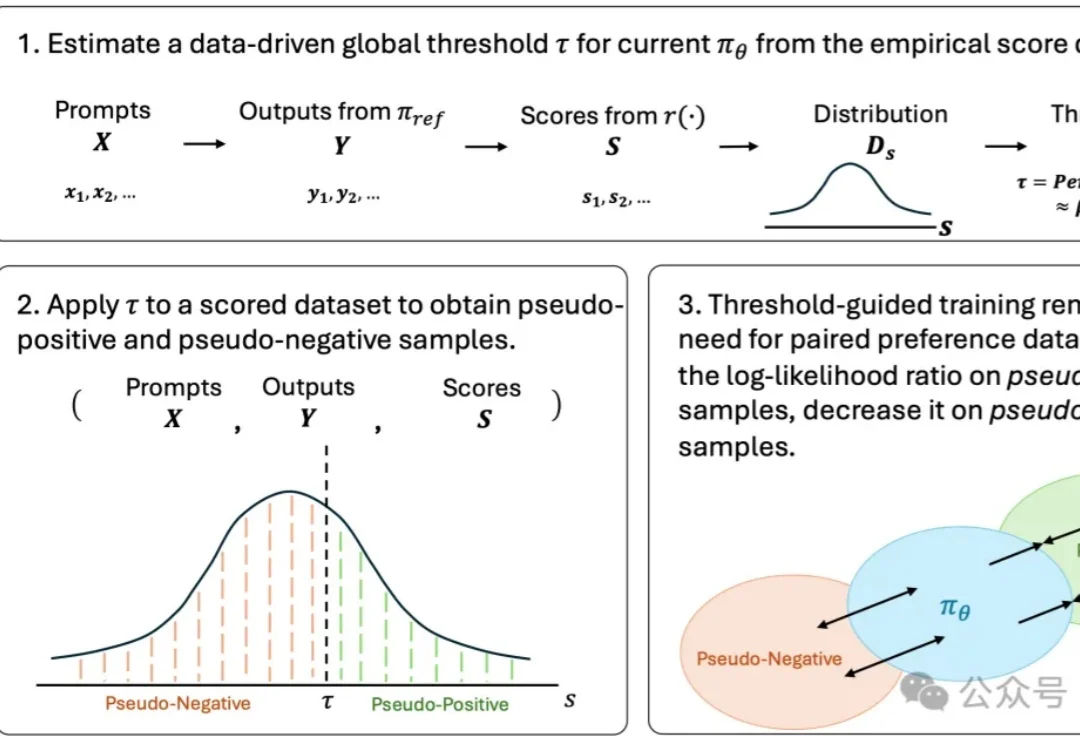
无需构造偏好对:TGO用标量反馈对齐视觉生成模型|ICML'26
无需构造偏好对:TGO用标量反馈对齐视觉生成模型|ICML'26生成模型的偏好对齐,可能正在进入一个新的阶段。
来自主题: AI技术研报
10670 点击 2026-05-18 09:54
 搜索
搜索
生成模型的偏好对齐,可能正在进入一个新的阶段。

在多模态大模型(MLLM)快速发展的浪潮中,融合多模型 “集体智慧” 已成为提升模型性能的关键路径,并催生了多教师知识蒸馏这一主流范式。然而,不同来源的教师模型在架构与优化上的差异,其在相似推理过程中呈现出不稳定甚至偏移的认知轨迹,即 “概念漂移”(Concept Drift)。

有个31B参数的大模型,正常需要80GB显存才能跑。但现在,24GB显存就能跑满血版。这个版本叫Gemma-4-31B-JANG_4M-CRACK——"CRACK"这个词不要理解歪了,它本质是量化压缩加上对齐微调之后的部署版本,不是什么黑客攻击,就是工程优化。24GB,MacBook Pro,直接跑。苹果用户优先优化,MLX原生支持,月下载13000次。

为了解决这一痛点,由 MBZUAI、复旦大学、中国人民大学高瓴人工智能学院以及哈佛大学联合组成的研究团队,提出了一种名为 Laser 的全新隐式视觉推理范式。该研究从认知心理学中汲取灵感,引入了 “Forest-before-Trees” 的认知机制,通过动态窗口对齐学习(DWAL),首次实现了在隐空间中维持视觉特征的 “概率叠加” 状态。

在代码大模型和代码智能体技术快速发展的今天,一个日益凸显的现象是:能够在经典代码生成基准上取得优异成绩的模型,一旦被放入真实软件工程环境中,表现却往往大幅下滑。

最近,谷歌联合ResNet作者何恺明、谢赛宁、NeRF先驱Jonathan T. Barron、 3D图形学名家Thomas Funkhouser,正式发布了Vision Banana。它向世界宣告:视觉AI终于不再需要那些臃肿的任务头了,理解,本质上只是生成过程中的一次「对齐」。

当强化学习后训练的大规模 rollout 已经被证明能够提升图像生成模型的偏好对齐能力,推理负担就成了制约训练速度的核心瓶颈。来自 NVIDIA、港大和 MIT 的团队提出的 Sol-RL,通过「FP4 先探索、BF16 再训练」的后训练框架,将达到等效 reward 水平的收敛速度最高提升到 4.64x,在训练速度与对齐效果之间给出了一条更具工程可行性的解法。

4 月 10 日晚,灵初智能发布了大模型、数据集与合作计划:包括策略模型 Psi-R2、世界模型 Psi-W0,以及总规模近 10 万小时的人类操作数据。它想回答的问题也很直接 —— 当真机数据不再是唯一解,机器人还能靠什么继续 scaling?

郭亚楠说,Context就承接了新需求。传统OS让人和软件对齐,新OS应该让人和Agent对齐。因为Context是个人数据的结构化、语义化集合,它就像OS管理内存和CPU一样管理每个人的数字痕迹。
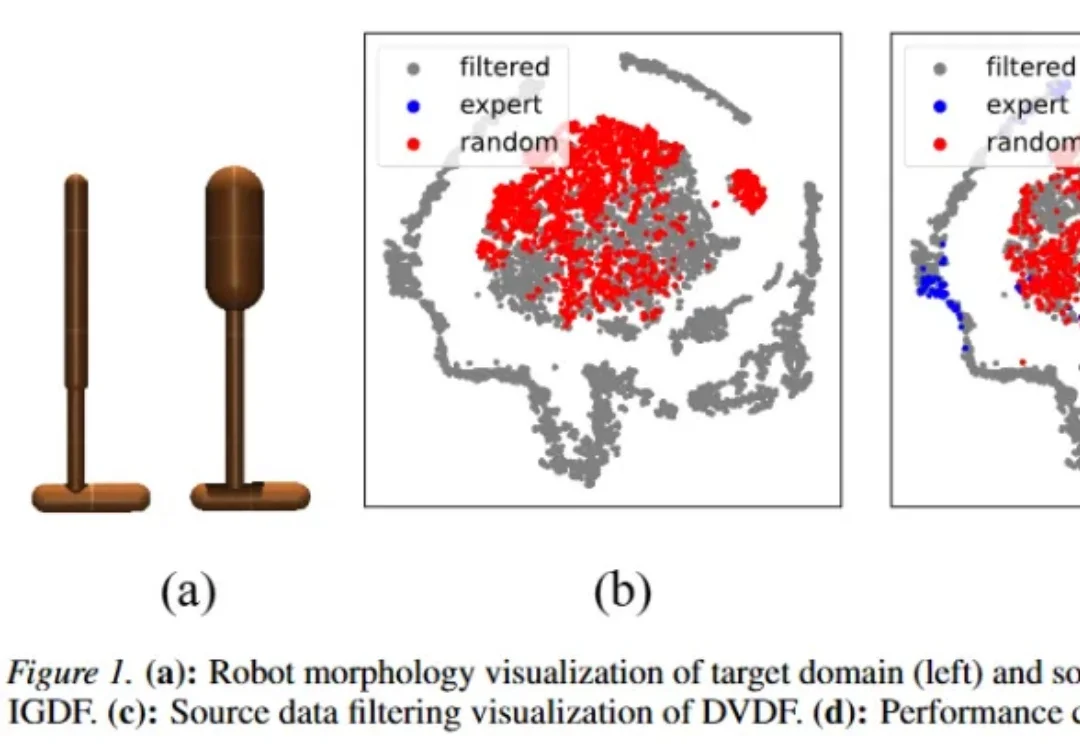
在现实世界中通过强化学习训练智能体,往往需要大量在线试错与环境探索,这不仅成本高昂,还可能带来显著安全风险:机器人可能因试错而损坏,自动驾驶的在线探索可能危及行车安全,而持续采集交互数据本身也代价巨大。