
独家|混元多模态理解负责人胡瀚离职创业,原团队或将聚焦世界模型
独家|混元多模态理解负责人胡瀚离职创业,原团队或将聚焦世界模型独家获悉,近期,腾讯混元多模态理解负责人胡瀚提出了离职。此前,他曾担任微软亚洲研究院视觉计算组首席研究员。2025年初加入腾讯后,负责视觉大模型的研究。在后续的调整中,他加入大语言模型部旗下的“Frontier”前沿技术研究组,负责多模态理解的相关研究,汇报给姚顺雨。
来自主题: AI资讯
9389 点击 2026-07-23 16:56
 搜索
搜索
独家获悉,近期,腾讯混元多模态理解负责人胡瀚提出了离职。此前,他曾担任微软亚洲研究院视觉计算组首席研究员。2025年初加入腾讯后,负责视觉大模型的研究。在后续的调整中,他加入大语言模型部旗下的“Frontier”前沿技术研究组,负责多模态理解的相关研究,汇报给姚顺雨。
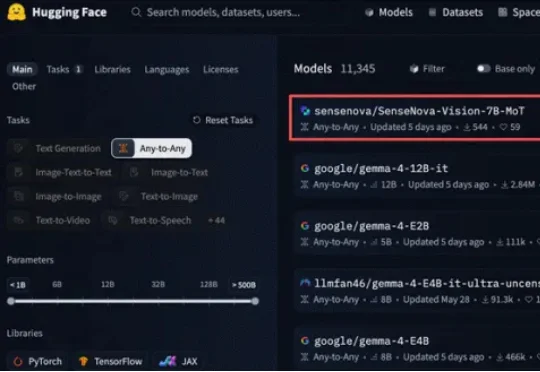
近日,商汤科技发布并全面开源日日新SenseNova-Vision理解生成统一视觉大模型,试图宣告视觉AI“缝合怪”时代的终结。截至当前,该模型综合得分登顶Hugging Face Any-to-Any Leaderboard,位列该全模态任意输入输出开源模型榜单全球第一。
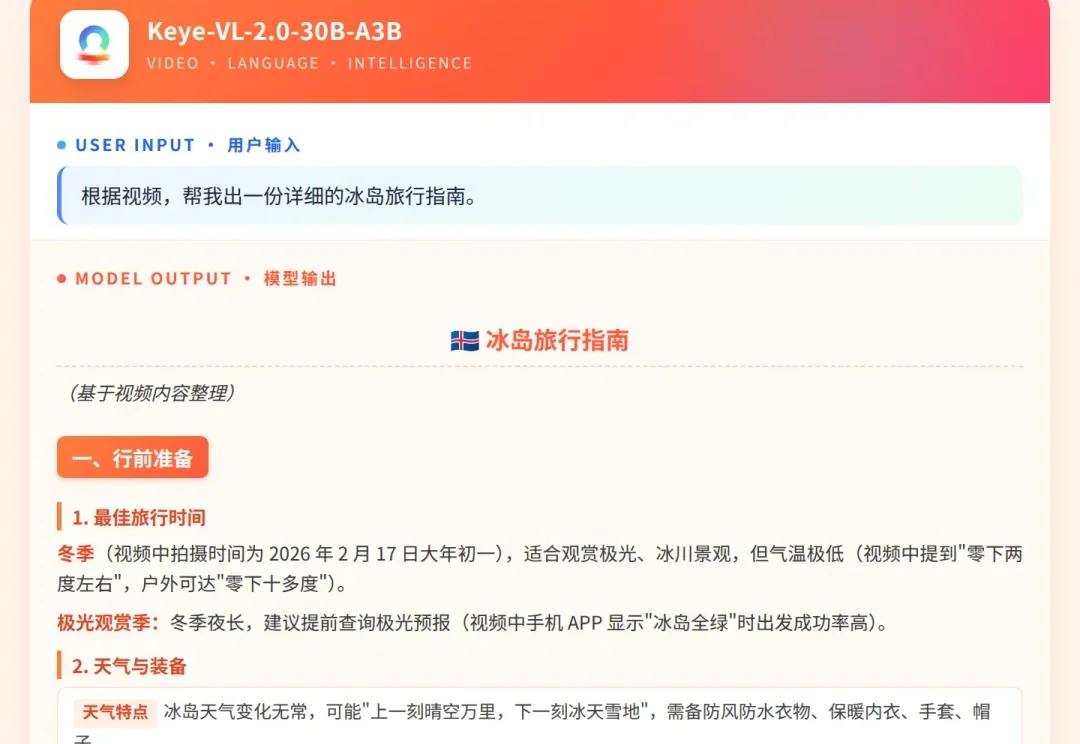
当你把一段长达9分钟、在“晴空万里”与“冰天雪地”间剧烈切换的冰岛旅行Vlog输入给大模型,并要求它做一份旅行攻略时,常规的视觉大模型通常只能给出一份基于字幕和画面标签拼凑的“流水账”。

即将结束博士生涯的童晟邦,正站在另一个起点上。
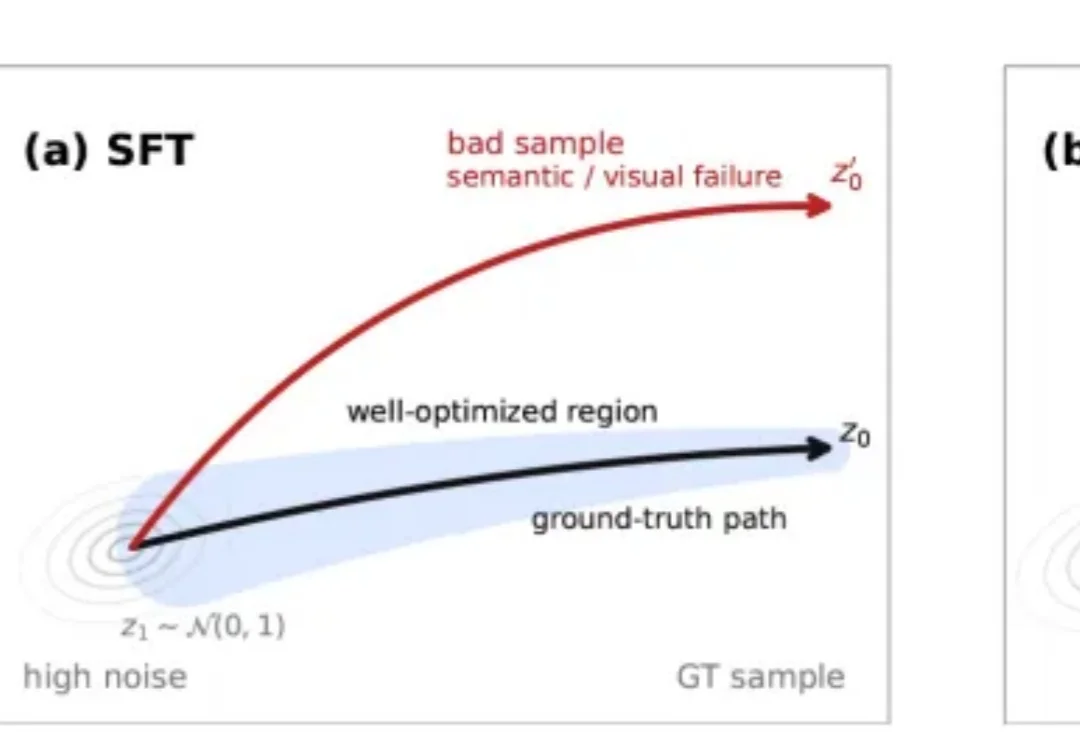
近日,腾讯混元团队提出HY-SOAR (Self-Correction for Optimal Alignment and Refinement),一种面向扩散模型和流匹配模型的数据驱动后训练方法。
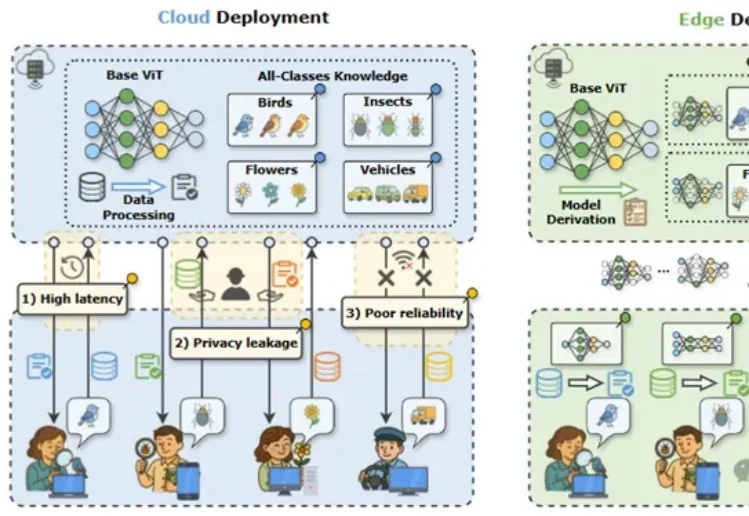
近年来,视觉大模型在自动驾驶、智慧医疗等场景中得到广泛应用,但在真实业务环境中,“大而全”的通用模型往往并不是最优选择。
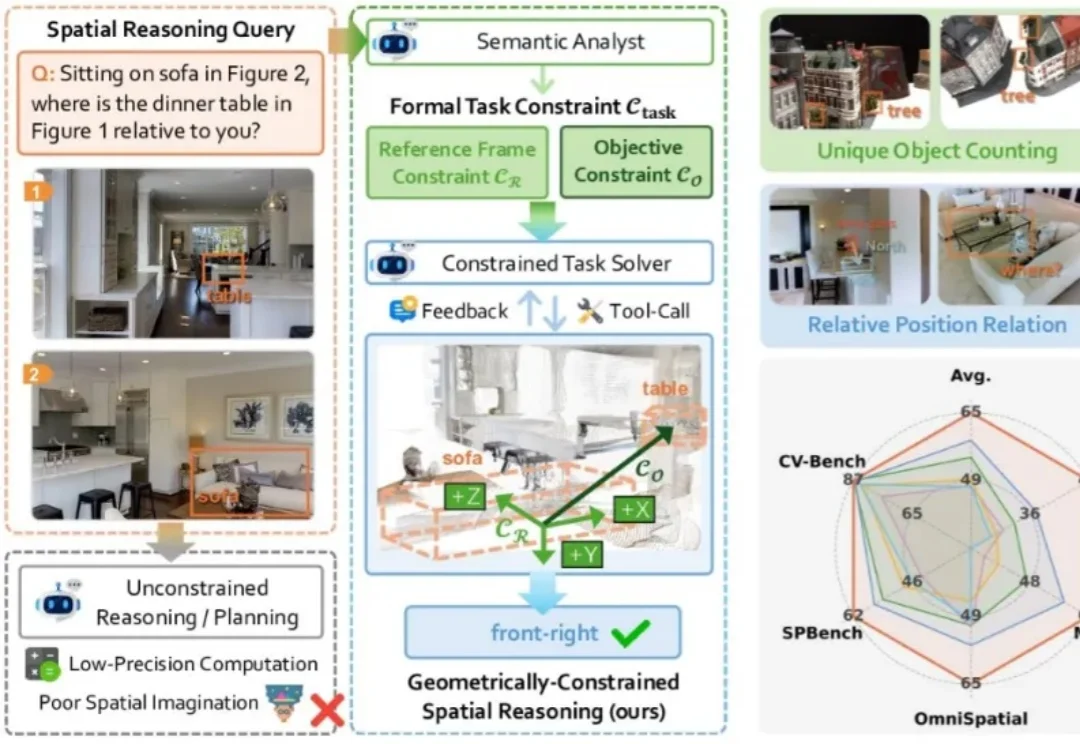
现有的视觉大模型普遍存在「语义-几何鸿沟」(Semantic-to-Geometric Gap),不仅分不清东南西北,更难以处理精确的空间量化任务。例如问「你坐在沙发上时,餐桌在你的哪一侧?」,VLM 常常答错。

外卖大战压力之下,美团正在打一场AI基建的硬仗。 文|邓咏仪 编辑|苏建勋 杨轩 《智能涌现》从多个信息源独家获悉,前闪极AI合伙人、前字节视觉大模型AI平台负责人潘欣,近期已经加入美团。 潘欣曾任谷
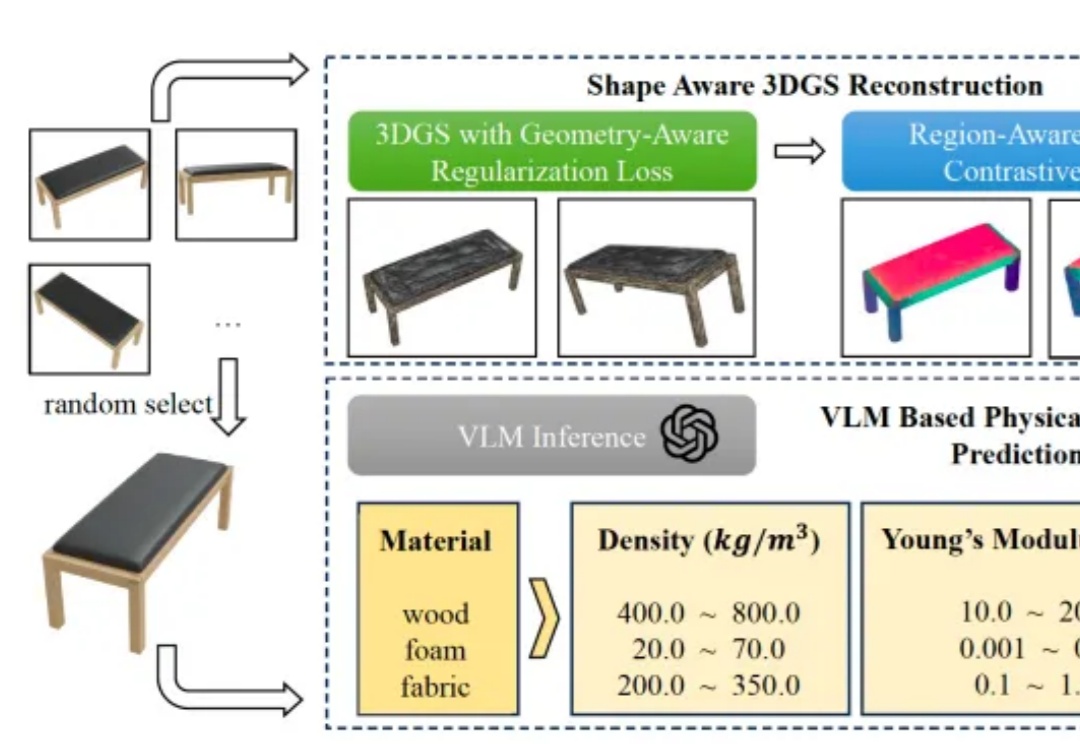
理解物体的物理属性,对机器人执行操作十分重要,但是应该如何实现呢?
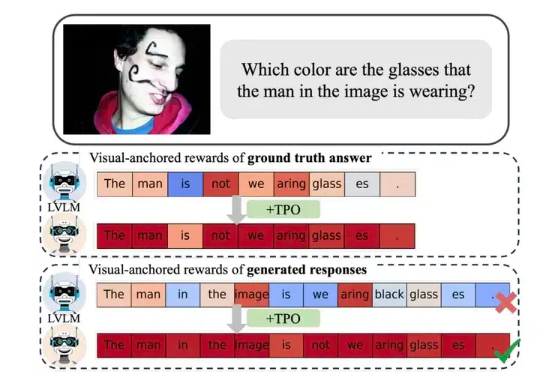
近年来,视觉大模型(Large Vision Language Models, LVLMs)领域经历了迅猛的发展,这些模型在图像理解、视觉对话以及其他跨模态任务中展现出了卓越的能力。然而,随着 LVLMs 复杂性和能力的增长,「幻觉现象」的挑战也日益凸显。