
奥特曼宣判Transformer死刑! AGI两年内降临,下一代架构已在路上
奥特曼宣判Transformer死刑! AGI两年内降临,下一代架构已在路上终结Transformer的架构即将诞生!奥特曼最新访谈豪言,下一代AI架构彻底颠覆Transformer,LSTM的命运或将再次上演。
来自主题: AI资讯
8736 点击 2026-03-17 14:35
 搜索
搜索
终结Transformer的架构即将诞生!奥特曼最新访谈豪言,下一代AI架构彻底颠覆Transformer,LSTM的命运或将再次上演。
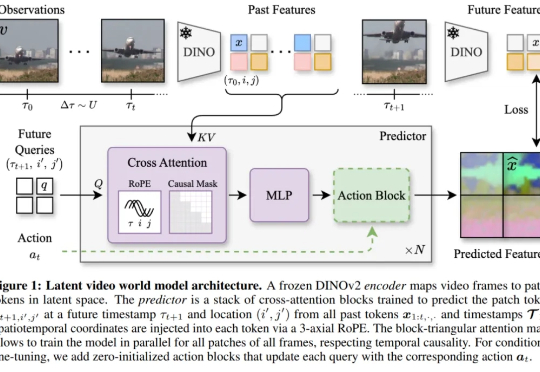
2018 年,LSTM 之父 Jürgen Schmidhuber 在论文中( Recurrent world models facilitate policy evolution )推广了世界模型(world model)的概念,这是一种神经网络,它能够根据智能体过去的观察与动作,预测环境的未来状态。
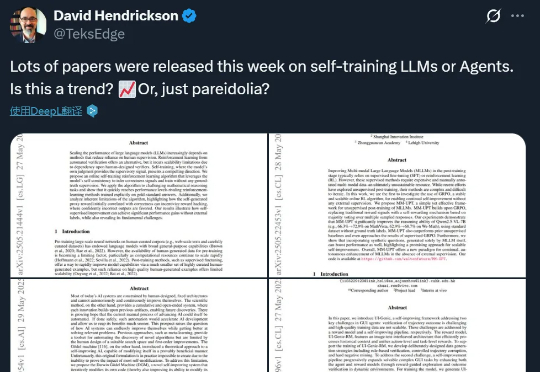
在过去的一周,这一方向的进展尤其丰富。有人发现,几篇关于「让 LLM(或智能体)学会自我训练」的论文在 arXiv 上集中出现,其中甚至包括受「哥德尔机」构想启发而提出的「达尔文哥德尔机」。或许,AI 模型的自我进化能力正在加速提升。
近年来,大型语言模型(LLM)通过大量计算资源在推理阶段取得了解决复杂问题的突破。推理速度已成为 LLM 架构的关键属性,市场对高效快速的 LLM 需求不断增长。
Transformer模型自2017年问世以来,已成为AI领域的核心技术,尤其在自然语言处理中占据主导地位。然而,关于其核心机制“注意力”的起源,学界存在争议,一些学者如Jürgen Schmidhuber主张自己更早提出了相关概念。

本届诺奖的AI含量,实在是过高了!今晚的文学奖会颁给ChatGPT或者奥特曼吗?已经有一大波网友下注了。另一边,Hinton已经炮轰起了奥特曼,力挺Ilya当初赶走他;而LSTM之父则怒斥Hinton不配诺奖。
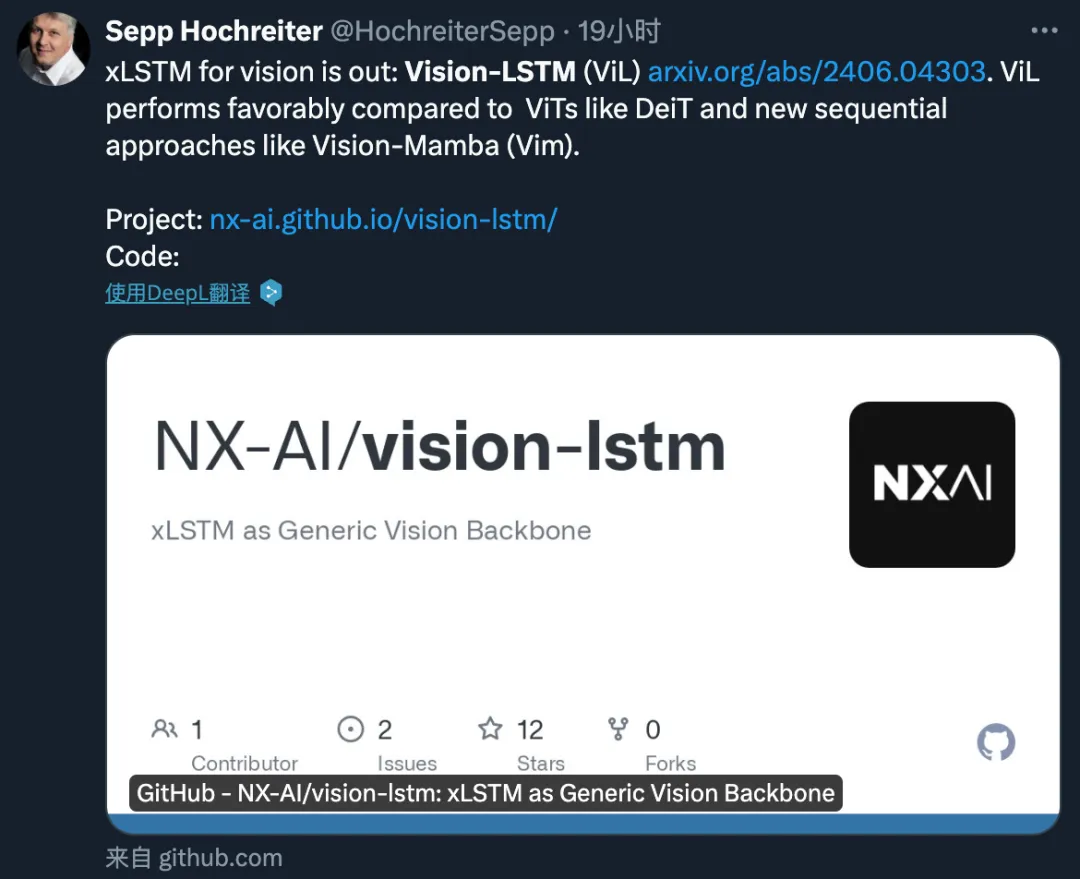
与 DeiT 等使用 ViT 和 Vision-Mamba (Vim) 方法的模型相比,ViL 的性能更胜一筹。
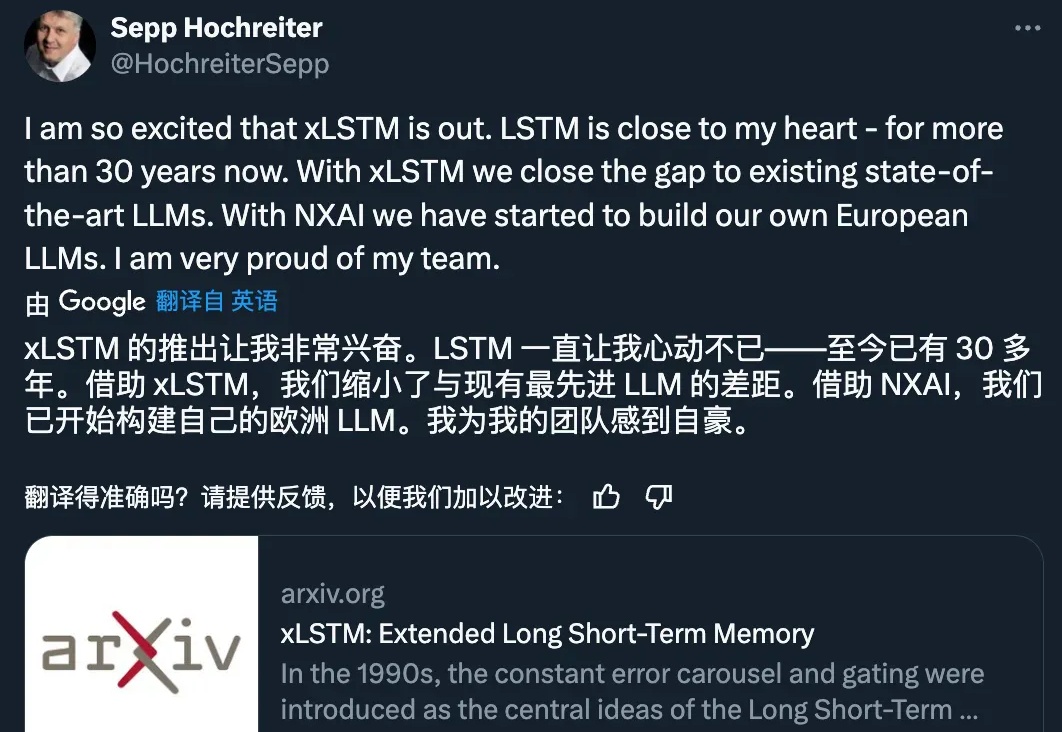
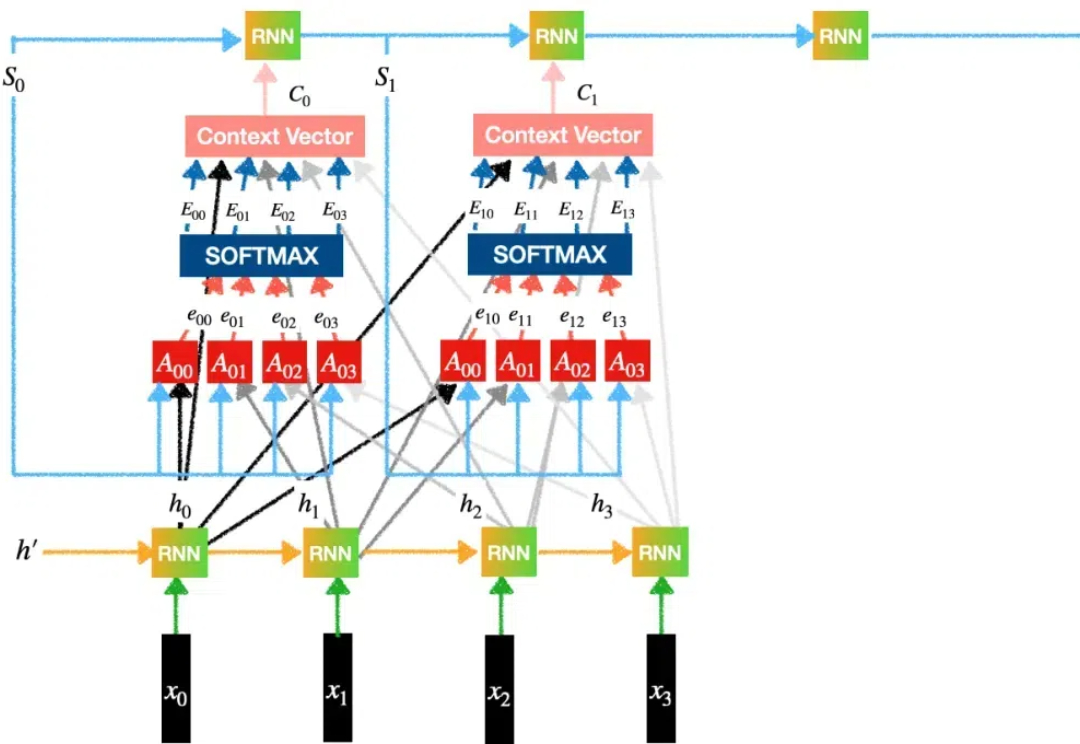
20 世纪 90 年代,长短时记忆(LSTM)方法引入了恒定误差选择轮盘和门控的核心思想。三十多年来,LSTM 经受住了时间的考验,并为众多深度学习的成功案例做出了贡献。然而,以可并行自注意力为核心 Transformer 横空出世之后,LSTM 自身所存在的局限性使其风光不再。