# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
与 DeiT 等使用 ViT 和 Vision-Mamba (Vim) 方法的模型相比,ViL 的性能更胜一筹。
AI 领域的研究者应该还记得,在 Transformer 诞生后的三年,谷歌将这一自然语言处理届的重要研究扩展到了视觉领域,也就是 Vision Transformer。后来,ViT 被广泛用作计算机视觉中的通用骨干。
这种跨界,对于前不久发布的 xLSTM 来说同样可以实现。最近,享誉数十年的 LSTM 被扩展到一个可扩展且性能良好的架构 ——xLSTM,通过指数门控和可并行化的矩阵内存结构克服了长期存在的 LSTM 限制。现在,这一成果已经扩展到视觉领域。
xLSTM和 Vision-LSTM 两项研究均由 LSTM 原作者带队,也就是 LSTM 的提出者和奠基者 Sepp Hochreiter。
在最近的这篇论文中,Sepp Hochreiter 等人推出了 Vision-LSTM(ViL)。ViL 包含一堆 xLSTM 块,其中奇数块从上到下、偶数块则从下到上处理补丁 token 序列。

正如 xLSTM 诞生之时,作者希望新架构能够撼动 Transformer 在语言模型领域的江山。这一次,闯入视觉领域的 Vision-LSTM 也被寄予厚望。
研究者在论文中表示:「我们的新架构优于基于 SSM 的视觉架构,也优于 ImageNet-1K 分类中的优化 ViT 模型。值得注意的是,在公平的比较中,ViL 的表现优于经过多年超参数调整和 Transformer 改进的 ViT 训练 pipeline。」
对于需要高分辨率图像以获得最佳性能的任务,如语义分割或医学成像, ViL 极具应用潜力。在这些情况下,Transformer 因自注意力的二次复杂性而导致计算成本较高,而 ViL 的线性复杂性不存在这种问题。研究者还表示,改进预训练方案(如通过自监督学习)、探索更好的超参数设置或从 Transformer 中迁移技术(如 LayerScale )都是 ViL 的可探索方向。
语言建模架构 —— 如 Transformer 或最近的状态空间模型 Mamba,通常被应用到计算机视觉领域,以利用它们强大的建模能力。
然而,在自然语言处理中,通过离散词汇表(Discrete vocabulary),输入的句子通常被编码成代表词或常见子词的 token。
为了将图像编码成一组 token,Vision Transformer(ViT)提出将输入图像分组成非重叠的补丁(例如 16x16 像素),将它们线性投影成所谓的补丁 token 序列,并向这些 token 添加位置信息。
然后,这个序列就可以被语言建模架构处理了。
扩展长短期记忆(xLSTM)最近被引入作为一种新的语言建模架构,可以说是 LSTM 在 LLM 时代的复兴,与 Transformer 和状态空间模型(SSMs)等相媲美。
现有的 Transformer 或状态空间模型的视觉版本,例如 ViT 或 Vision Mamba,已经在各种计算机视觉任务中取得了巨大成果。
使用 xLSTM 作为核心组建的 ViL 使用简单的交替设计,从而可以有效地处理非序列输入(如图像),而无需引入额外的计算。
类似于 SSMs 的视觉适应,ViL 展示了关于序列长度的线性计算和内存复杂度,这使得它在高分辨率图像的任务中展现极佳的作用,如医学成像、分割或物理模拟。
相比之下,ViT 的计算复杂度由于自注意力机制而呈二次方增长,使得它们在应用于高分辨率任务时成本高昂。
Vision-LSTM(ViL)是一个用于计算机视觉任务的通用骨干,它从 xLSTM 块残差构建,如图 1 所示。
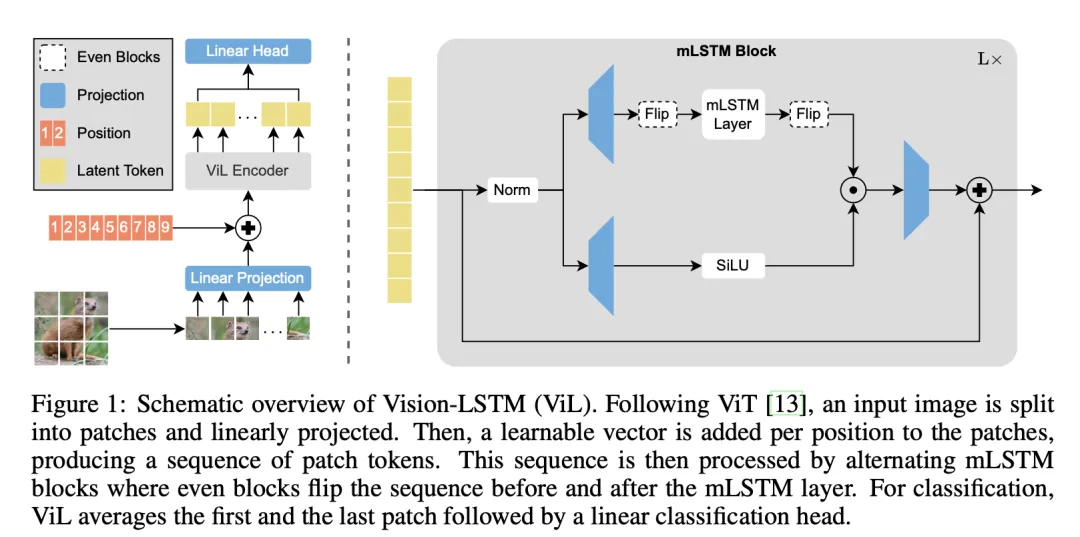
与 ViT 类似,ViL 首先通过共享线性投影将图像分割成非重叠的补丁,然后向每个补丁 token 添加可学习的定位嵌入。ViL 的核心是交替的 mLSTM 块,它们是可完全并行化的,并配备了矩阵内存和协方差更新规则。
奇数 mLSTM 块从左上到右下处理补丁 token,而偶数块则从右下到左上。
研究团队在 ImageNet-1K 上进行了实验:它包含 130 万张训练图像和 5 万张验证图像,每张图像属于 1000 个类别之一。
对比实验集中在使用序列建模骨干的模型上,而该模型在大致相当的参数数量上是可比较的。
他们在 224x224 分辨率上训练 ViL 模型,使用余弦衰减调度,1e-3 的学习率训练了 800 个周期(tiny, tiny+)或 400 个周期(small, small+, base),具体见下方表 5.

为了对 Vision Mamba(Vim)进行公平比较,研究人员向模型内添加了额外的块以匹配 tiny 和小型变体(分别表示为 ViL-T + 和 ViL-S+)的参数数量。
需要注意的是,由于 ViL 以交替的方式遍历序列,而 Vim 则在每个块中遍历序列两次,因此 ViL 所需的计算量远少于 Vim。
尽管 Vim 使用了优化的 CUDA 内核(而 mLSTM 目前还没有这样的内核),但这仍然成立,并且会进一步加速 ViL 的速度。
如表 4 所示的运行时间对比,在其中两项的比较重,ViL 比 Vim 快了 69%。

虽然 ViL 首次出场,但仍是展现了极佳的潜力。
由于 ViTs 在视觉社区中已经得到了广泛的认可,它们在过去几年经历了多次优化周期。
因为这项工作是首次将 xLSTM 应用于计算机视觉,研究人员并不期望在所有情况下都超过 ViTs 多年的超参数调整。
即便如此,表 1 中的结果显示,ViL 在小规模上相比于经过大量优化的 ViT 协议(DeiT, DeiT-II, DeiT-III)仍是显示出较良好的结果,其中只有训练时间是 ViL-S 两倍的 DeiT-III-S 表现略好一点。
在「base」规模上,ViL 超越了最初的 ViT 模型,并取得了与 DeiT 相当的结果。
需要注意的是:由于在这个规模上训练模型的成本很高,ViL-B 的超参数远非最佳。作为参考,训练 ViL-B 大约需要 600 个 A100 GPU 小时或在 32 个 A100 GPU 上的 19 个小时。
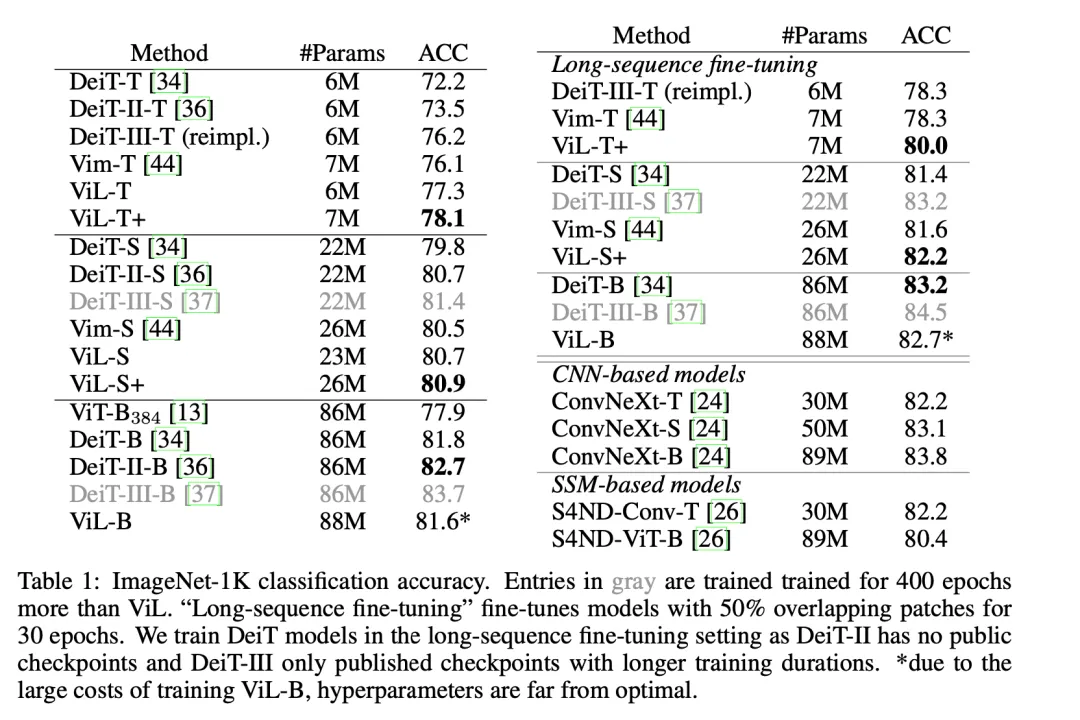
通过在「长序列微调」设置中微调模型,性能可以进一步提高,该设置通过使用连续补丁 token 之间 50% 的重叠,将序列长度增加到 729,对模型进行 30 个周期的微调。
尽管没有利用卷积固有的归纳偏置,ViL 还是展现出了与基于 CNN 的模型(如 ConvNeXt)相当的性能。
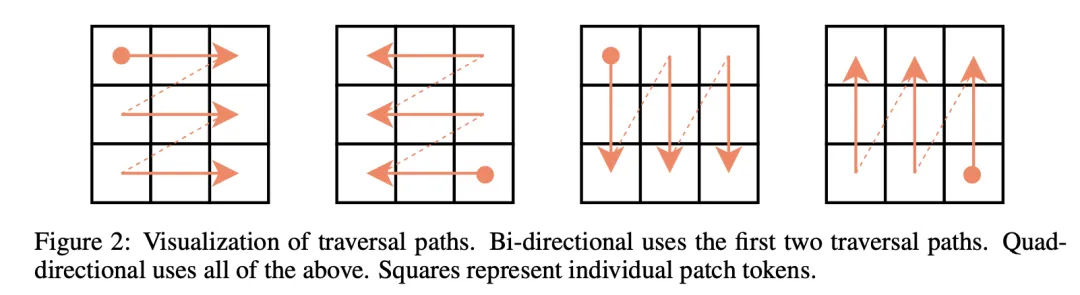
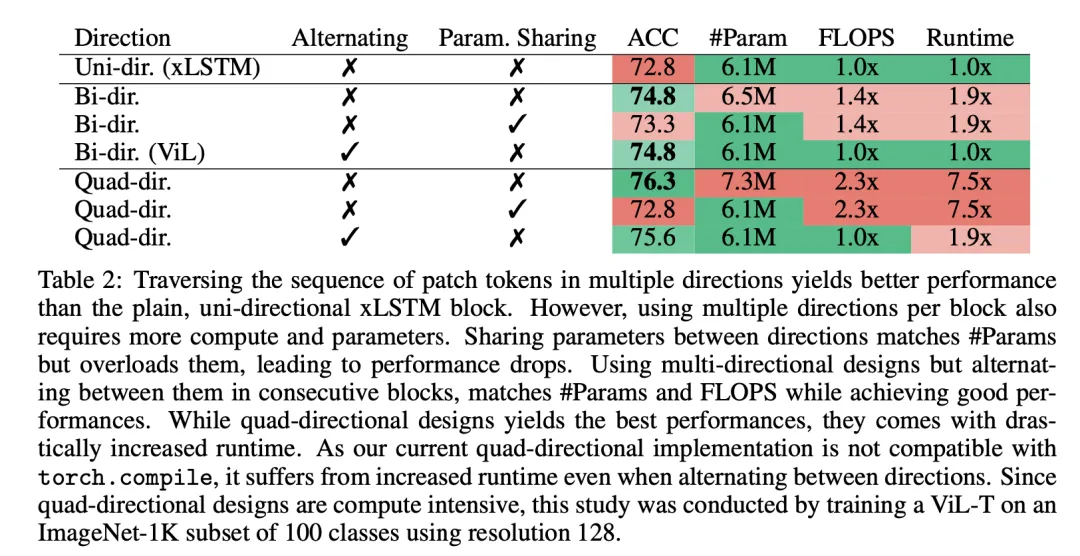
该团队研究了设计 ViL 块的不同方式,如图 2 所示。
该团队还探索了四向设计,这指的是按行(两个方向)和按列(两个方向)遍历序列。双向仅按行遍历序列(两个方向)。
图 2 可视化了不同的遍历路径。
由于双向和四向块的成本增加,这项研究是在设置大幅减少的条件中进行的。
研究人员在 128x128 分辨率下,对包含仅来自 100 个类别的样本的 ImageNet-1K 的一个子集进行 400 个周期的训练。这是特别必要的,因为四向实现方法与 torch.compile(来自 PyTorch 的一个通用速度优化方法)不兼容,这会导致更长的运行时间,如表 2 最后一列所示。
由于此技术限制,该团队最终了选择交替双向块作为核心设计。
为了使用 ViT 进行分类,需要将 token 序列汇集成一个 token,然后将其作为分类头的输入。
最常见的汇集方法是:(i) 在序列的开头添加一个可学习的 [CLS] token,或 (ii) 平均所有补丁 token,生成一个 [AVG] token。使用 [CLS] 还是 [AVG] token 通常是一个超参数,两种变体的性能相当。相反,自回归模型通常需要专门的分类设计。例如,Vim 要求 [CLS] token 位于序列的中间,如果采用其他分类设计,如 [AVG] token 或在序列的开始和结束处使用两个 [CLS] token,则会造成严重的性能损失。
基于 ViL 的自回归特性,研究者在表 3 中探讨了不同的分类设计。

[AVG] 是所有补丁 token 的平均值,「Middle Patch 」使用中间的补丁 token,「Middle [CLS]」使用序列中间的一个 [CLS] token,「Bilateral [AVG]」使用第一个和最后一个补丁 token 的平均值。
可以发现的是, ViL 分类设计相对稳健,所有性能都在 0.6% 以内。之所以选择 「Bilateral [AVG]」而不是 「Middle [CLS]」,因为 ImageNet-1K 有中心偏差,即物体通常位于图片的中间。通过使用 「Bilateral [AVG]」,研究者尽量避免了利用这种偏差,从而使模型更具通用性。
为了与之前使用单个 token 作为分类头输入的架构保持可比性,研究者对第一个和最后一个 token 进行了平均处理。为了达到最佳性能,建议将两个标记合并(「Bilateral Concat」),而不是取平均值。
这类似于 DINOv2 等自监督 ViT 的常见做法,这些是通过分别附加在 [CLS] 和 [AVG] token 的两个目标来进行训练的,因此可以从连接 [CLS] 和 [AVG] token 的表征中获益。视觉 SSM 模型也探索了这一方向,即在序列中分散多个 [CLS] token,然后将其作为分类器的输入。此外,类似的方向也可以提高 ViL 的性能。
更多研究细节,请参考原论文。
文章来自于微信公众号 “机器之心”,作者 “鸭梨、蛋酱”



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
