# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
最近,我们团队的一位工程师在研究类 ColPali 模型时,受到启发,用新近发布的 jina-clip-v2 模型做了个颇具洞察力的可视化实验。
实验的核心思路是,对给定的图像-文本对,计算文本里每个词的向量(token embeddings)和图像里每个图像块的向量(patch embeddings),计算它们之间的相似度。然后,把这些相似度数值映射为热力图,叠加在图像之上,就能直观地看到文本 token 和图像 patch 之间的关联模式。

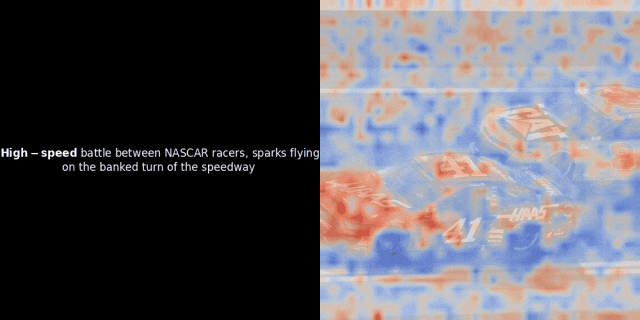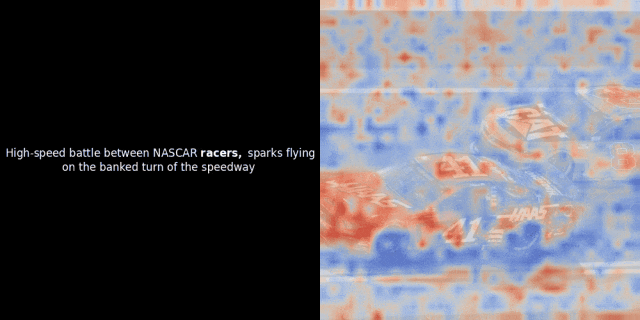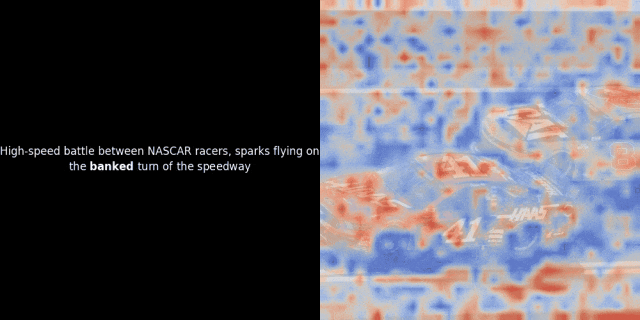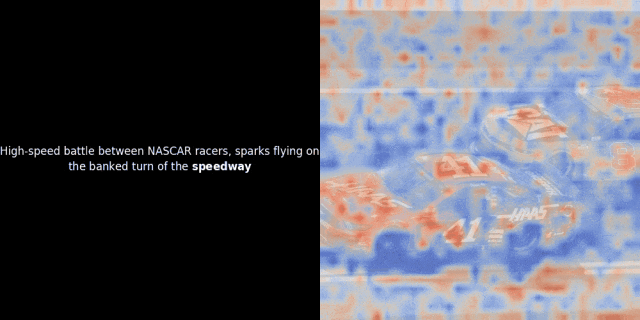
注意:这种可视化方法只是我们一种启发式的尝试,并非模型内部的固有机制。像 CLIP 这样的模型,用全局对比方法来训练,确实有可能(而且经常)在图像块和文本词元之间产生一些局部的对应关系,但你要知道,这只是全局对比训练过程中的一个“副产品”,不是它直接想要达到的目标。
接下来,我将详细解释其中的缘由。
我们已经看到了直观的对比可视化效果,但 jina-clip-v2 模型本身并不直接提供文本 Token 或图像 Patch 级别的向量表示。那么,为了实现这种效果,背后的代码是如何运作的呢?
接下来,我们将深入代码,从宏观层面了解其功能。
Google Colab: https://colab.research.google.com/drive/1SwfjZncXfcHphtFj_lF75rVZc_g9-GFD
通过设置 model.text_model.output_tokens = True,调用 text_model(x=...,)[1] 将会返回一个形状为 (batch_size, seq_len, embed_dim) 的张量,这里索引为 1 的元素,就是我们需要的词元(token)级别的向量表示。
具体来说,模型先用 Jina CLIP 分词器把句子拆成词元,其中有些是完整的词,有些是子词(sub-word)。为了得到每个词的向量表示,模型会把构成同一个词的子词向量求平均,把它们拼回成完整的词。另外,代码通过检查词元是否以 _ 开头来判断新词的起始位置,这是 SentencePiece 分词器的一个小特点,它用 _ 来标记一个新词的开始。
最后,我们会得到两个列表:一个是词向量的列表,另一个是对应词语的列表,比如 "Dog" 对应一个向量,"and" 对应另一个向量。
在图像处理方面,vision_model(..., return_all_features=True) 函数会返回一个形状为 (batch_size, n_patches+1, embed_dim) 的张量。
其中,索引为 0 的是 [CLS] token,代表全局图像特征,我们忽略它。我们提取索引 1 开始的 n_patches 个向量,这些是图像块的向量表示。接着,将这些向量重塑为 patch_side × patch_side 的二维网格,以恢复其在原图上的空间布局。最后,对该网格进行上采样,使其分辨率与原始图像匹配。
相似度计算和热力图生成,是常用的后验可解释性分析方法。
具体而言,该过程会选取一个文本的向量表示,并计算其与每个图像块向量表示之间的余弦相似度。然后,基于这些相似度值生成热力图,从而直观地展示哪些图像块与该特定 Token 的向量表示具有最高的相似度。最后,代码会遍历句子中的每个 Token,在图像左侧以粗体突出显示当前 Token,并在右侧的原始图像上叠加与其相似度相关的热力图。这些帧将被组合成一个动态的 GIF 图像。
如果仅从代码逻辑的角度来看,答案是肯定的。
代码的逻辑是连贯的,能够为每个文本词语生成相应的热力图。最终,我们会得到一系列展示对应的图像块相似度的帧序列,因此可以说我们的代码确实“达成了预期的目标”。


观察上面的例子,我们似乎可以看到像 "moon" 和 "branches" 这样的词语与原始图像中相应的视觉区域实现了较好的对齐。但关键的问题在于:这种看似的对齐真的具有实际意义吗?或者,我们只是观察到了一种偶然现象?
这实际上是一个更深层次的问题。要理解其中的关键所在,我们有必要回顾一下 CLIP 模型的训练方式:
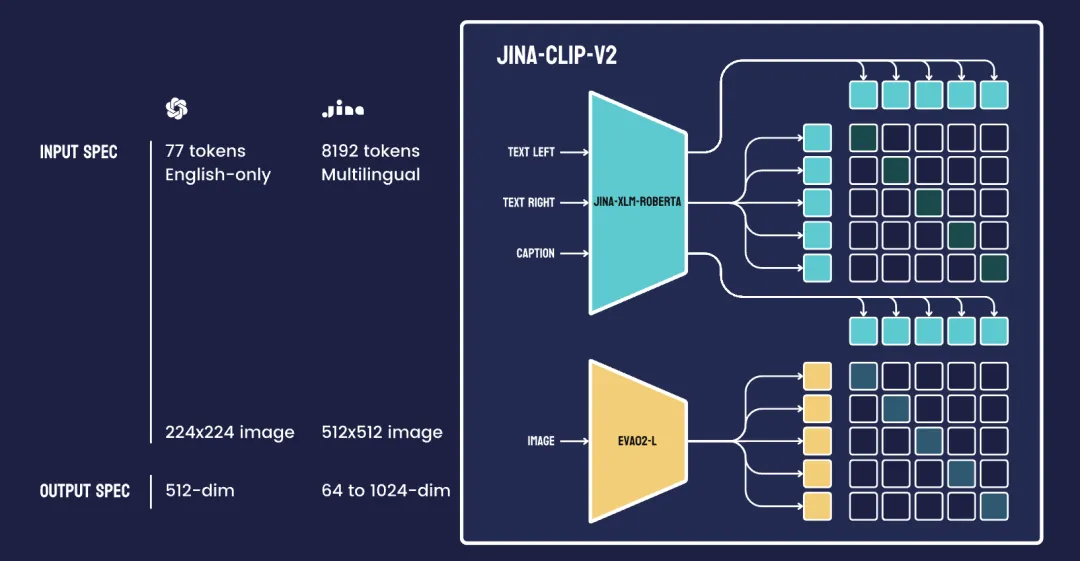
Jina-CLIP v2 模型结合了文本编码器(Jina XLM-RoBERTa,包含 561M 参数)和视觉编码器(EVA02-L14,包含 304M 参数)。图中右侧的每个彩色方块代表一个批次中的完整句子或图像,而不是单独的 token 或图像 patch。
总而言之,这种可视化方法只是一种启发式的手段。任何给定的图像 patch 向量表示与特定 token 向量表示之间的接近或远离,在一定程度上是模型自然涌现的结果。它更类似于一种后验的可解释性技巧,而非模型所具备的稳健或官方的注意力机制。
为什么我们有时会观察到词语与图像块之间存在局部对齐的现象呢?
实际上,尽管 CLIP 模型是在全局图像-文本对比学习的目标下进行训练,其内部仍然运用了自注意力机制(在基于 ViT 的图像编码器中)以及 Transformer 层(用于文本处理)。在这些自注意力层中,图像向量表示的不同区域能够相互作用,就像文本向量表示中的词语之间会彼此关联一样。
得益于海量图像-文本数据集的训练,模型得以自然而然地发展出内在的潜在结构,进而能够有效匹配整体图像与对应的文本描述。



局部对齐之所以会在这些潜在表示中出现,至少可以归结为以下两个主要原因:
1. 共现模式
如果模型在训练过程中,频繁地观察到“狗”的图像旁边出现“猫”的图像(通常伴随着包含这些词语的标签或描述),它就可能会学习到与这些概念大致对应的潜在特征。因此,表示“狗”的向量表示,可能会趋向于接近那些描绘狗的形状或纹理的局部图像块。需要强调的是,这种关联并不是在图像块级别上进行显式监督的,而是从 “狗” 图像/文本对的重复关联中自然涌现出来的。
2. 自注意力机制
在 Vision Transformer 架构中,不同的图像块之间能够相互关注。那些在视觉上较为显著的图像块(例如,狗的脸部),最终可能会得到一个一致的潜在“特征”,这是因为模型试图为整个场景生成一个全局准确的表示。如果这种特征能够有助于最小化整体的对比损失,它就会得到进一步的加强。
CLIP 模型的对比学习目标是,最大化匹配的图像-文本对之间的余弦相似度,同时最小化不匹配对之间的相似度。
假设文本和图像编码器分别生成文本 token 的向量表示和图像 patch 的向量表示:
全局相似度可以表示为局部相似度的加权平均:
当特定的 token-patch 对在训练数据中频繁共现时,模型会通过累积梯度更新来增强它们的相似度:
其中 为共现次数,这使得 的值显著增加,进而促进了这些对的局部对齐。然而,对比损失会将梯度更新分散到所有 token-patch 对上,从而限制了任何特定配对的增强程度:
这可以抑制对单个 token-patch 相似性的显著增强。
因此,CLIP 的 token-patch 可视化,巧妙地利用了文本和图像表示之间偶然的、自发的对齐关系。这种对齐非常有趣,但说到底还是 CLIP 用全局对比方法训练出来的,想要它提供准确又靠谱的解释,就有点勉强了。产生的可视化结果,也常常出现噪声,不太稳定。
相比之下,像 ColBERT 和 ColPali 这样的迟交互模型,就在架构上专门设计了文本词和图像块之间明确的、细粒度的对应关系,来解决 CLIP 的这些问题。它们先分别处理文字和图像,然后在后期专门算它们之间的相似度,这样就能保证每个文本词语都能与相关的图像区域建立起实实在在的关联,这才是更有解释力的做法。
文章来微信公众号“Jina AI”,作者“肖涵”




【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
