# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
核心作者包括顾纪豪,王瑛瑶。工作由淘天集团算法技术 - 未来生活实验室团队主要完成。为了建设面向未来的生活和消费方式,进一步提升用户体验和商家经营效果,淘天集团集中算力、数据和顶尖的技术人才,成立未来生活实验室。实验室聚焦大模型、多模态等 AI 技术方向,致力于打造大模型相关基础算法、模型能力和各类 AI Native 应用,引领 AI 在生活消费领域的技术创新。
近年来,视觉大模型(Large Vision Language Models, LVLMs)领域经历了迅猛的发展,这些模型在图像理解、视觉对话以及其他跨模态任务中展现出了卓越的能力。然而,随着 LVLMs 复杂性和能力的增长,「幻觉现象」的挑战也日益凸显。
为有效缓解 LVLMs 中的幻觉现象,团队提出了一种创新的令牌级偏好对齐方法(Token Preference Optimization,TPO),针对性设计了一个能够自我校准的视觉锚定奖励信号。
该方法首次在多模态偏好对齐领域实现了自动校准奖励,优化每个令牌生成时与视觉信息的相关性。同时,它也是多模态领域首个无需人工细粒度标注的令牌级偏好优化方法,从而提升了模型的优化效率和自动化水平。

现如今的 DPO 方法通过直接对齐人类偏好,在缓解大型视觉语言模型幻觉问题方面取得了显著成效。然而它仍然面临两个问题:
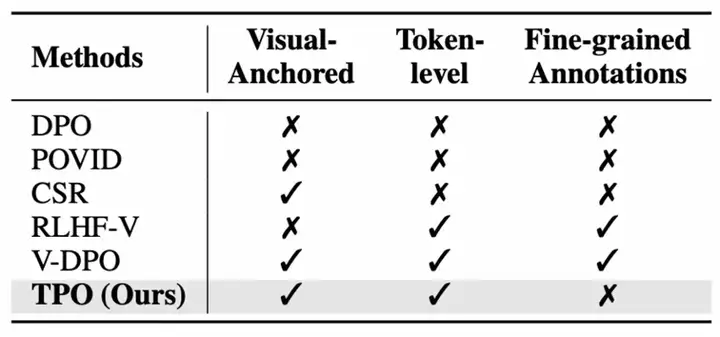
图 1:TPO 方法和其它消除幻觉的 DPO 改进方法的对比。比较了是否关注视觉锚定信息,是否生成 token-level 的监督信号和是否需要细粒度标注。比较的方法包括 DPO、POVID、CSR、RLHF-V、V-DPO 和论文中的方法 TPO。
为了解决上述问题,TPO 具有如下特点:
图 2 可视化了 TPO 训练前后的 ground truth 及模型回复的视觉锚定奖励。可以看到,我们的方法有效地找到了视觉锚定的 tokens,并能够在训练之后增强模型对视觉信息的关联。
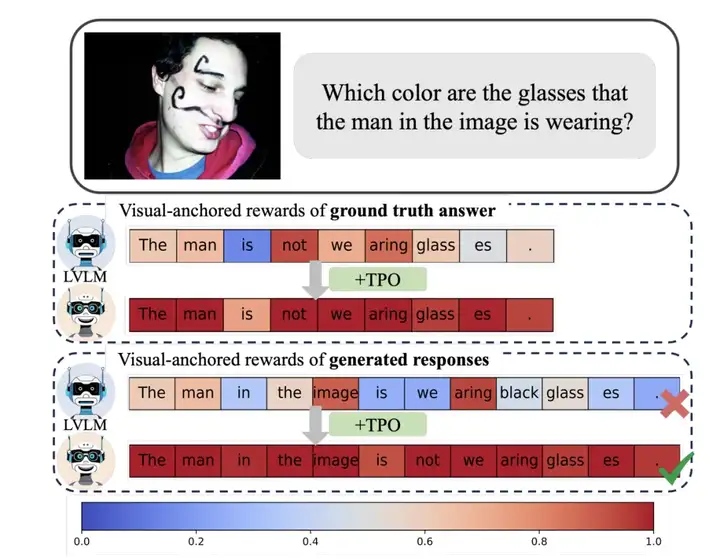
图 2:一个视觉 QA 对的例子以及 TPO 对视觉信息锚定程度的打分可视化,上面的框是 GT_answer,下面的框是 LVLM 在使用 TPO 训练前后的回复。在每一个框中,上方是 TPO 训练前的打分,下方则是训练后的打分。
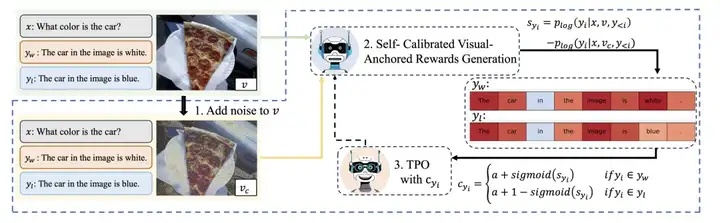
图 3:TPO 的整体流程
(以下步骤中的数据包含输入 x,图像 v 和正负样本 y_w,y_l。当不强调正样本或负样本时,统称为 y.)
1. 自校准的视觉锚定奖励生成
TPO 通过捕捉在图像是否加噪时每个生成 token 的生成概率差的变化来衡量其视觉锚定程度,首先对输入图像进行加噪处理:
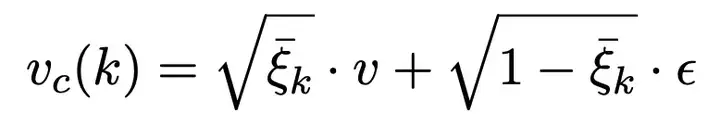

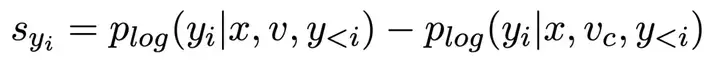
进一步地,在此引入自我校准的过程获得最终的监督信号。这一步的目的是为正负样本分配相应奖励的同时,能够对二者中所有视觉锚定 token 进行视觉信息关联度的优化。最终的视觉监督信号被定义为:
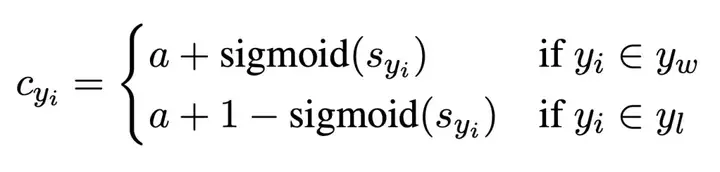


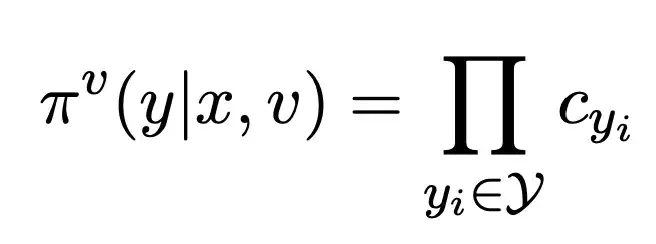
则反馈函数为:
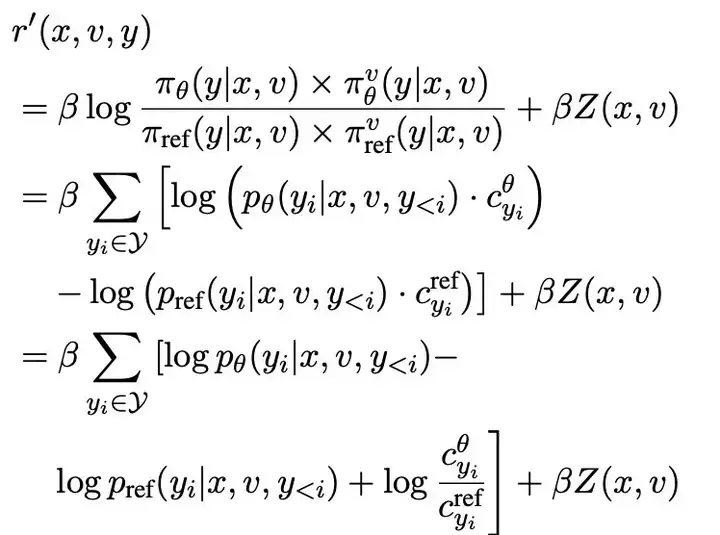

最终得到 TPO 的优化目标为:
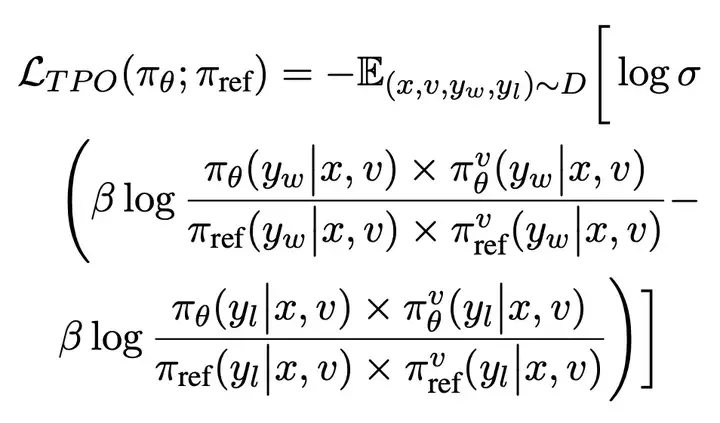
实验设置
主实验结果
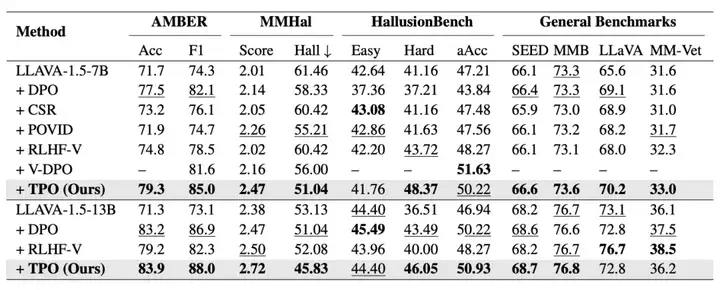
图 4:各种强化学习方法在 LLaVA-1.5 上测试的在幻觉和通用 benchmarks 上的实验效果,其中 POVID 和 CSR 方法的结果是根据开源的模型权重测试的效果,V-DPO 的结果来自该文章的结果。
消融实验
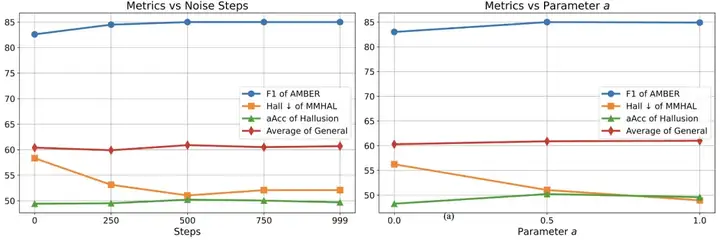
图 5: 各指标随着加入噪声步数和参数 a 的变化趋势
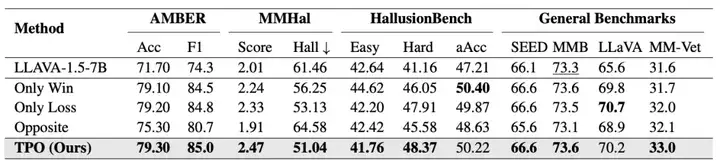
图 6: 消融实验
分析实验
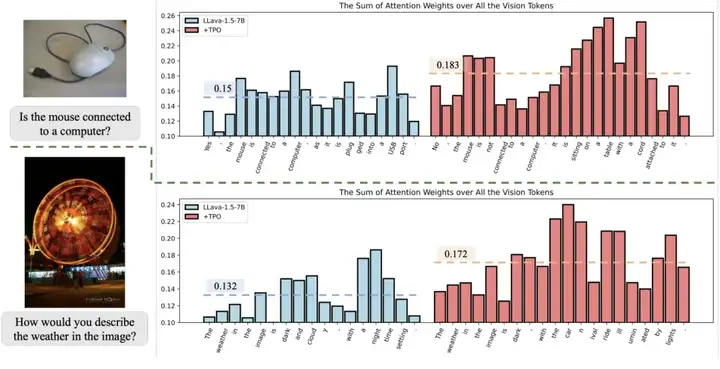
图 7:attention weights 对比图,左边蓝色的是训练前模型回答错误的回复,右边红色的是训练后模型回答正确的回复。
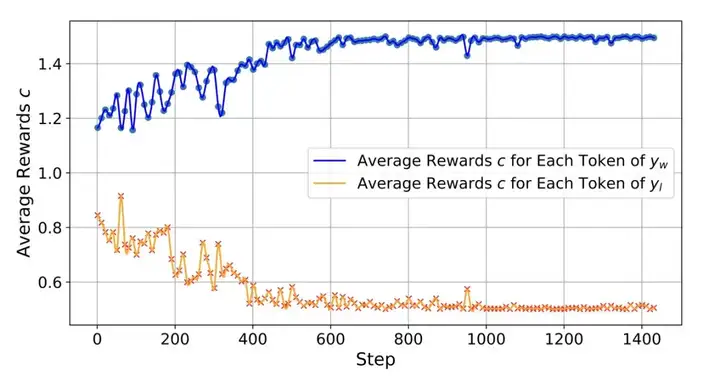
图 8: 正负样本的 c 随训练 step 得变化过程
淘天集团算法技术 - 未来生活实验室团队将持续深耕强化学习领域,为解决多模态幻觉问题贡献力量。
文章来自微信公众号 ” 机器之心 “,作者 “顾纪豪,王瑛瑶 ”




