
OpenAI突宣开源计划:端侧模型or小模型二选一!奥特曼在线征集投票
OpenAI突宣开源计划:端侧模型or小模型二选一!奥特曼在线征集投票就在刚刚,奥特曼发了个推特,轻描淡写透露了个大消息: For our next open source project……
来自主题: AI资讯
12347 点击 2025-02-18 15:23
 搜索
搜索
就在刚刚,奥特曼发了个推特,轻描淡写透露了个大消息: For our next open source project……
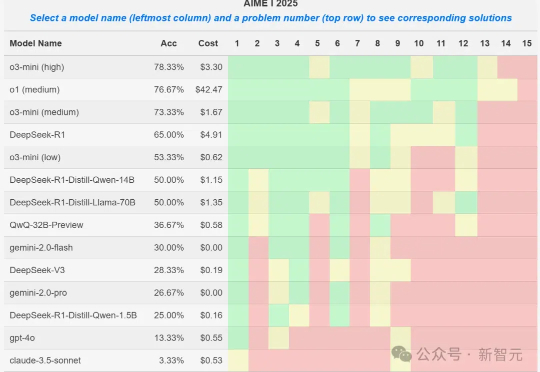
就在刚刚,AIME 2025 I数学竞赛的大模型参赛结果出炉,o3-mini取得78%的最好成绩,DeepSeek R1拿到了65%,取得第四名。然而一位教授却发现,某些1.5B小模型竟也能拿到50%,莫非真的存在数据集污染?

检索增强生成(RAG)虽好,但一直面临着资源消耗大、部署复杂等技术壁垒。近日,香港大学黄超教授团队提出MiniRAG,成功将RAG技术的应用门槛降至1.5B参数规模,实现了算力需求的大幅降低。这一突破性成果不仅为边缘计算设备注入新活力,更开启了基于小模型轻量级RAG的探索。

非营利研究机构AI2近日推出的完全开放模型OLMo 2,在同等大小模型中取得了最优性能,且该模型不止开放权重,还十分大方地公开了训练数据和方法。
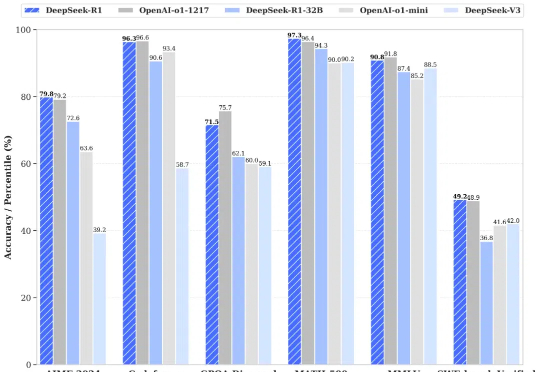
昨天晚上,DeepSeek 又开源了 DeepSeek-R1 模型(后简称 R1),再次炸翻了中美互联网: R1 遵循 MIT License,允许用户通过蒸馏技术借助 R1 训练其他模型。 R1 上线 API,对用户开放思维链输出 R1 在数学、代码、自然语言推理等任务上,性能比肩 OpenAI o1 正式版,小模型则超越 OpenAI o1-mini

最近几个月,从各路媒体、AI 社区到广大网民都在关注 OpenAI 下一代大模型「GPT-5」的进展。

还在为部署RAG系统的庞大体积和高性能门槛困扰吗?港大黄超教授团队最新推出的轻量级MiniRAG框架很好地解决了这一问题。通过优化架构设计,MiniRAG使得1.5B级别的小模型也能高效完成RAG任务,为端侧AI部署提供了更多可能性。
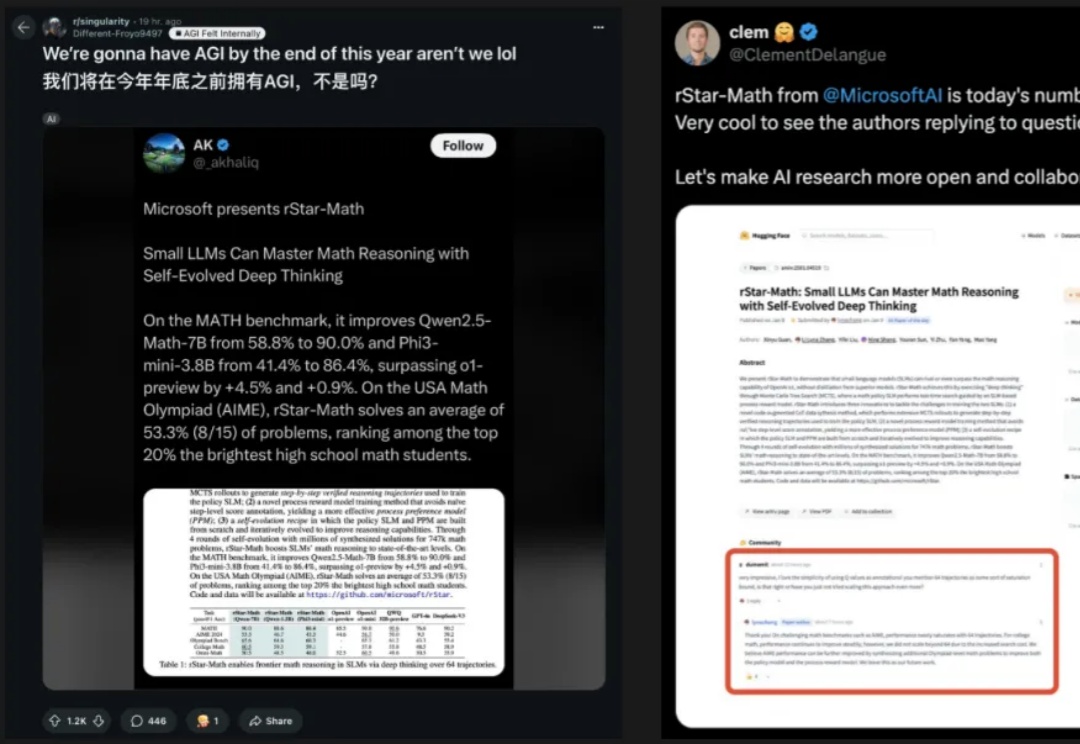
小模型也能击败o1?微软全华人团队提出rStar-Math算法,三大革命性技术突破,不仅让SLM在数学推理能力上刷新SOTA,更是挤进了全美20%顶尖高中生榜单。

放弃AGI,转向更好落地的小模型,李开复要带零一万物做“能赚钱的创新”。

大厂为什么追求大模型? 昨天有提到,为什么要研究语言模型。