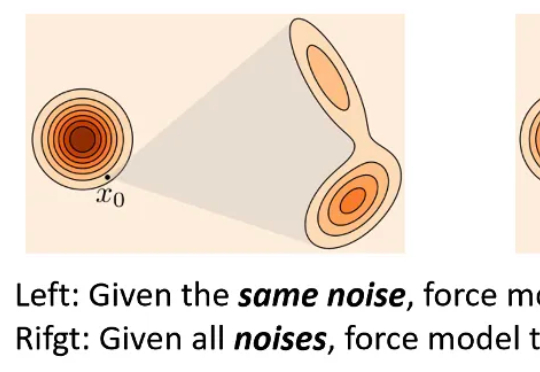
重新定义跨模态生成的流匹配范式,VAFlow让视频「自己发声」
重新定义跨模态生成的流匹配范式,VAFlow让视频「自己发声」在多模态生成领域,由视频生成音频(Video-to-Audio,V2A)的任务要求模型理解视频语义,还要在时间维度上精准对齐声音与动态。早期的 V2A 方法采用自回归(Auto-Regressive)的方式将视频特征作为前缀来逐个生成音频 token,或者以掩码预测(Mask-Prediction)的方式并行地预测音频 token,逐步生成完整音频。
来自主题: AI技术研报
8796 点击 2025-10-31 15:00