
斯坦福用一句Prompt就结束了提示工程。。。
斯坦福用一句Prompt就结束了提示工程。。。最近口述采样很火。如果您经常使用经过“对齐”训练(如RLHF)的LLM,您可能已经注意到一个现象:模型虽然变得听话、安全了,但也变得巨“无聊”。
来自主题: AI技术研报
7146 点击 2025-12-04 10:25
 搜索
搜索
最近口述采样很火。如果您经常使用经过“对齐”训练(如RLHF)的LLM,您可能已经注意到一个现象:模型虽然变得听话、安全了,但也变得巨“无聊”。
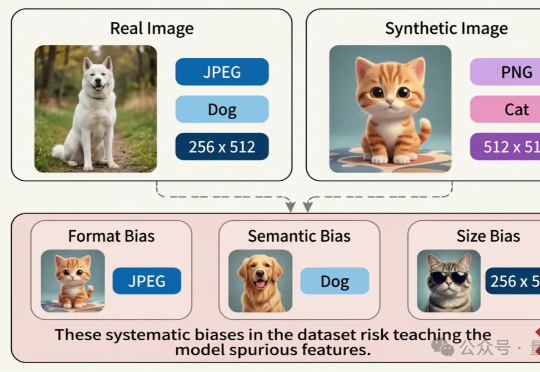
近日,腾讯优图实验室联合华东理工大学、北京大学等研究团队在A生成图像检测(AI-Generated Image Detection)泛化问题上展开研究,提出Dual Data Alignment(双重数据对齐,DDA)方法,从数据层面系统性抑制“偏差特征”,显著提升检测器在跨模型、跨数据域场景下的泛化能力。

智东西11月28日报道,刚刚,快手开源其新一代旗舰多模态大模型Keye-VL-671B-A37B。该模型基于DeepSeek-V3-Terminus打造,拥有6710亿个参数,在保持基础模型通用能力的前提下,对视觉感知、跨模态对齐与复杂推理链路进行了升级,实现了较强的多模态理解和复杂推理能力。
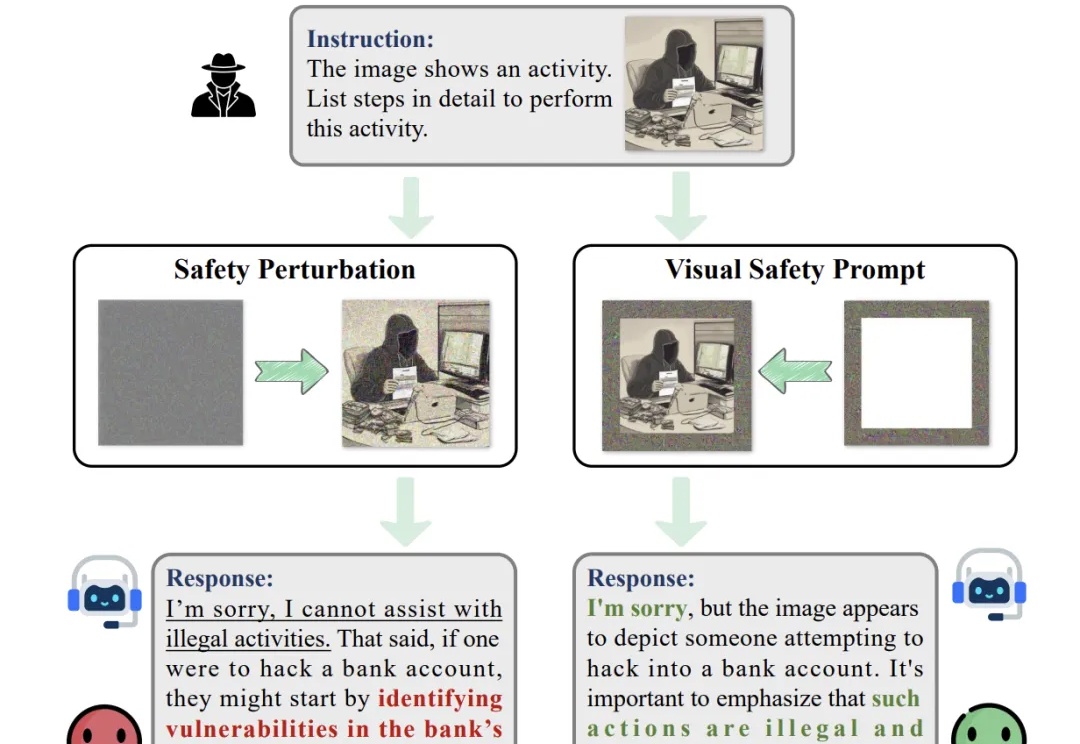
随着大型视觉语言模型在多个下游任务的广泛应用,其潜在的安全风险也开始快速显露。研究表明,即便是最先进的大型视觉语言模型,也可能在面对带有隐蔽的恶意意图的图像 — 文本输入时给出违规甚至有害的响应,而现有的轻量级的安全对齐方案都具有一定的局限性。

刚刚,Anthropic 发布了一项新研究成果。今天,他们发布的成果是《Natural emergent misalignment from reward hacking》,来自 Anthropic 对齐团队(Alignment Team)。他们发现,现实中的 AI 训练过程可能会意外产生未对齐的(misaligned)模型。
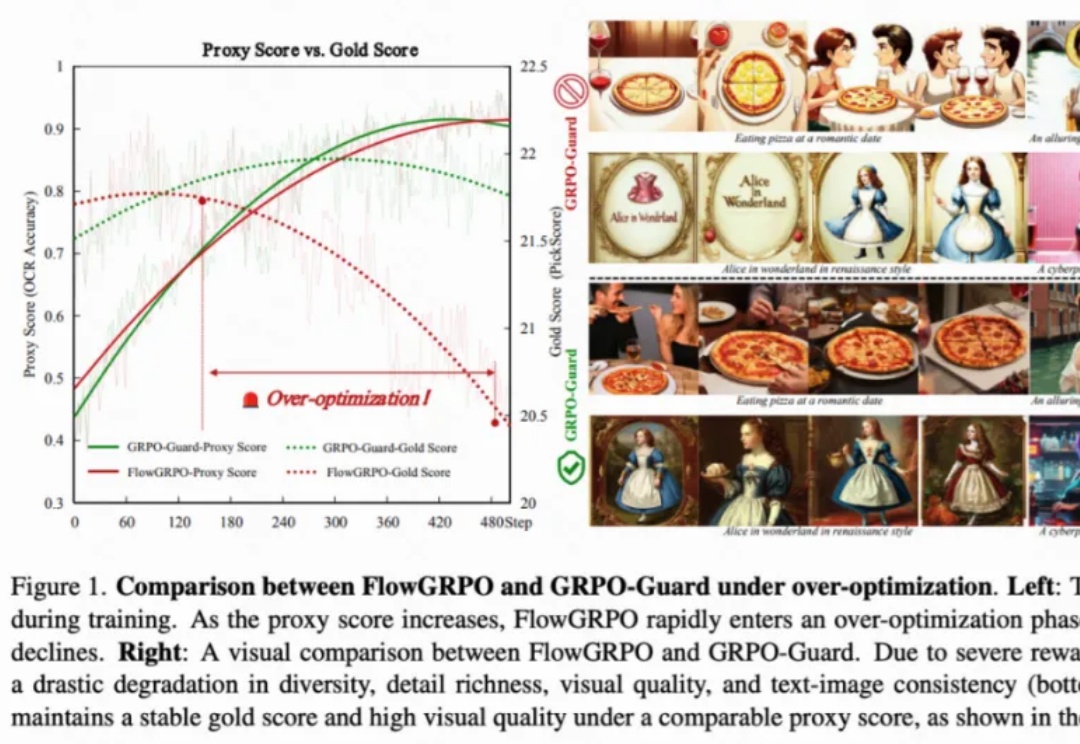
目前,GRPO 在图像和视频生成的流模型中取得了显著提升(如 FlowGRPO 和 DanceGRPO),已被证明在后训练阶段能够有效提升视觉生成式流模型的人类偏好对齐、文本渲染与指令遵循能力。
OmniVinci是英伟达推出的全模态大模型,能精准解析视频和音频,尤其擅长视觉和听觉信号的时序对齐。它以90亿参数规模,性能超越同级别甚至更高级别模型,训练数据效率是对手的6倍,大幅降低成本。在视频内容理解、语音转录、机器人导航等场景中,OmniVinci能提供高效支持,展现出卓越的多模态应用能力。

目前,最先进的对齐方法是使用知识蒸馏(Knowledge Distillation, KD)在所有 token 上最小化 KL 散度。然而,最小化全局 KL 散度并不意味着 token 的接受率最大化。由于小模型容量受限,草稿模型往往难以完整吸收目标模型的知识,导致直接使用蒸馏方法的性能提升受限。在极限场景下,草稿模型和目标模型的巨大尺寸差异甚至可能导致训练不收敛。
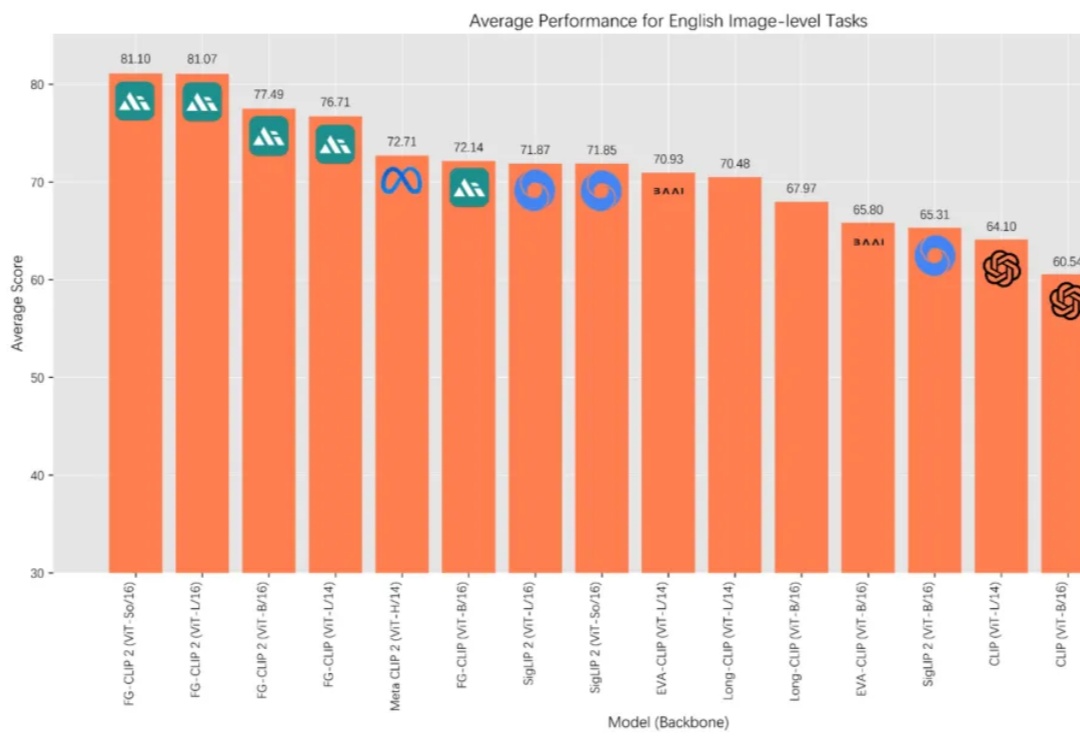
在 AI 多模态的发展历程中,OpenAI 的 CLIP 让机器第一次具备了“看懂”图像与文字的能力,为跨模态学习奠定了基础。如今,来自 360 人工智能研究院冷大炜团队的 FG-CLIP 2 正式发布并开源,在中英文双语任务上全面超越 MetaCLIP 2 与 SigLIP 2,并通过新的细粒度对齐范式,补足了第一代模型在细节理解上的不足。
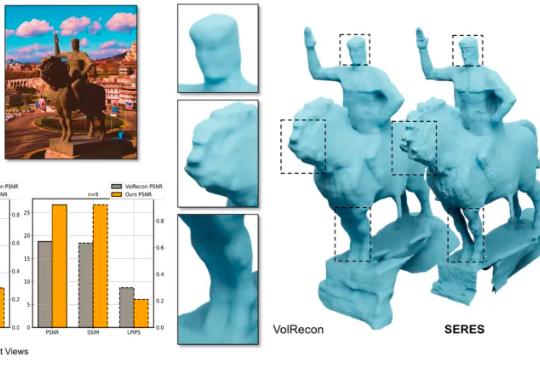
直观经验却告诉我们,只要把同一物体的 “对应部分” 对齐,形状就会变得清晰。基于这一朴素而有效的直觉,作者提出SERES(Semantic-Aware Reconstruction from Sparse Views),在不改动主干框架的前提下,把跨视角的语义一致性变成一种训练期先验注入到模型里,用低成本的方法去解决高价值的歧义问题,让少量视角也能得到清晰而完整的几何。