# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在当今AI技术迅猛发展的背景下,大语言模型(LLM)的评估问题已成为一个不可忽视的挑战。传统的做法是直接采用最强大的模型(如GPT-4)进行评估,这就像让最高法院的大法官直接处理所有交通违章案件一样,既不经济也不一定总能保证公正。一项来自ICLR 2025的匿名研究为这个问题提供了一个突破性的解决方案。

🌈
💡核心创新:这项研究首次提出了具有数学保证的级联评估框架,既能确保评估质量,又能显著降低成本。
想象你正在评估两个AI助手对于以下数学问题的回答:"如何计算圆的面积?"
助手A的回答:
用半径乘以半径再乘以3.14就可以了。
助手B的回答:
计算圆的面积使用公式:A = πr²
其中:
- A 是面积
- r 是半径
- π 约等于3.14159
例如:如果半径是2厘米,则:
A = 3.14159 × 2² = 12.57 平方厘米
🤔 评估困境:哪个回答更好?助手A简洁明了但可能过于简化,助手B详细完整但似乎有些冗长。即使是经验丰富的教师,面对这样的问题也可能产生分歧。这就引出了一个核心问题:如何构建一个既可靠又高效的自动评估系统?
1.可靠性无保证:目前普遍采用的"问问GPT-4"方法存在系统性偏差和过度自信的问题。即使是最先进的GPT-4,其评估结果与人类判断的一致性也往往难以突破80%的天花板。
2.成本效率低下:完全依赖大模型进行评估不仅成本高昂,而且处理效率低下。就像让最高法院大法官处理每一起交通违章一样,这种做法既浪费资源又不够经济。
3.缺乏理论保证:现有方法无法提供严格的数学保证,这在关键应用场景中可能带来严重问题。特别是在医疗、金融等高风险领域,这种不确定性是不可接受的。
研究者提出了一个关键洞察:一个可靠的评估系统不应该盲目相信任何单一模型的判断,而是要建立一个类似司法体系的多级评审机制,每个"评审员"都需要对自己的判断进行可靠性评估。这种思路启发了"级联选择性评估"框架的诞生。
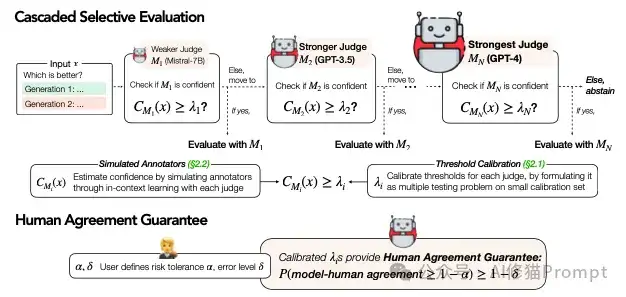
框架包含三个关键组件:
1.多级评估模型:从轻量级的Mistral-7B到强大的GPT-4,形成一个成本递增的评估链。
2.置信度评估:每个模型都配备了精密的置信度检测机制,用于决定是否需要升级到更强大的模型。
3.数学保证:通过严格的理论推导,确保评估结果与人类判断具有可证明的一致性。

想象你正在运营一个大型AI客服系统,每天需要评估数十万条对话质量。就像一个高效的司法体系,我们的算法建立了一个智能化的分级处理机制:
1.评估准备工作(输入参数设计)
2.智能分流机制(评估流程) 拿客服质量评估为例:
3.资源优化策略(优化机制) 假设每天有10万条对话需要评估:

这就像是一个不断自我完善的司法体系:
1.系统初始化 实际应用案例:新上线的电商客服评估系统
2.动态优化过程 以电商场景为例:
3.持续改进机制 系统会自动识别和适应新的场景:
不要被数学公式吓到,这个保证其实很容易理解:
想象你是一位品控经理,系统向你承诺:"如果我对某个评估结果打了'高可信度'的标签,那么这个评估有至少90%(假设α=0.1)的几率与人类专家判断一致。而且这个承诺是有数学证明支持的,不是空口白话。"
具体到实践中:
这种设计就像一个训练有素的团队:初级评审员处理简单案例,有疑问就请教高级评审员,遇到关键决策时才惊动最资深的专家。这不仅提高了效率,更保证了质量。
研究团队在三个主要数据集上进行了全面测试:

1.评估准确性
2.资源效率
3.泛化能力
1.评估流水线搭建
2.校准过程优化
1.分层策略
2.质量监控
这项研究不仅提供了一个强大的评估框架,更重要的是开创了一个全新的评估范式。通过将人类的司法智慧与现代AI技术相结合,研究者们展示了如何在保证质量的同时实现资源的高效利用。这对整个AI领域的发展都具有深远的启示意义。
对于实践者而言,这意味着:
通过这个框架,我们终于可以构建真正可靠且经济的AI评估系统,这将加速AI技术的健康发展。
文章来自于“AI修猫Prompt”,作者“AI修猫Prompt”。



【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
