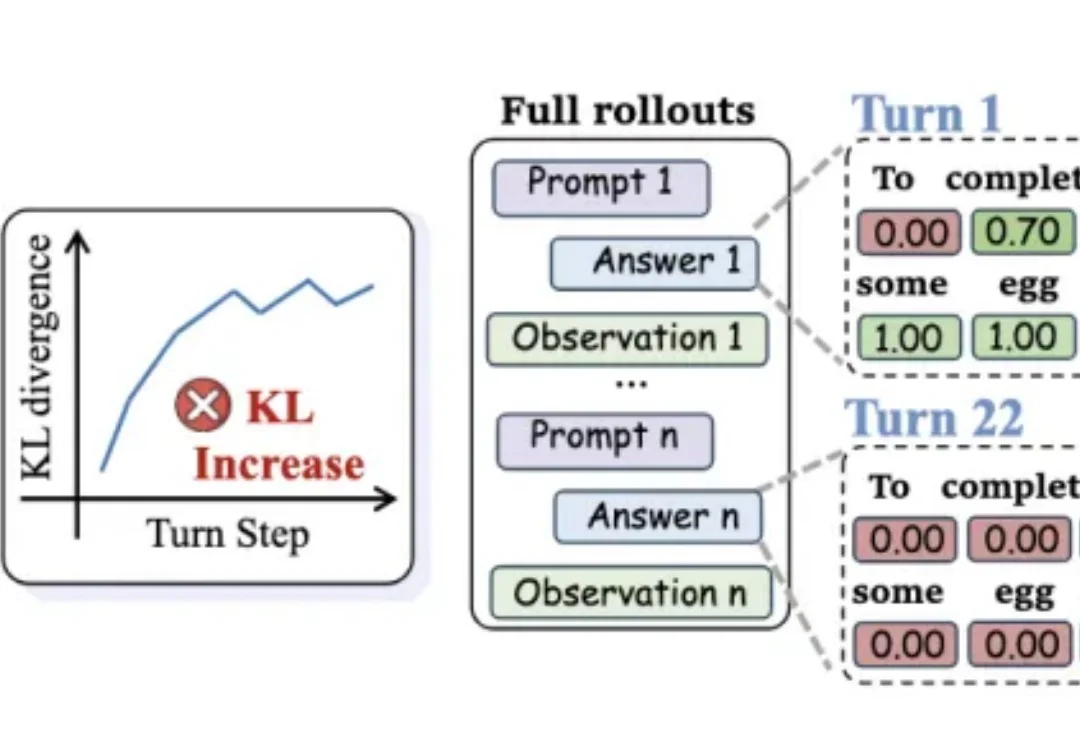
多轮Agent蒸馏终于不翻车!港中文x通义新方法成功率暴涨18点,训练还快32%
多轮Agent蒸馏终于不翻车!港中文x通义新方法成功率暴涨18点,训练还快32%把强大模型的能力“蒸馏”给小模型,听起来很美—— 但放到多轮对话Agent场景里,效果往往一塌糊涂。
来自主题: AI技术研报
8822 点击 2026-05-07 10:17
 搜索
搜索
把强大模型的能力“蒸馏”给小模型,听起来很美—— 但放到多轮对话Agent场景里,效果往往一塌糊涂。

大模型时代的「炼金术师」们,或许都曾面临一个共同的困扰:当我们试图将 DeepSeek-R1、OpenAI-o1 那种惊艳的推理能力迁移到小规模语言模型(SLMs)时,效果却总是差强人意。现有的强化学习方法如 GRPO 在 7B+ 的大模型上效果显著,但一旦应用到 1.7B 甚至更小参数的模型上,性能提升就微乎其微。
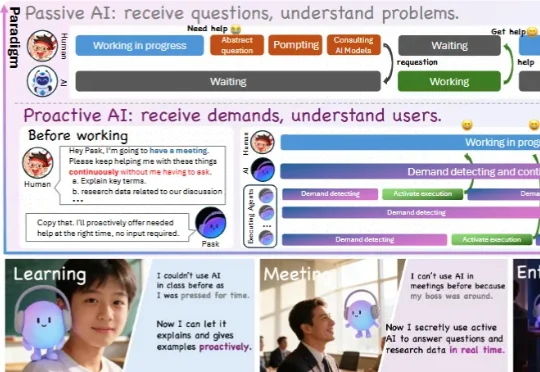
让AI像助手一样主动帮助,才是我们心中AGI的样子。主动智能体的概念已经被多次提出,但都很难做到可以真正在生活中落地。现有的工作都还停留在概念层面,无法解决复杂世界中所要求的实时性、深度、和记忆等问题。 南洋理工大学谢之非团队提出Pask,使用「底层小模型流式意图检测」+ 「上层Agents执行」架构,实现首个能够做到实时、有深度、基于个人全局记忆自进化的主动智能体。

先说一个很多人没意识到的事实:2026年了,每个主流Agent框架底下的工具调用训练数据,格式全是乱的。

浙江大学联合美团龙猫团队、清华大学推出全新研究成果——SKILL0,并提出技能内化(Skill Internalization)——小模型真正需要的,或许不是推理时的“外挂技能”,而是将技能内化为本能。

近日,上海人工智能实验室联合南京大学、香港中文大学及上海交通大学,将OpenClaw的成功应用于多模态生成领域。他们提出GEMS(Agent-Native Multimodal Generation with Memory and Skills),激发小模型潜力,甚至让6B小模型在部分任务超越了Nano Banana 2。

面壁智能2B小模型VoxCPM 2惊艳开源,一众外国网友疯狂了!30种语言与9大方言它是信手拈来,复刻的贺炜激昂解说与徐志胜脱口秀,相似度简直直击灵魂。这哪是工具,分明是降维打击的生产力核武器!
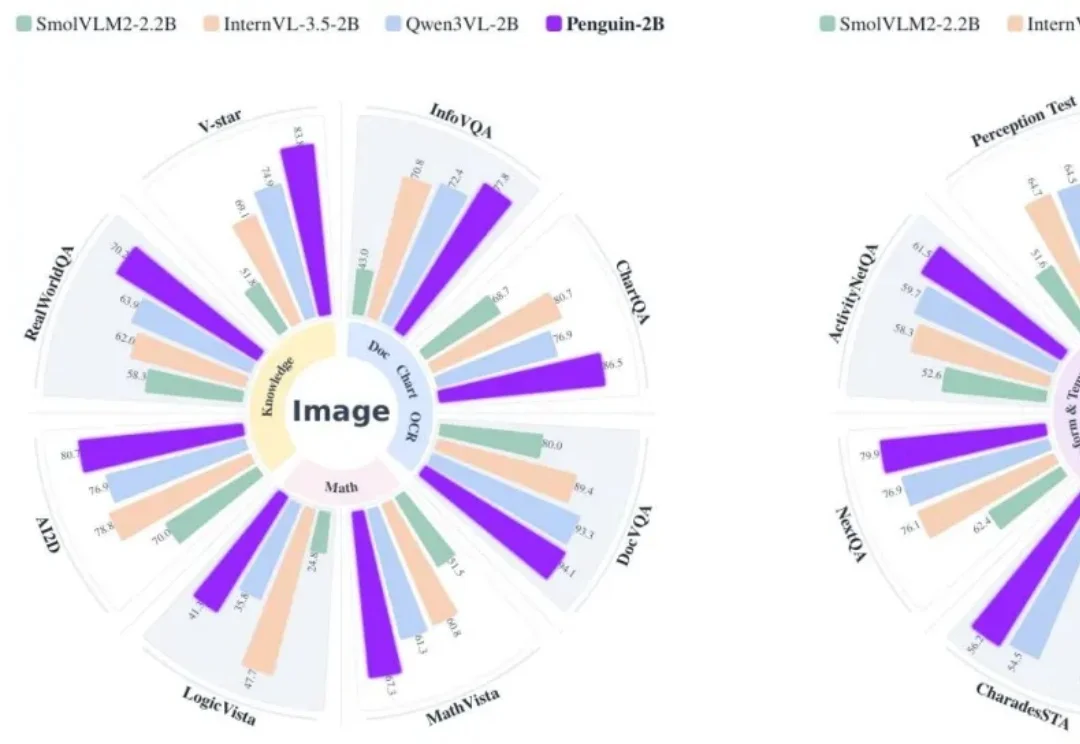
打破多模态视觉+语言拼接套路!
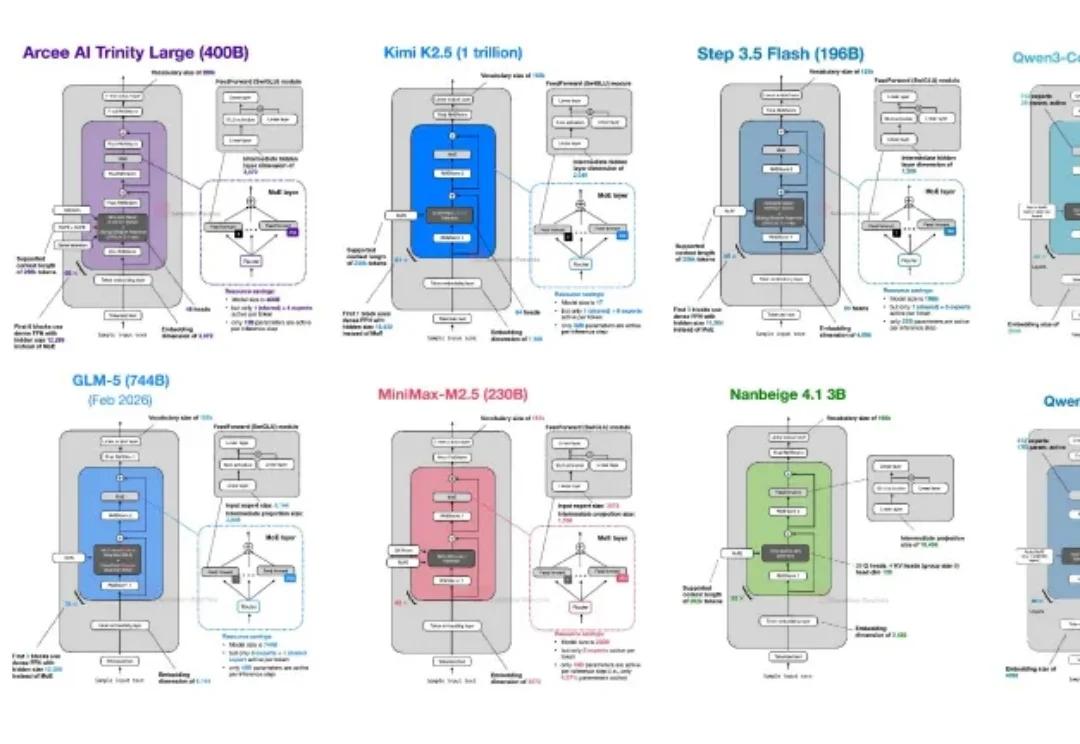
这两年,大模型大厂之间堪比军备竞赛。不论开源还是闭源阵营,为了在指标上领先对手,都在疯狂地卷 Scaling Law,卷算力,卷参数量,已经达到了近乎离谱的程度。
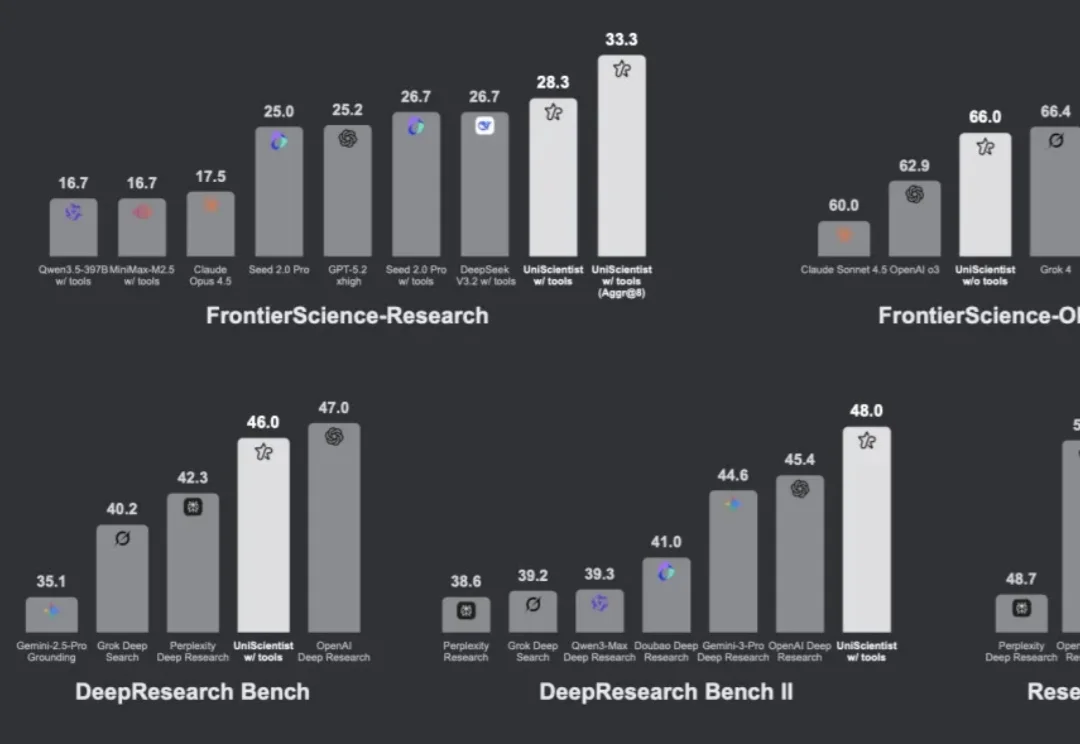
多数大模型能生成 “看起来像” 研究的文本,但极少数能真正做研究 —— 提出假设、收集证据、执行可复现的推导、迭代验证直至结论成立。