# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
不用打标签,也能解决视觉大模型的偏好对齐问题了。
南大与旷视研究院的研究人员,推出了适用于VLM的无监督范式。
对比偏好对齐前后,可以发现模型的输出发生了显著的变化。

目前的视觉大模型已经比较成熟,但作者发现它们在用户体感方面仍然有所欠缺。
于是团队经过研究,通过构造偏好样本对的方式解决了视觉语言模型的偏好对齐问题,并提出了Self-Supervised Visual Preference Alignment(SeVa)范式。
该范式基于LLaVa-1.5-7B/13B完成,整个过程无需GPT-4或者是人类参与打标签,目前项目已经开源!

目前视觉大模型基本上在流程上已经非常成熟——预训练+指导监督微调(SFT)+对齐(可选)。
去年下半年开始,工业界和学术界主要聚焦在多模态大模型的数据(数据构造,配比,打标签)和模型结构(Connector,打开模型权重等)的设计上,目标是提升VLM的理解能力(传统QA+多模态benchmark)。
但是,研究团队发现部分开源大模型,虽然在跑分时有不错的性能,但在用户体感方面会比较欠缺——不遵循指令,产生幻觉回答,违背3H准则(helpfulness, harmless, honest)等问题纷纷出现。
研究团队认为,多模态对齐的一大难点,在于偏好数据的构造。
主要的原因是,纯NLP领域的偏好数据非常昂贵且稀缺(一般需要GPT-4或者人类的参与),Vision-Language领域的偏好数据还没有形成一个成熟的pipeline(数据构造方式,数据质量,数据的效果都还没完全得到验证)。
因此,本文首次提出一套自动化构造偏好数据的pipeline用于Alignment的训练。作者通过严格的实验,从多个角度展示了该pipeline对多模理解和用户友好性的提升。
研究当中,作者发现VLM对于图像层面的扰动非常敏感,也就是说,轻微的图像增广就会使得VLM对同一个Question产生错误且不同的回答。
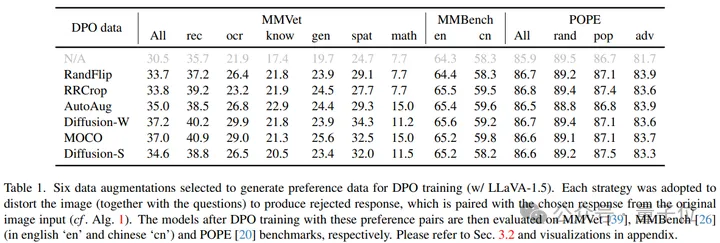
具体来说,作者将多种图像层面的扰动分别作用于LLaVA-1.5的测试阶段,并在3个常规的多模态benchmark上运行,得到的结果如下:
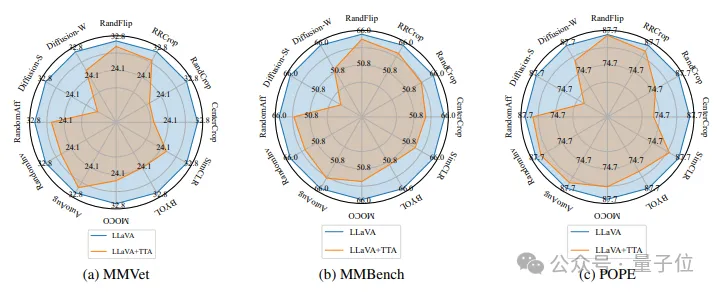
因此SeVa将原始图像产生的回答作为正样本,将增广后的图像产生的回答作为负样本,用于构造DPO的数据集并训练。

如果以流程图的形式来展示,SeVa的工作流如下:
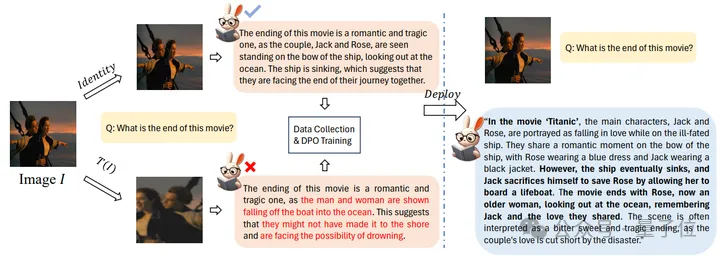
具体来说,作者使用LLaVA665k 数据集中的TextVQA和OCRVQA来构造DPO数据,基于7B和13B的LLaVA-v1.5模型,使用其pretrained+SFT作为DPO的初始化权重,结合LoRA训练语言模型,r默认在512/1024。
实验结果表明,仅仅使用8k构造的无监督的数据能够显著提高VLM的指令遵循能力、降低幻觉,并且在多模态等benchmark上提升明显。
而且构造过程轻而易举、成本低廉,不需要任何人类或者是GPT-4的标注。
另外,作者还系统阐述了在DPO训练中用到的偏好分布与对比损失之间的关系。他们的形式在一定程度上是一致的,但是核心区别在于负样本的定义。
和对比学习统一之后的好处是,可以轻易的通过对比学习的思路,在DPO中添加更多由SeVa构建的负样本对,从而推导出一个更加通用的DPO形式。

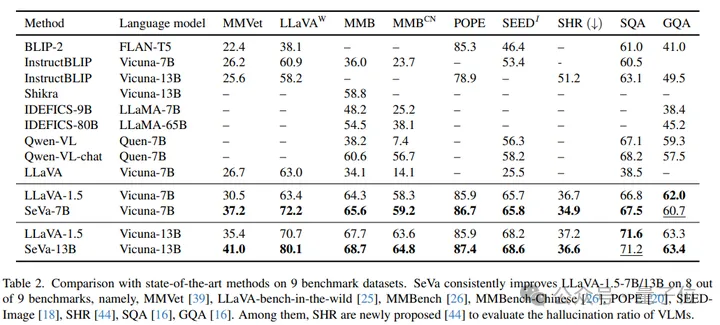
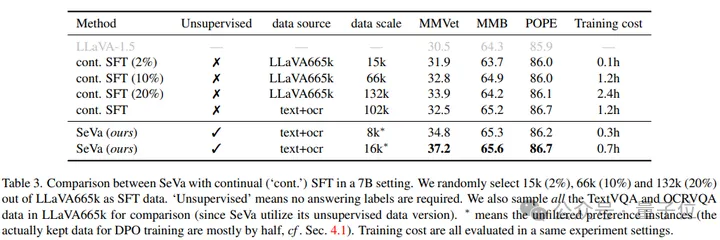
在9个benchmark上,SeVa几乎都能够做到稳定的提升,特别是在GPT-4评估的MMVet,和LLaVA-bench上提升显著,在用于评估幻觉的指标POPE、SHR上也有稳定的性能提升。
进一步实验表明,SeVa DPO的范式比SFT在微调VLM上具有更大的优势,例如训练时间更短、数据量更少、pipeline无需监督等,另外再性能上也有所提升。
换句话说,该实验也证明了Preference Alignment在某些情况会远远超过SFT的效率。
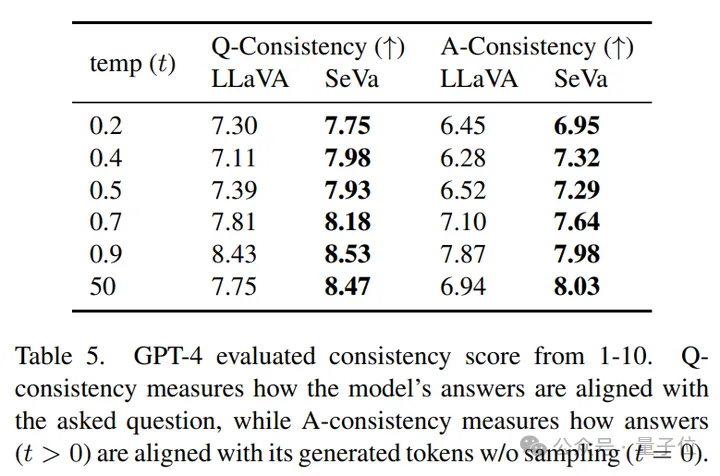
而且,经过DPO之后,SeVa的输出会更加的与模型得到的Question更加的接近。
同时,SeVa每次回答的一致性也更高,对于不同temperature的扰动拥有更强的鲁棒性。
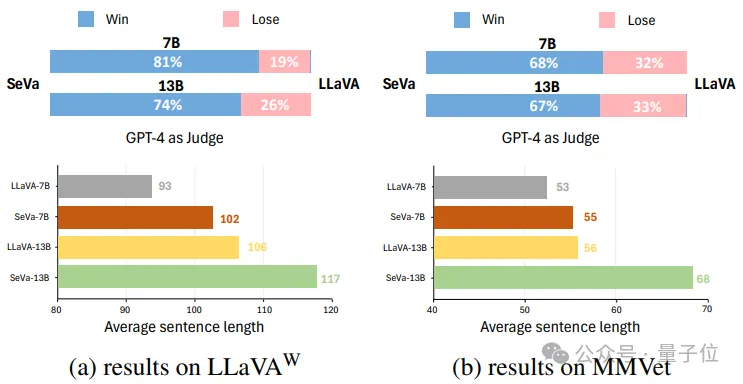
通过可视化,作者还发现,SeVa的输出结果比原始LLaVA(未经过DPO训练)更加的优质(在win-lose的比例上明显占优)。
同时,经过DPO之后,SeVA产生了普遍比LLaVA更长更详细的回答。以上两个方面的可视化也解释了为什么SeVa能够更加的与人类的偏好对齐。
另外,本文还进行了诸多关于SeVa的细化和分析,有很多有意思的结论:
论文地址:
https://arxiv.org/abs/2404.10501
GitHub:
https://github.com/Kevinz-code/SeVa
文章来自于微信公众号“量子位”,作者 “旷视研究院”




【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
