
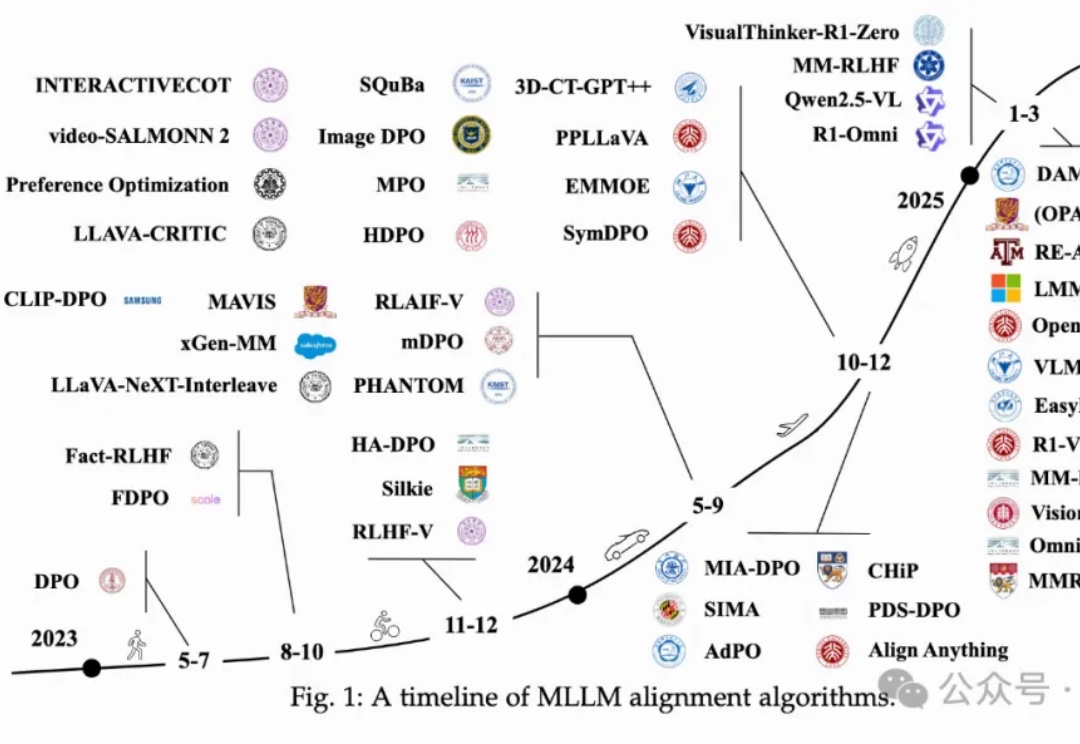
院士领衔万字长文,全面系统梳理多模态LLM对齐算法
院士领衔万字长文,全面系统梳理多模态LLM对齐算法万字长文,对多模态LLM中对齐算法进行全面系统性回顾!
来自主题: AI技术研报
10682 点击 2025-03-24 09:41
万字长文,对多模态LLM中对齐算法进行全面系统性回顾!

在人工智能领域的发展过程中,对大语言模型(LLM)的控制与指导始终是核心挑战之一,旨在确保这些模型既强大又安全地服务于人类社会。早期的努力集中于通过人类反馈的强化学习方法(RLHF)来管理这些模型,成效显著,标志着向更加人性化 AI 迈出的关键一步。

在线和离线对齐算法的性能差距根源何在?DeepMind实证剖析出炉