
沈向洋,发了一个可以识别万物的大模型
沈向洋,发了一个可以识别万物的大模型视觉模型仍是IDEA的研究重点——IDEA正式发布的最新通用视觉大模型DINO-X,可以拥有真正的物体级别理解能力。
来自主题: AI资讯
9202 点击 2024-11-23 23:16
 搜索
搜索
视觉模型仍是IDEA的研究重点——IDEA正式发布的最新通用视觉大模型DINO-X,可以拥有真正的物体级别理解能力。

36氪获悉,近日, 深圳个元科技有限公司(以下简称“个元科技”)完成4600万美元B轮融资,本轮融资由 UP Partners 领投,融得资金将主要用于扩张市场、加大技术研发。


还能玩纸牌游戏。

不用打标签,也能解决视觉大模型的偏好对齐问题了。
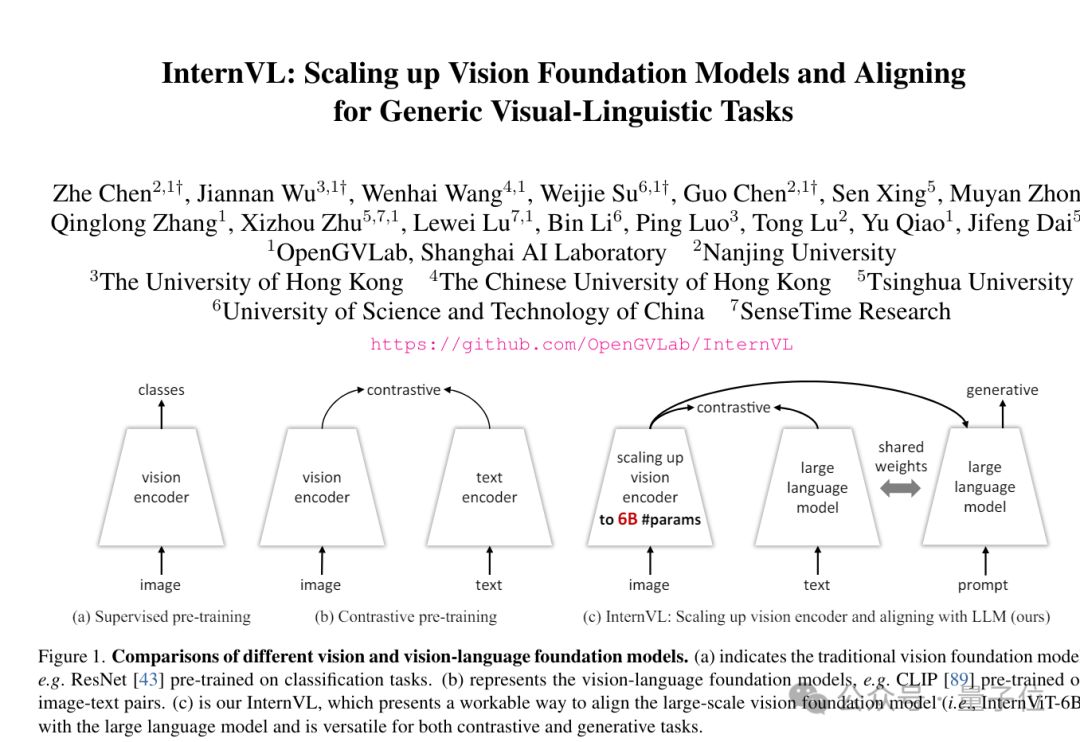
CVPR正在进行中,中国科研力量再次成为场内外焦点之一。
与 DeiT 等使用 ViT 和 Vision-Mamba (Vim) 方法的模型相比,ViL 的性能更胜一筹。

Transformer 在大模型领域的地位可谓是难以撼动。不过,这个AI 大模型的主流架构在模型规模的扩展和需要处理的序列变长后,局限性也愈发凸显了。Mamba的出现,正在强力改变着这一切。它优秀的性能立刻引爆了AI圈。

12月5-6日,主题为“未来AI设计”的美图创造力大会在厦门举行。美图公司发布自研AI视觉大模型MiracleVision(奇想智能)4.0版本,主打AI设计与AI视频。

UC伯克利的CV三巨头推出首个无自然语言的纯视觉大模型,第一次证明纯CV模型也是可扩展的。更令人震惊的是,LVM竟然也能做对图形推理题,AGI火花再次出现了?计算机视觉的GPT时刻,来了!