# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
视觉自回归模型的Scaling,往往不像在语言模型里那样有效。
谷歌&MIT何恺明团队联手,有望打破这一局面,为自回归文生图模型的扩展指出一个方向:

受到这些发现启发,团队训练了Fluid,一个基于连续标记的随机顺序自回归模型。
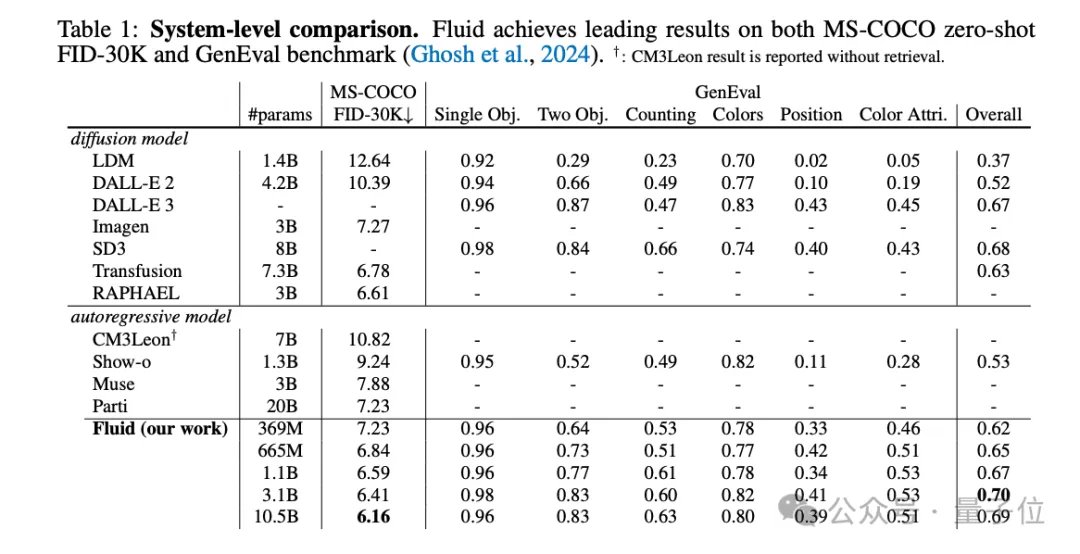
扩展至百亿参数的Fluid在MS-COCO 30K上zero-shot条件下实现了6.16的FID分数,并在GenEval基准测试中获得了0.69的整体得分。
团队希望这些发现和结果能够鼓励未来进一步弥合视觉和语言模型之间的规模差距。
回顾过去,两个关键设计因素限制了自回归图像生成模型的性能表现:
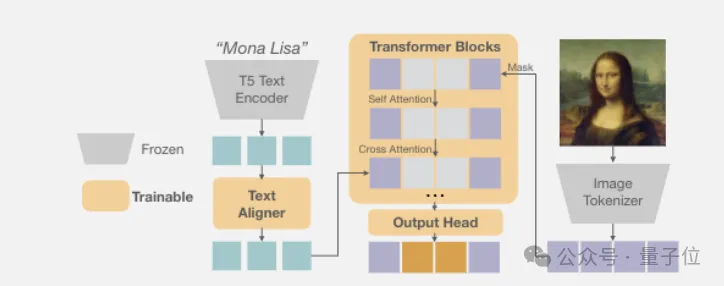
Fluid继承了团队在今年6月份研究《Autoregressive Image Generation without Vector Quantization》的思路,抛弃离散token,改用连续token。

它借鉴了扩散模型,用一个小型去噪网络近似每个token的连续分布。
具体而言,模型为每个位置的token生成一个向量z作为条件,输入一个小型去噪网络。这个去噪网络定义了token x在给定z时的条件分布p(x|z)。训练时,该网络与自回归模型联合优化;推理时,从p(x|z)中采样即可得到token。整个过程无需离散化,避免了量化损失。

再来看看生成token的顺序。按固定的光栅顺序逐个生成token,推理时虽然可以用kv缓存加速,但因果关系的限制也影响了生成质量。
Fluid另辟蹊径,随机选择要生成的token,并用类似BERT双向注意力的机制捕捉全局信息。
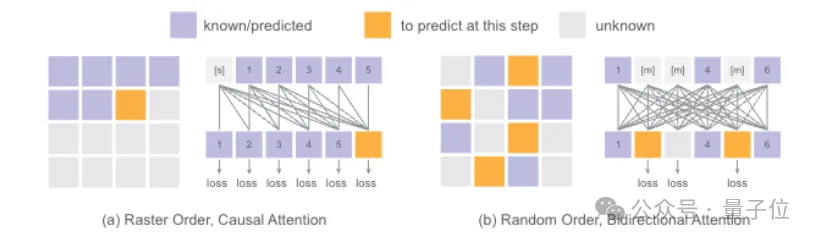
在推理时采用完全随机顺序,训练和推理过程的序列分布更一致;同时还能对每个token进行类似GPT的temperature采样,进一步提升了生成多样性。
得益于扩散损失和MAR范式的双重加持,作者将模型参数量扩展到超过100亿,在MS-COCO和GenEval数据集上取得领先结果。
更重要的是,随着参数量和训练轮数的增加,模型在验证损失、FID、GenEval Score等指标上表现出良好的可扩展性,为进一步扩大规模提供了理论支撑。这与语言模型的Scaling现象非常类似,表明视觉大模型的潜力尚未被充分挖掘。

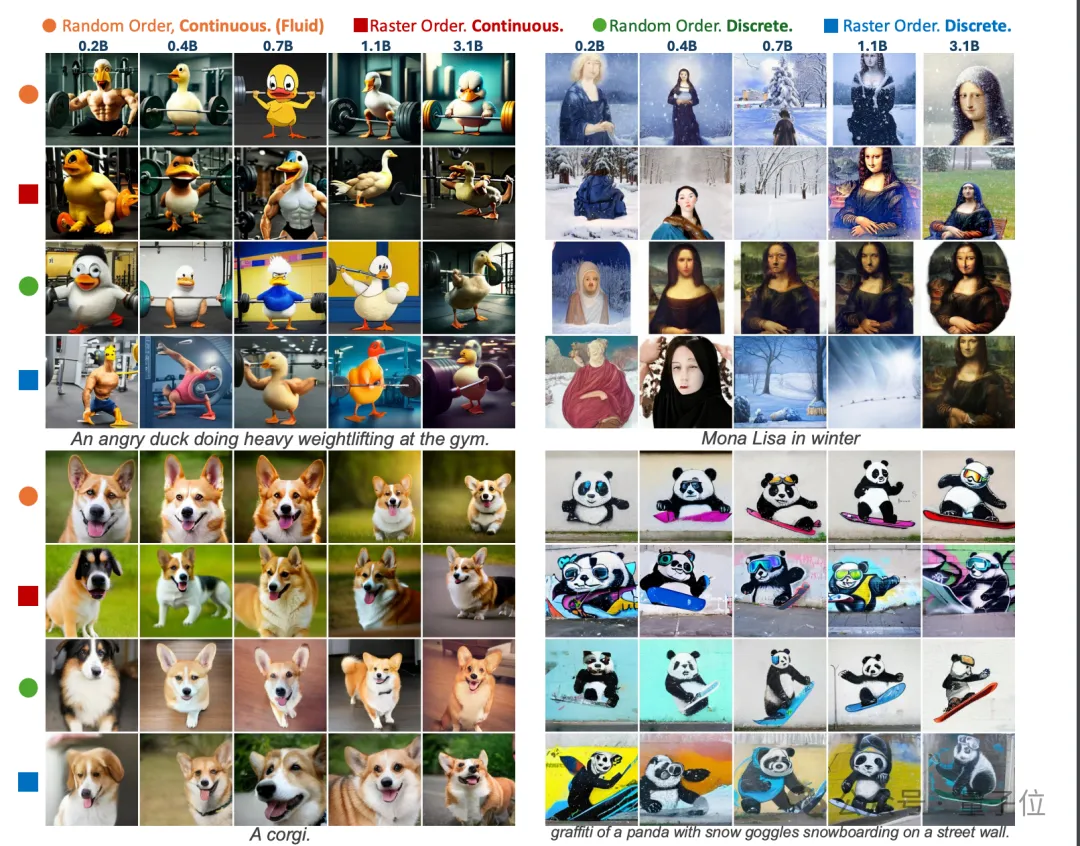
更多Fuild模型生成图像精选:

论文地址:
https://arxiv.org/abs/2410.13863v1
文章来自于微信公众号“量子位”,作者“梦晨”




【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
