ICML 2026|让奖励模型更准更高效,TikTok、NUS提出置信度门控
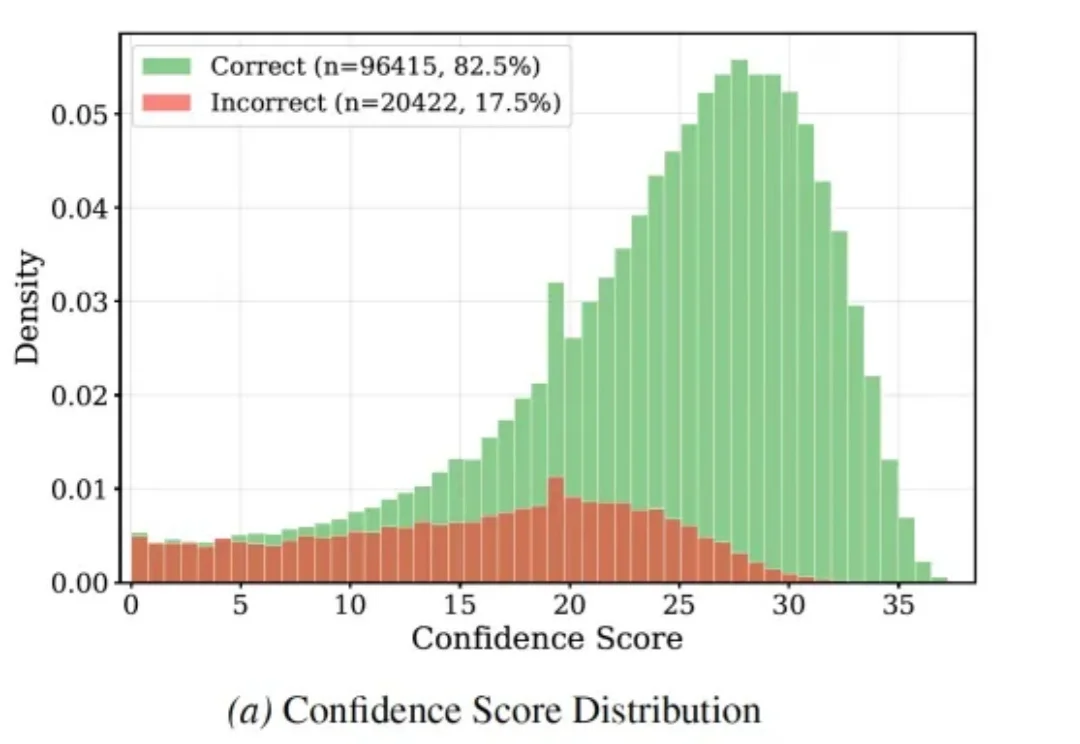
ICML 2026|让奖励模型更准更高效,TikTok、NUS提出置信度门控奖励模型(Reward Model, RM)是大语言模型对齐的核心组件,负责为模型输出提供符合人类偏好的评价信号。现有方法各有短板:标量判别式 RM 高效稳定但可解释性有限;生成式 judge 能给出判断理由,却需为每个样本生成长 reasoning,token 与延迟开销显著。
来自主题: AI技术研报
7198 点击 2026-07-13 14:44