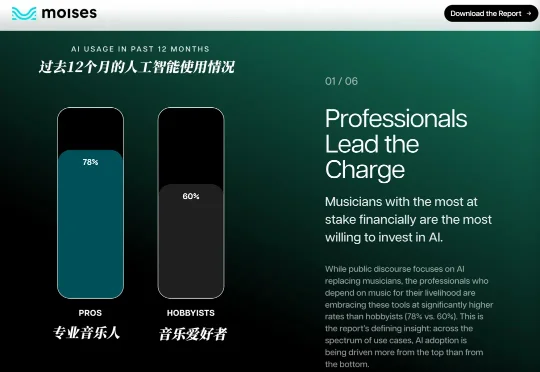
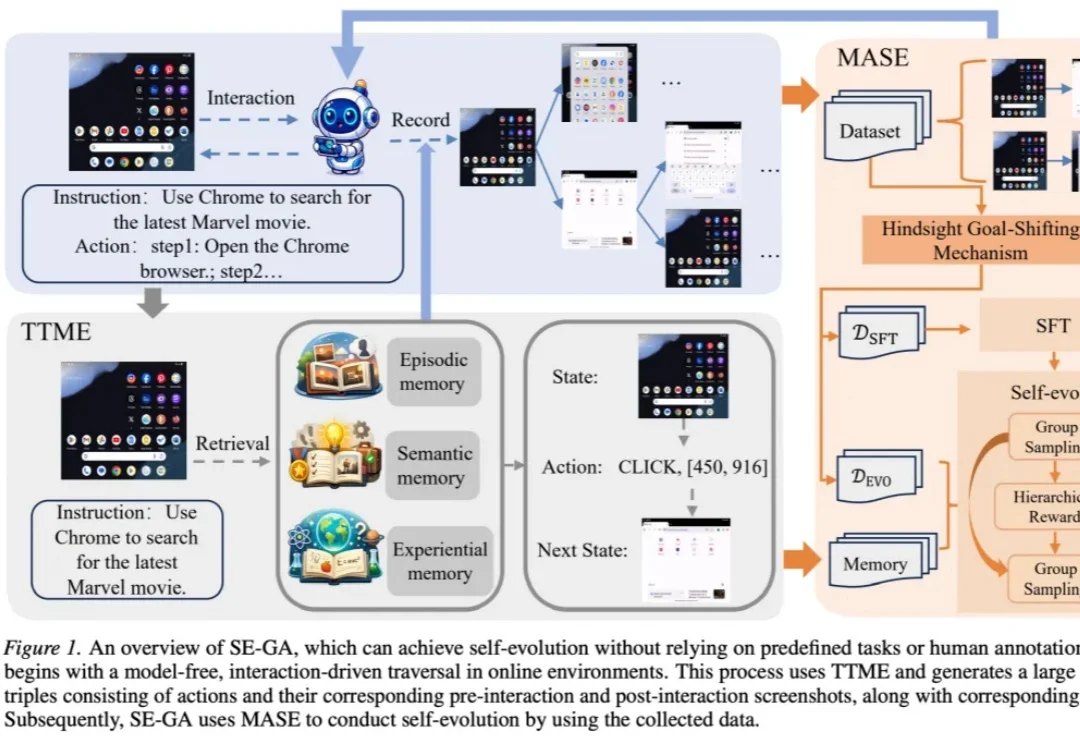
任务成本仅为Claude Opus 4.6 1/9,阶跃Step 3.7 Flash刷新Flash模型效率
任务成本仅为Claude Opus 4.6 1/9,阶跃Step 3.7 Flash刷新Flash模型效率1492 年,哥伦布驶向大西洋深处。远洋航行当然需要速度,但真正决定船队能否抵达彼岸的,是淡水、食物、船体、桅杆和帆索能否撑过漫长风暴。改写跨洋贸易的,正是这种并不浪漫的工程逻辑。 后来,荷兰人设计出
来自主题: AI资讯
9582 点击 2026-06-02 11:58